Apache Hudi 数据湖概述
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Hudi 数据湖概述相关的知识,希望对你有一定的参考价值。
文章目录
前言
介绍本文之前,先给大家说一些简单的大数据概念。在大数据体系中,我们常用的存储是 HDFS(Hadoop Distributed File System),常用的计算是 map-reduce、spark、flink。对于 HDFS(Hadoop Distributed File System)而言,它是一个分布式的文件系统,数据平台的所有数据都存储在里面,最佳的使用实践是:一次写入,多次读取。所以大数据的计算基本上都是批处理计算(对有界的、确定数据范围的数据进行计算,不具备实时性),也就是 T-1 的计算,T+1 才能知道数据的计算结果(比如在前些年用户的银行转账,隔天才能收到)。但在互联网高速发展的今天,T+1 的数据结果已经无法满足用户的需求,大数据也需要做出一些变革。
归根结底,离线数仓无法支持实时业务的一个原因是不支持更新,或者说不支持高效的更新。旧的更新方式通常使用 overwrite 的方式来重写旧的数据,但耗时长、代价大。 大数据也有一些支持更新的组件如:
hbase,kudu。但这些方式要么是更新的代价较大,要么就是无法与大数据的计算引擎充分结合。但是近两年涌出的数据湖产品可以完美的解决大数据的更新问题,对于数据湖而言,更新并不是最主要的,它还支持数据库具备的ACID等特性,数据的历史镜像查询、数据的增量读取、savepoint等等。除此之外它更打通了和其它大数据计算引擎的结合,使得我们的数据有了统一的存储地方:数据湖1。
hudi是什么
