运用jieba库进行词频统计
Posted mindf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运用jieba库进行词频统计相关的知识,希望对你有一定的参考价值。
Python第三方库jieba(中文分词)
一、概述
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
二、安装说明
全自动安装:(cmd命令行) pip install jieba
安装成功显示
三、特点 —— jieba分词
1. 原理:jieba分词依靠中文词库
- 利用一个中文词库,确定中文字符之间的关联概率
- 中文字符间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
2. 三种分词模式:
- 精确模式:试图将句子最精确地切开,不存在冗余单词,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,有冗余,不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
四、jieba库常用函数
1. jieba.lcut(s) #精确模式,返回一个列表类型的分词结果
代码示例
jieba.lcut("中国是一个伟大的国家")
结果输出: [‘中国‘, ‘是‘, ‘一个‘, ‘伟大‘, ‘的‘, ‘国家‘]
2. jieba.lcut(s, cut_all=True) #全模式,返回一个列表类型的分词结果,存在冗余
代码示例
jieba.lcut("中国是一个伟大的国家",cut_all=True)
结果输出: [‘中国‘, ‘国是‘, ‘一个‘, ‘伟大‘, ‘的‘, ‘国家‘]
3. jieba.lcut_for_sear ch(s) #搜索引擎模式,返回一个列表类型的分词结果,存在冗余
代码示例
jieba.lcut_for_search(“中华人民共和国是伟大的")
结果输出: [‘中华‘, ‘华人‘, ‘人民‘, ‘共和‘, ‘共和国‘, ‘中华人民共 和国‘, ‘是‘, ‘伟大‘, ‘的‘]
4. jieba.add_word(w) #向分词词典增加新词w
代码示例
jieba.add_word("蟒蛇语言")
运用jieba库进行词频统计
实例 —— 对西游记第一回进行词频统计
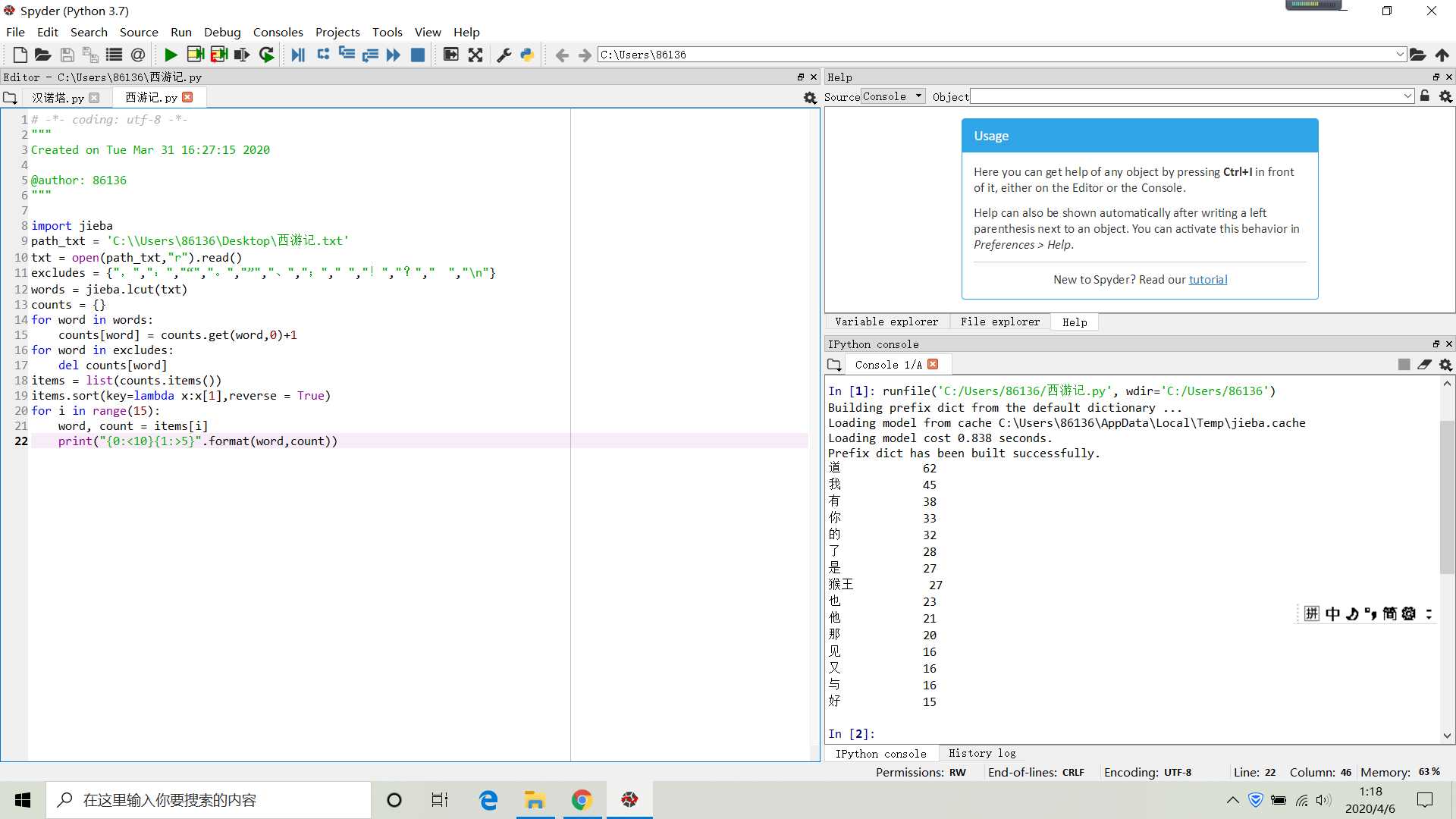
代码
import jieba path_txt = ‘C:Users86136Desktop西游记.txt‘ #文档在电脑上所在位置 txt = open(path_txt,"r").read() excludes = {",",":","“","。","”","、",";"," ","!","?"," "," "} words = jieba.lcut(txt) counts = {} for word in words: counts[word] = counts.get(word,0)+1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1],reverse = True) for i in range(15): word, count = items[i] print("{0:<10}{1:>5}".format(word,count))
结果
以上是关于运用jieba库进行词频统计的主要内容,如果未能解决你的问题,请参考以下文章