数据湖 Hudi 学习一
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖 Hudi 学习一相关的知识,希望对你有一定的参考价值。
一、Apache Hudi 基本介绍
Hudi是Hadoop Updates and Incrementals的简写,它是由Uber开发并开源的Data Lakes解决方案。Hudi 用于管理的数据库层上构建具有增量数据管道的流式数据湖,同时针对湖引擎和常规批处理进行了优化。简言之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。

二、发展历史
2015 年:发表了增量处理的核心思想/原则(O'reilly 文章)
2016 年:由 Uber 创建并为所有数据库/关键业务提供支持
2017 年:由 Uber 开源,并支撑 100PB 数据湖
2018 年:吸引大量使用者,并因云计算普及
2019 年:成为 ASF 孵化项目,并增加更多平台组件
2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍
2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
三、Huid 功能和特性
功能:
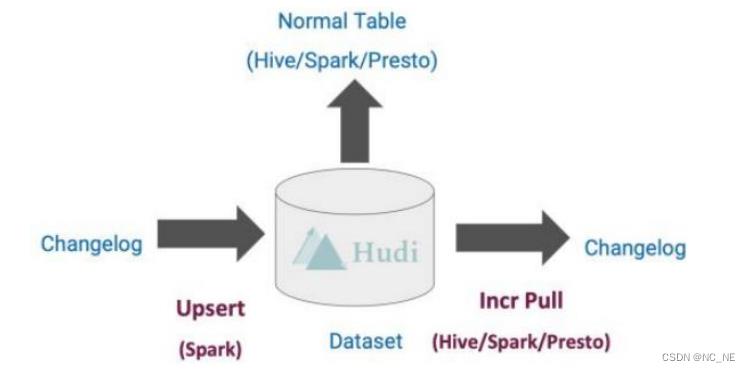
1、Hudi是在大数据存储上的一个数据集,可以将Change Logs通过upsert的方式合并进Hudi;
2、Hudi 对上可以暴露成一个普通Hive或Spark表,通过API或命令行可以获取到增量修改的信息,继续供下游消费;
3、Hudi 保管修改历史,可以做时间旅行或回退;
4、Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器;
特性:
1、Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
2、变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。

四、Hudi 基础架构

1、通过DeltaStreammer、Flink、Spark等工具,将数据摄取到数据湖存储。
2、支持 HDFS、S3、Azure、云等等作为数据湖的数据存储。
3、支持不同查询引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA。
4、支持 spark、flink、map-reduce 等计算引擎对 hudi 的数据进行读写操作。
五、小结
1. Apache Hudi 本身不存储数据,仅仅管理数据,借助外部存储引擎存储数据,比如HDFS、S3;
2. 此外,Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如Spark或Flink
以上是关于数据湖 Hudi 学习一的主要内容,如果未能解决你的问题,请参考以下文章
新一代流式数据湖平台 Apache Hudi学习笔记 - 基础知识&定义