Apache Hudi 是一个流式数据湖平台,支持对海量数据快速更新。内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具
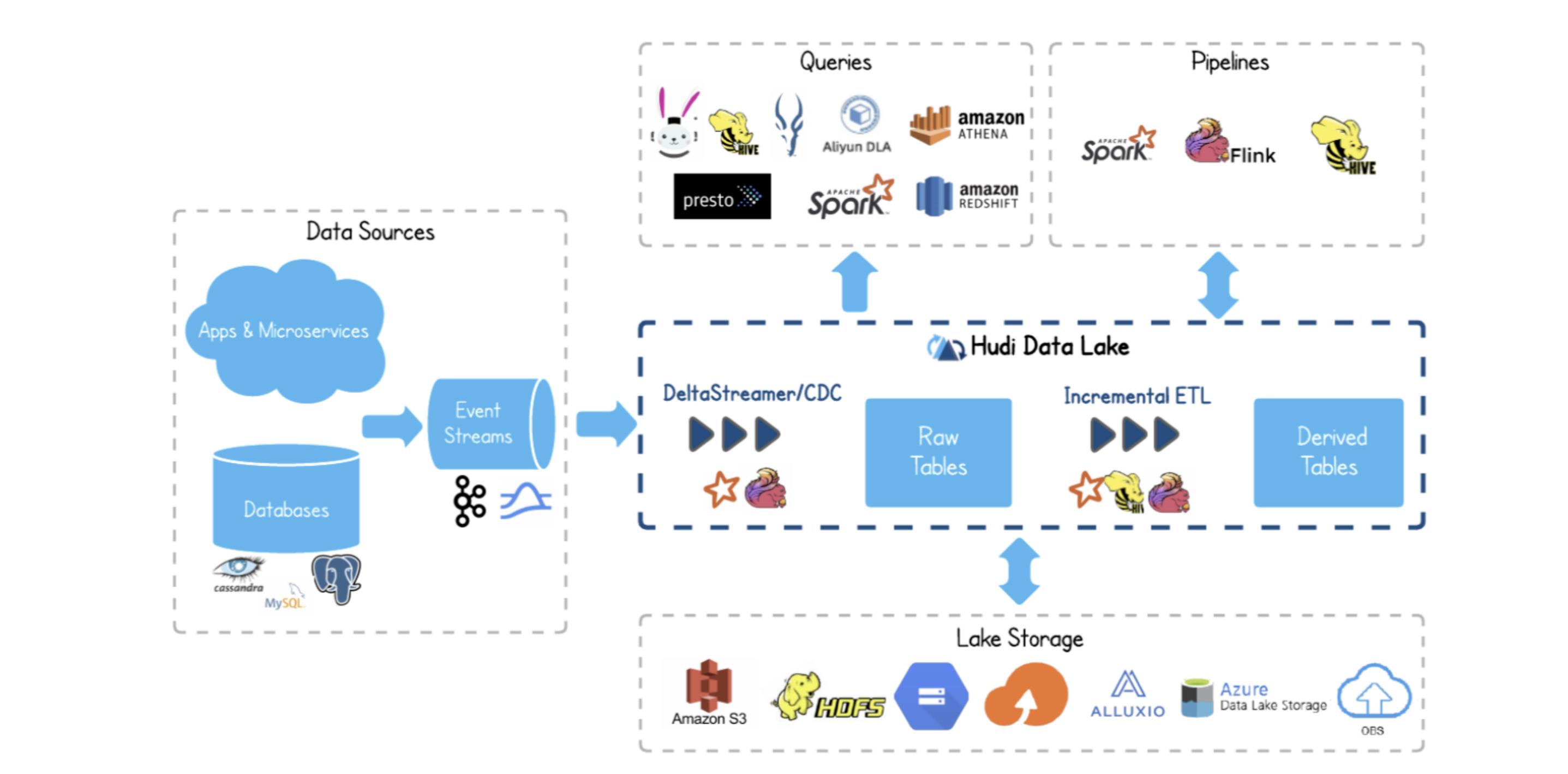
上图从下到上,由左向右看
hudi底层的数据可以存储到hdfs、s3、azure、alluxio等存储hudi可以使用spark/flink计算引擎来消费kafka、pulsar等消息队列的数据,而这些数据可能来源于app或者微服务的业务数据、日志数据,也可以是mysql等数据库的binlog日志数据spark/hudi首先将这些数据处理为hudi格式的row tables(原始表),然后这张原始表可以被Incremental ETL(增量处理)生成一张hudi格式的derived tables派生表hudi支持的查询引擎有:trino、hive、impala、spark、presto等- 支持
spark、flink、map-reduce等计算引擎继续对hudi的数据进行再次加工处理
上图信息总结一下:
- 支持大多数存储引擎
- 支持消费消息队列数据
- 支持多引擎查询分析
- 支持大数据的计算引擎
- 支持增量处理
hudi 实现更新的基本原理
在介绍之前,方便大家理解,大家可以先记住一个基本原理,hudi 数据的更新都是数据文件的追加。另外 hudi 根据不同数据更新方式划分了两种表格式,分别为 MOR(MERGE ON READ) 读时合并和 COW(COPY ON WRITE) 写时合并。通过名字大家可以简单理解下两种表格式,下面会介绍具体更新细节。
基础文件
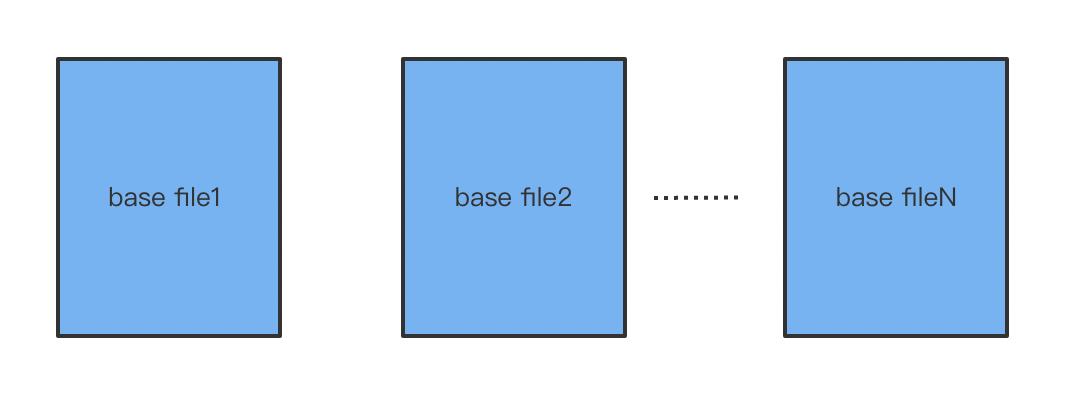
hudi 底层,将数据存储到基础文件中,该文件以 parquet、orc 等列存格式存放。该格式在大数据存储中被广泛使用,列裁剪2 谓词下推3等特性,对于数据的读取非常高效。
