数据湖:什么是Hudi
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖:什么是Hudi相关的知识,希望对你有一定的参考价值。

https://bbs.csdn.net/forums/lanson https://bbs.csdn.net/forums/lanson
https://bbs.csdn.net/forums/lanson
文章目录
什么是Hudi
Apache Hudi是一个Data Lakes的开源方案,Hudi是Hadoop Updates and Incrementals的简写,它是由Uber开发并开源的Data Lakes解决方案。Hudi能够基于HDFS之上管理大型分析数据集,可以对数据进行插入、更新、增量消费等操作,主要目的是高效减少摄取过程中的数据延迟。
Hudi非常轻量级,可以作为lib与Spark、Flink进行集成,Hudi官网:
https://hudi.apache.orghttps://hudi.apache.org
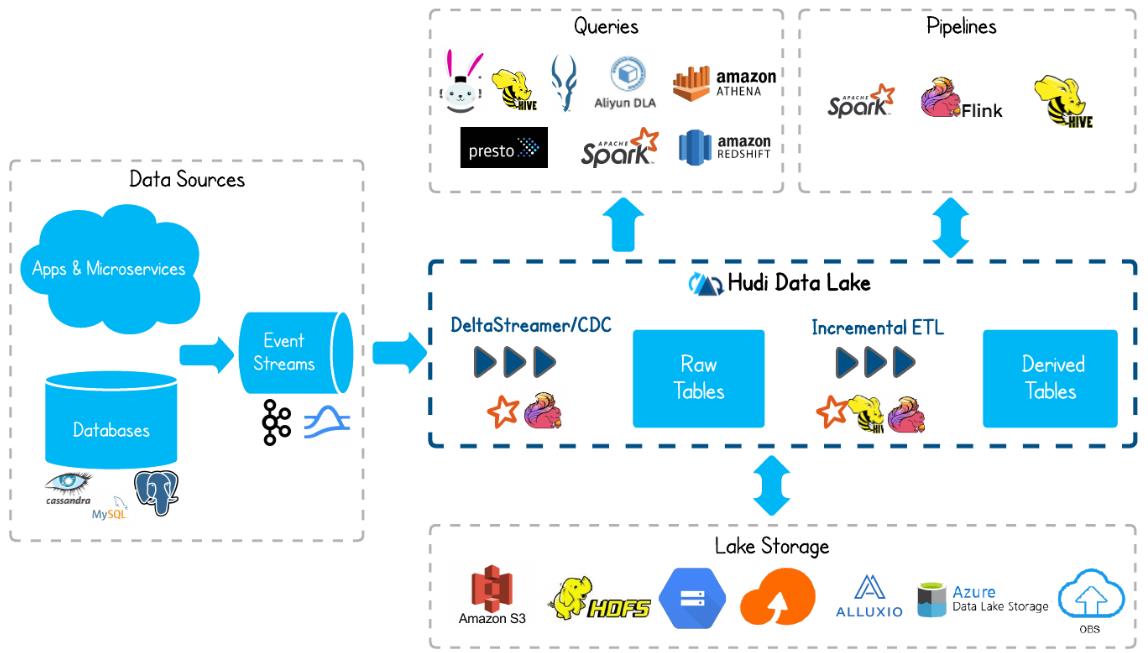
Hudi基于Parquet列式存储与Avro行式存储,同时避免创建小文件,实现高效率低延迟的数据访问。在HDFS数据集上提供插入更新、增量拉取、全量拉取。Hudi具有如下特点:
- 快速upsert,可插入索引。
- 以原子方式操作数据并具有回滚功能。
- 写入器和查询之间的快照隔离。
- 用于数据恢复的savepoint保存点。Hudi通过Savepoint来实现数据恢复。
- 管理文件大小,使用统计数据布局。
- 行和列数据的异步压缩。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于数据湖:什么是Hudi的主要内容,如果未能解决你的问题,请参考以下文章