增量日志文件
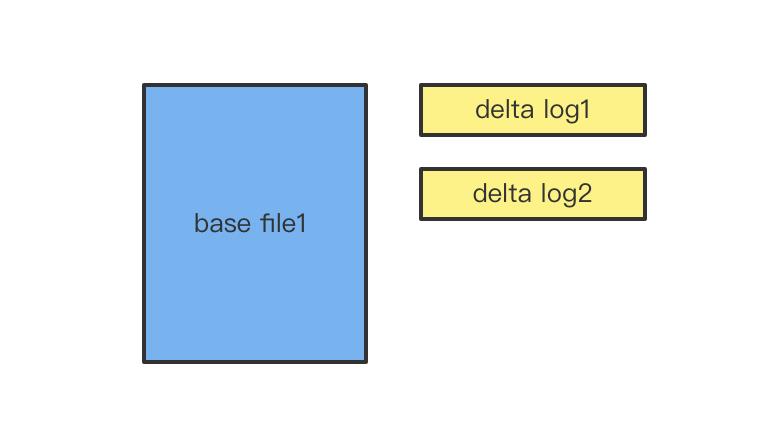
hudi 支持两种表格式,COW 和 MOR,在 MOR 格式中,更新的数据将被写入到增量日志文件(delta log)中。每次数据的更新,都会在对应的基础文件上追加一个增量日志文件。在数据被查询4时,hudi 将会实时合并基础文件和增量日志文件。
文件组
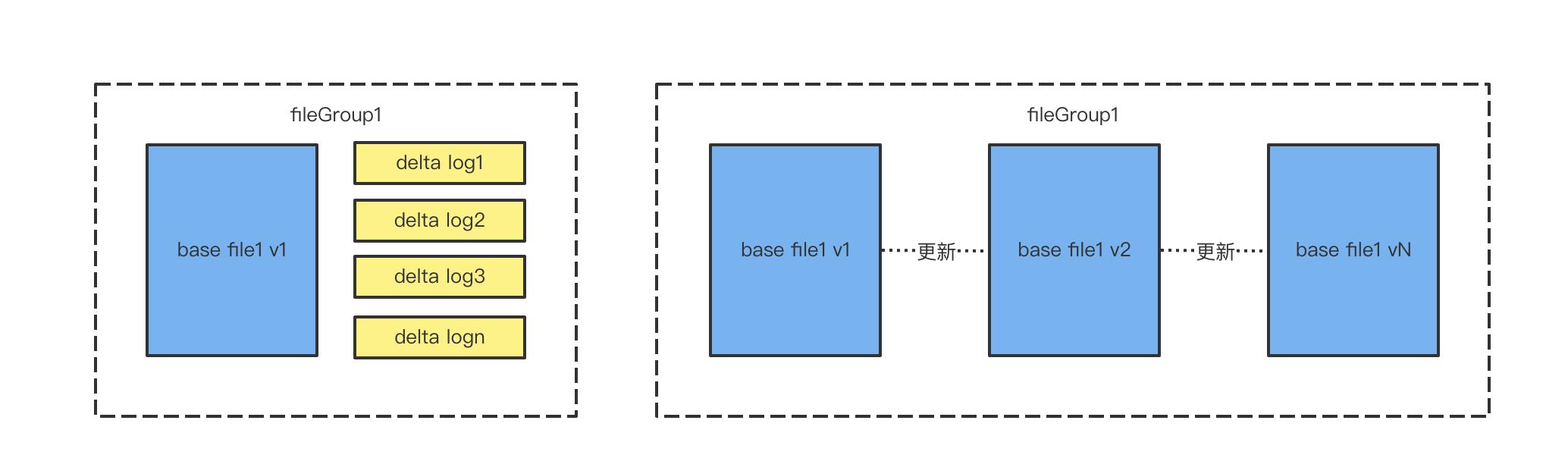
通常我们的数据在一个分区内会包含很多的基础文件和增量日志文件,每一个基础文件和在它之上的增量文件组成一个文件组。在 COW 格式中,只有基础文件,那么组成 fileGroup 文件就是:同一个文件的多次更新的基础文件的集合。
文件的版本
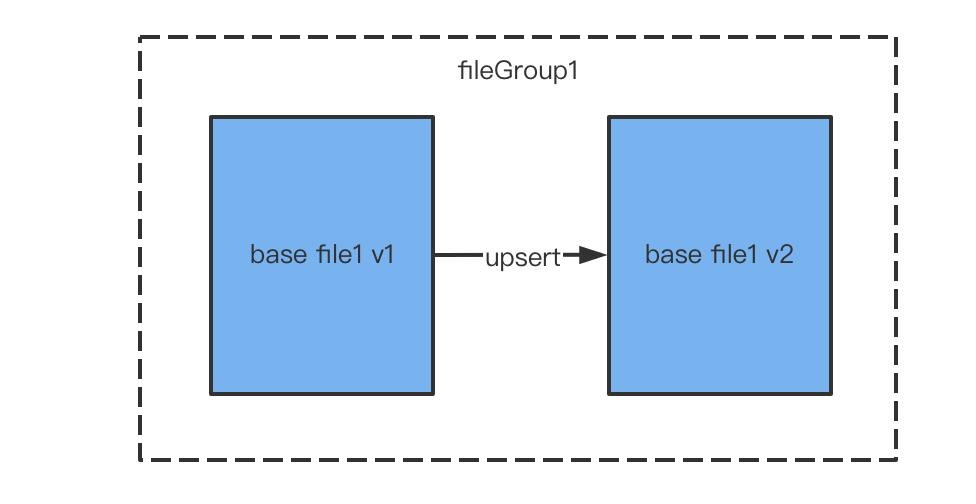
由于 hudi 数据的更新都是文件的更新,那么在更新后,会生成数据新的版本。上图展示的是在 COW 表格式下,数据的更新生成一个 V2 的基础文件,V2 的基础文件数据是增量数据和 V1 数据进行合并的结果。
COW表数据的更新
COW 格式下,hudi 在对一批数据进行更新时会通过索引查找数据所在的数据文件在哪里,如果找到就重写该文件,如果找不到将会新增文件5
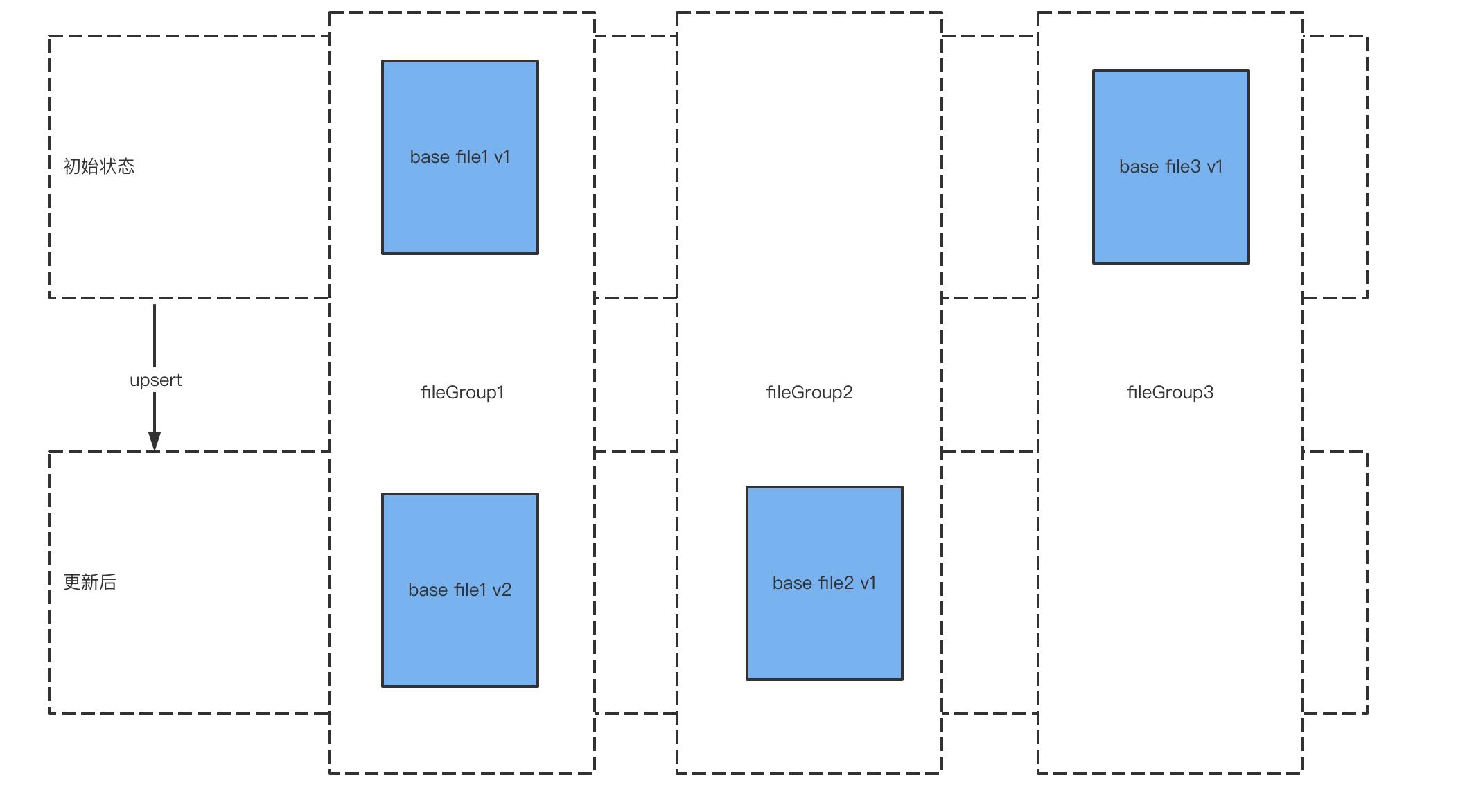
- 初始状态: 共有两个
fileGroup,fileGroup1和fileGroup3,基础数据文件只有base file1 v1和base file3 v1 - 更新后: 从更新后的状态我们可以看出,有对
fileGroup1进行了更新操作,基础文件的版本变成了v2。fileGroup2中新增了一个base file2 v1基础文件。fileGroup3没有进行数据的更新,也就没有文件的变化
COW表在对数据进行更新时,需要重写整个基础文件,即使我们只更新了该文件的一条数据,该表格式有写放大的缺点,但该表格式较为简单,少了MOR表格式的合并操作,对于频繁读的表比较推荐该格式
MOR表数据的更新
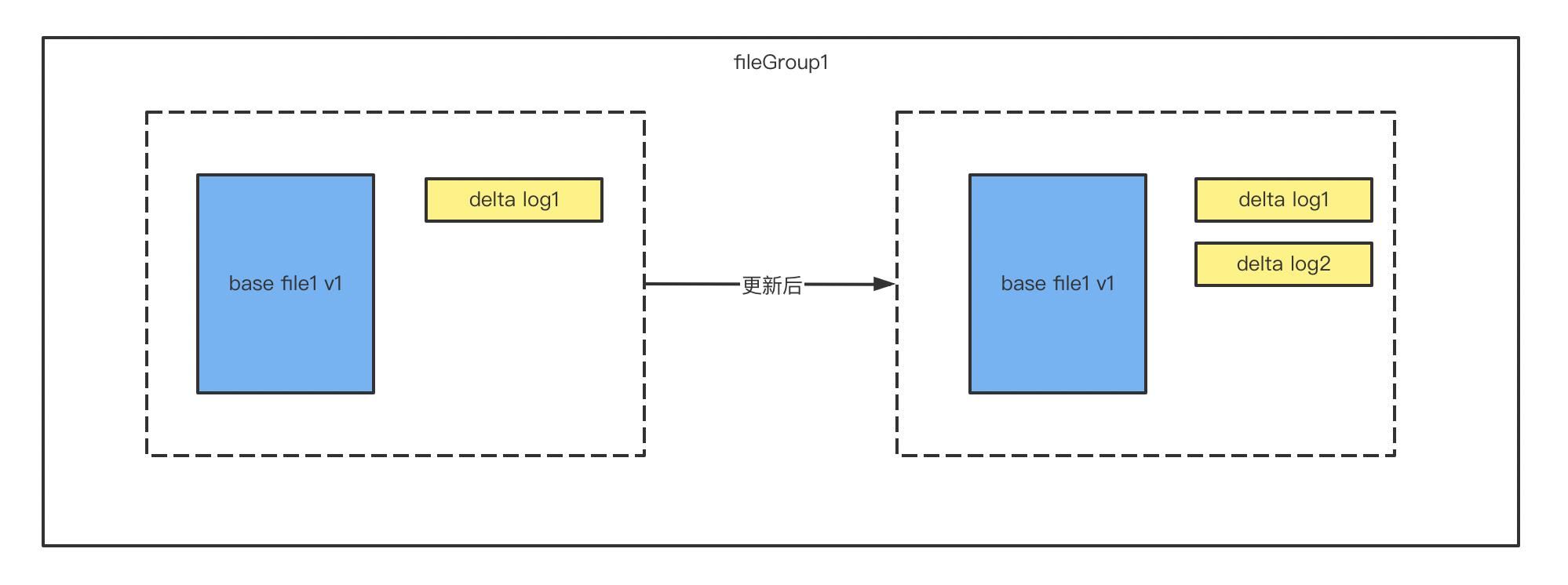
MOR 表和COW 表类似,在更新之前首先会使用索引来查找更新的数据文件位置,找到之后要更新的数据会在基础文件的基础之上新增一个 delta log 增量文件。如果没有找到,将会新增一个基础文件。
MOR 表的数据在读取时,会实时合并基础文件和增量文件返回给用户,如果增量文件较多,会导致查询数据结果较慢。
相比较 COW 表,MOR 的读取有非常明显的读放大,为了减少增量文件的数量,MOR 表需要定期的进行 compact 压缩操作。
MOR 表的compact
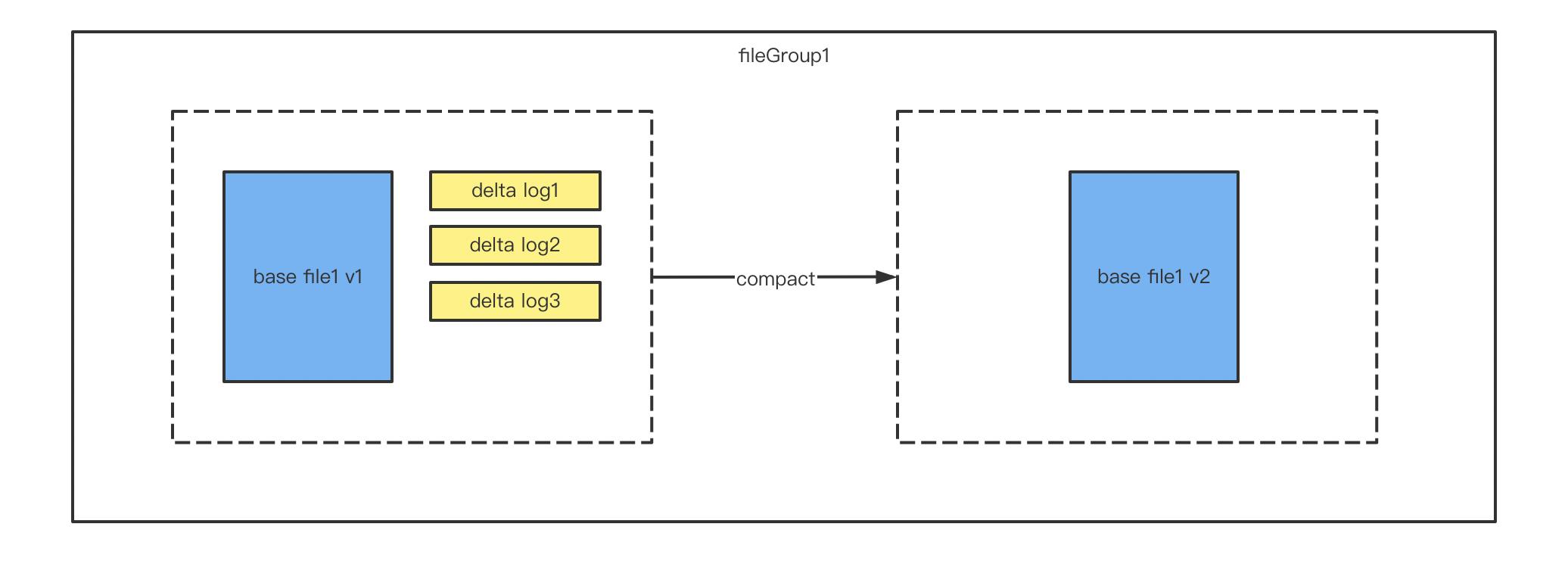
MOR 表 compact 是一个单独的操作,compact 时,hudi 首先读取所有的增量数据,并将其存到 map 中, 然后使用的生产者消费者模式进行数据的合并。生产者将会读取基础文件,然后将数据放入到内存队列,消费者消费队列的数据并和 map 中的增量数据进行对比来选择最新的数据。最后将所有数据写入到新的 v2 文件中。
hudi 不同表格式的读取方式
COW表数据的读取
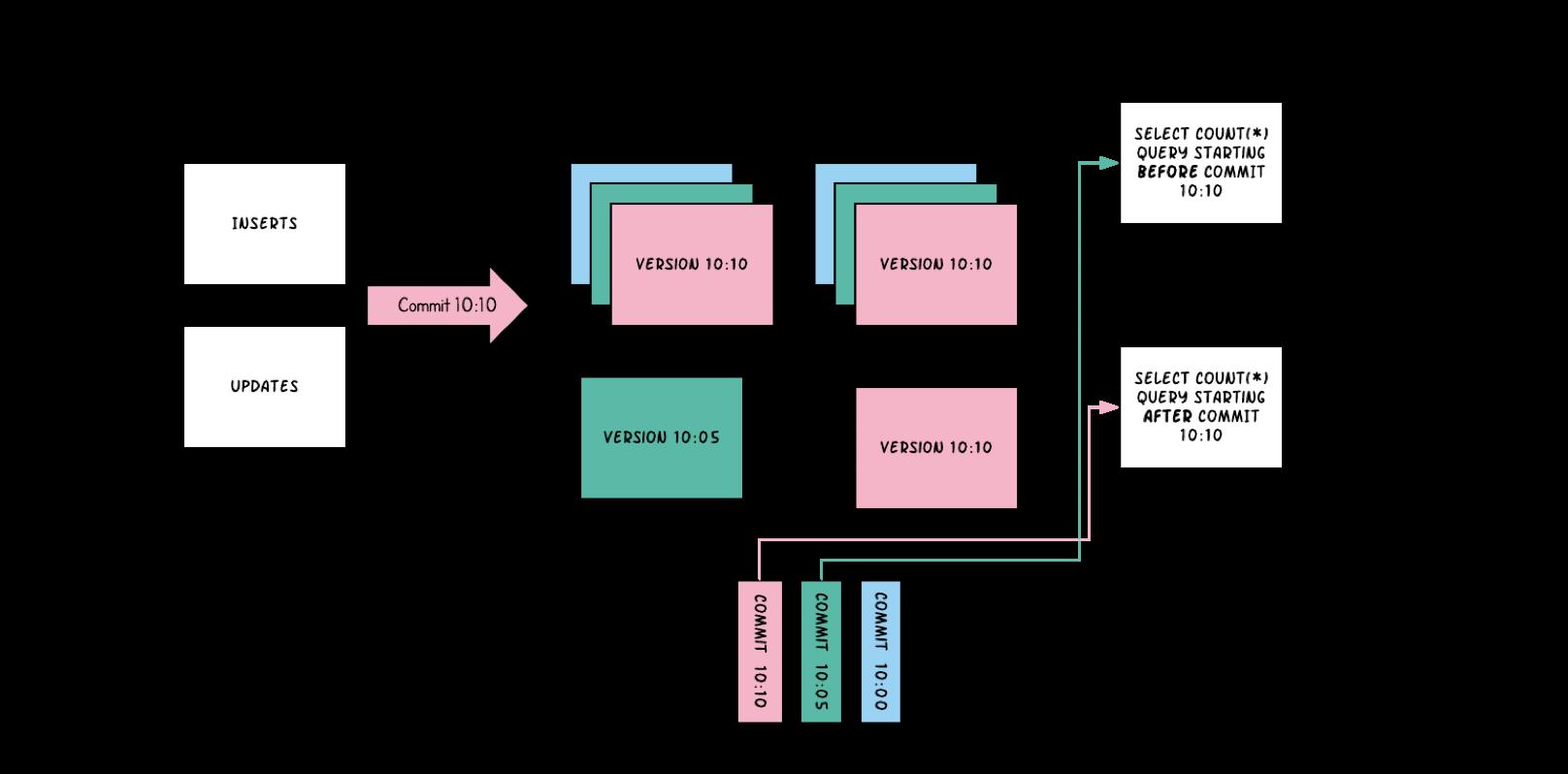
首先看下面的 timeline,在 10:00,10:05,10:10 三个时间时,hudi 提交了三次 commit。
10:00时,新增了两个基础文件fileid1和fileid210:05时,fileid1,fileid2,fileid3各有一份基础数据10:10时,进行了一次提交,对于基础文件fileid1、fileid2各更新了一个版本,fileid3没有进行数据的更新,新增了一个fileid4
对该 hudi 表进行查询时,分析下选择的基础文件有哪些。
- 如果我们执行的查询是
select count(*) QUERY STARTING AFTER COMMIT 10:10,也就是说我们要查询提交时间在10:10之后的数据量,那么此时我们会读取到10:10分对应的基础文件镜像。也就是fileid1 10:10的基础文件、fileid2 10:10的基础文件、fileid3 10:05的基础文件、fileid4 10:10的基础文件。 - 如果我们执行的查询是
select count(*) QUERY STARTING BEFORE COMMIT 10:10,也就是查询10:05时对应的基础文件镜像,此时扫描出来的基础文件有:fileid1 10:05的基础文件、fileid2 10:05的基础文件、fileid3 10:05的基础文件。
通过上面,大家应该可以看出来,
hudi实际上是通过MVCC来实现事务的隔离、不同时期镜像的读取。
MOR表数据的读取
在对 MOR 表数据读取时和 COW 表类似,只不过 MOR 表多了 RO 表和 RT 表。
RO 表又叫读优化表,在读取数据时只读取基础文件,此时会获得和 COW表相同的读取性能,但是缺点也很明显,无法读取到最新的增量数据。
RT 表又叫实时表,即读取数据时实时合并基础文件和增量日志文件,读取的数据较全,但是会耗费读取端较大的资源。
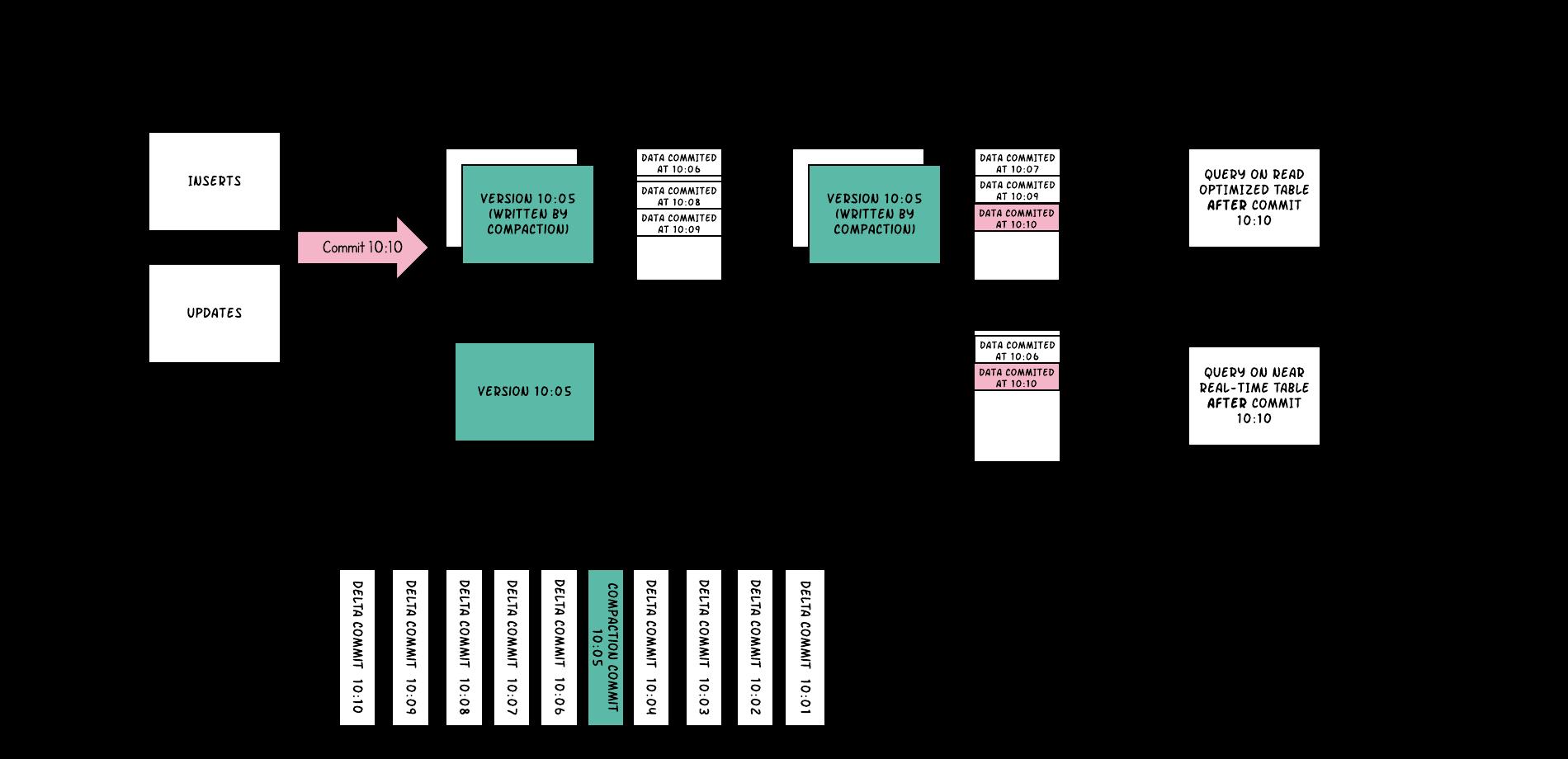
仍然先看图最下方的 timeline
10:01、10:02、10:03、10:04共四次的增量日志更新操作10:05进行了一次compact操作10:06、10:07、10:08、10:09、10:10四次增量日志更新操作
然后我们逐个分析
10:05时,进行了compact操作,将会合并之前的所有增量日志文件,合并后数据的基础文件有fileid1、fileid2、fileid310:06时对fileid1、fileid4进行了更新,各新增了一个10:06的增量日志文件10:07时对fileid2进行了更新,新增一个10:07的增量日志文件10:08时对fileid1进行了更新,新增一个10:08的增量日志文件10:09时对fileid1、fileid2进行了更新,各新增一个10:09的增量日志文件10:10时对fileid2、fileid4进行了更新,新增一个10:10的增量日志文件
然后在对数据读取时,如果我们执行的查询是QUERY ON READ OPTIMIZED TABLE AFTER COMMIT 10:10即读取 10:10 时的 RT 表,上面说了 RT 表只读区基础文件,此时扫描到的文件有: fileid1 10:05 的基础文件、fileid2 10:05 的基础文件、fileid3 10:05 的基础文件。
如果我们执行的查询是QUERY ON NEAR REAL-TIME TABLE AFTER COMMIT 10:10 即读取 10:10 时的 RT 表,该表会合并基础文件和增量日志文件,所以扫描到的数据文件有:( fileid1 10:05 的基础文件,10:06、10:08、10:09 的增量日志文件)、(fileid2 10:05 的基础文件,10:07、10:09、10:10 的增量日志文件)、fileid3 的基础文件、(fileid4 10:06、10:10 的增量日志文件)
不同表格式的特性

- 写入延迟:由于写入期间发生同步合并,与
MOR相比 ,COW具有更高的写入延迟 - 读取延迟:由于我们在
MOR中进行实时合并,因此与MOR相比COW往往具有更高的读取延迟。但是如果根据需求配置了合适的压缩策略,MOR可以很好地发挥作用 - 更新代价:由于我们为每批写入创建更新的数据文件,因此
COW的I/O成本将更高。由于更新进入增量日志文件,MOR的I/O成本非常低 - 写放大:假设有一个大小为
100Mb的数据文件,并且每次更新10%的记录进行4批写入,4次写入后,Hudi将拥有5个大小为100Mb的COW数据文件,总大小约500Mb。MOR的情况并非如此,由于更新进入日志文件,写入放大保持在最低限度。对于上面的例子,假设压缩还没有开始,在4次写入后,我们将有1x100Mb的文件和4个增量日志文件(10Mb) 的大小约140Mb
Hudi的应用
说了这么多,目前我们能运用 hudi 做什么呢?
mysql cdc
CDC 的全称是 Change Data Capture ,CDC 技术是数据库领域一个常用技术,主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术,可以把数据库表中数据的变化以实时或近实时通知到下游消费者。在数仓中,每天凌晨需要把业务库的业务数据同步到数仓中,来为下游 ETL的计算做数据准备。绝大多数公司都是使用数据集成工具(dataX、flinkX、sqoop)等来实现,但是这些方式都是使用SQL的方式如SELECT * FROM XX WHERE 1=1来全量抽取。此种方式给数据库带来了很大的压力,甚至会影响到业务。那么有没有一种优雅的方式呢?比如 binlog?
- 基于查询:这种
CDC技术是入侵式的,需要在数据源执行SQL语句。使用这种技术实现CDC会影响数据源的性能。通常需要扫描包含大量记录的整个表。 - 基于日志:这种
CDC技术是非侵入性的,不需要在数据源执行SQL语句。通过读取源数据库的日志文件以识别对源库表的创建、修改或删除数据
中间件团队目前已经对mysql的binlog进行了解析,我们只需要提交表的binlog监听申请,即可消费对应的kafka topic来消费数据。
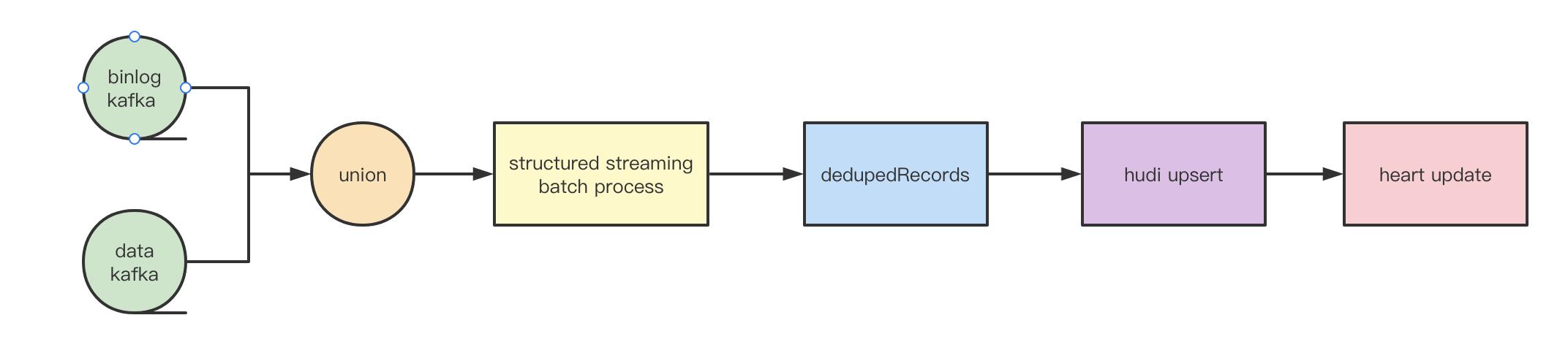
触发间隔:spark结构化流每15分钟一个批次,处理这段时间内产生的binlog消息并写入到数据湖。
去重方式:首选根据主键或者唯一键(支持多个)进行聚合,取gmt_modified最大的一条。考虑到在高并发等极端情况下会有同一时间修改同一条记录的情况,所以在gmt_modified相等的情况下,根据数据的offset大小比较6。
幂等:spark结构化流对于batch process仅仅支持at least once,但是在hudi upsert的特性下,实现了数据的幂等。
心跳:每批次增量数据更新完后,将会更新该表的心跳时间,如果在一定时间内心跳未更新,则数据可能有问题,此时任务将会告警,人工介入处理
通过这种方式我们可以近乎实时的捕捉mysql数据入湖,所有的数仓采集任务都从数据湖中拉取,将离线数仓和mysql解耦,对mysql无压力,节省从库高配置的费用,对业务不再有影响,并且任务抽取时间从之前到凌晨3点(错峰执行,避免对mysql实例较大的压力)提前到凌晨20分附近,缩短了9倍,下游任务计算提前近3个小时
分库数据查询
在使用 mysql 时,经常会遇到分库分表的数据查询比较困难,需要知道数据在哪个实例,哪个库,哪张表,查询较为复杂。如果把这些数据全部通过 CDC 同步到数据湖中,我们就可以在即席查询上直接查询这张表,不需要关心数据在哪里,数据湖会帮我们把这些分库分表的数据采集到同一张表中。
异常数据准实时分析
在业务场景中,我们会统计一些用户,或者设备的请求/上报数据的数量,比如最近 5 分钟的请求数量,当出现某些用户/设备的上报数据量异常时,简单分析后,手动对这些用户/设备进行降级。hudi 可以近实时的采集这些数据,然后开发在即席查询上查询异常设备SELECT COUNT(1) CNT,USER_ID FROM HUDI_TABLE GROUP BY USER_ID ORDER BY CNT DESC LIMIT 100,可以达到这种目的。
准实时图表绘制
由于前面我们通过 CDC 准实时的采集了 mysql 的业务数据,我们可以在离线开发平台上添加一些准实时的任务(每小时执行一次、每 30 分钟执行一次),准实时计算,最后将结果通过数据服务提供出去。
其实除了上面的这些,hudi 能做的很多,比如流批一体、湖仓一体、日志采集,篇幅有限,就不再叙述。
我更愿意称之为数据湖格式,
HDFS在大数据的地位不可动摇,数据湖底层的数据还是存储到HDFS之上。 ↩︎列式存储格式,在列裁剪生效时,只需扫描文件指定列即可,不需要读取当前文件的所有数据 ↩︎
列式存储格式,谓词下推生效时,通过读取
footer的元数据,比如该文件某列的最大值、最小值,可以快速判断要查询的数据是否在该基础文件 ↩︎MOR表分为RT读和RO读,在RT读时会合并基础文件和增量文件,但在RO读时,只读取基础文件,不会进行增量文件的合并,下文会介绍。 ↩︎方便大家理解,这里就写为新增文件,实际上
hudi会把插入的数据优先写入到文件较小的基础文件中,如果没有较小的基础文件才会创建一个新的文件。 ↩︎kafka发送binlog消息时,要保证同一个主键的数据发送到相同的partition,保证分区数据的有序性。 ↩︎
以上是关于Apache Hudi 数据湖概述的主要内容,如果未能解决你的问题,请参考以下文章