数据湖 Hudi 学习二
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖 Hudi 学习二相关的知识,希望对你有一定的参考价值。
一、搭建执行hudi的平台
1.1、整体软件架构
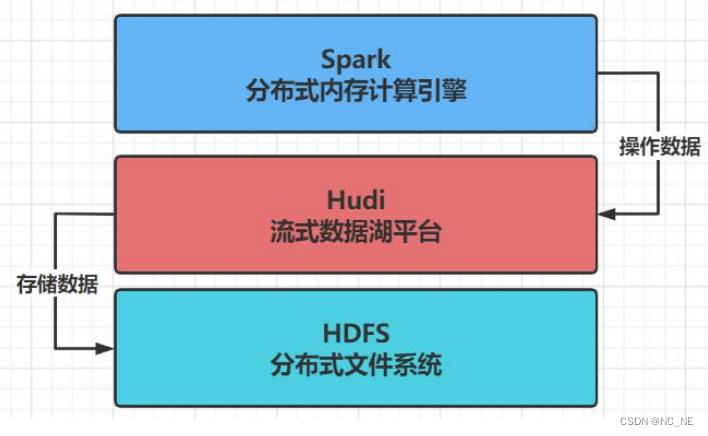
1.2、安装Hadoop(当前环境是hadoop2.7)............
1.3、安装 Spark(当前环境是3.x)
第一步、安装Scala-2.12.10
##解压scala
tar -zxvf scala-2.12.10.tgz -C /opt/module
##设置Scala的环境变量
vim /etc/profile
###添加如下
#SCALA_HOME
export SCALA_HOME=/opt/module/scala-2.12.10
export PATH=$PATH:$SCALA_HOME/bin查看Scala是否安装成功

第二步、修改spark的配置文件
##解压spark包spark-3.0.0-bin-hadoop2.7.tgz
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz -C /opt/module
##修改conf/spark-env.sh
##添加如下
JAVA_HOME=/opt/module/jdk1.8.0_144
SCALA_HOME=/opt/module/scala-2.12.10
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop第三步、本地模式启动spark-shell读取hdfs数据
bin/spark-shell local[2]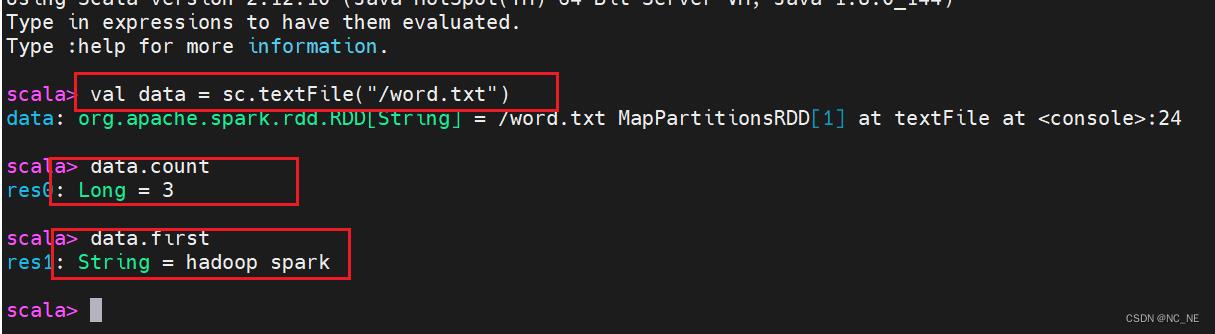
1.4、测试hudi-0.9.0
编译好的hudi下载
链接:https://pan.baidu.com/s/11hhmyZCiQxNRTv-ND_-Chw
提取码:bio5 ./hudi-cli.sh
二、先使用spark-shell操作Hudi
2.1、启动spark-shell携带hudi相关的jar
1)、联网下载模式启动(网好的可以使用)
jars包下载
链接:https://pan.baidu.com/s/1tcQ64wAib4llRLLGOWLtsg
提取码:dvvh hudi-spark3-bundle_2.12-0.9.0.jar 是编译huid的jar包,在packaging/hudi-spark-bundle/target路径下
spark-avro_2.12-3.0.1.jar 是hudi存储avro数据格式需要的jar包,spark里面没有bin/spark-shell \\
--master local[2] \\
--jars /opt/module/hudi-0.9.0/packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.9.0.jar \\
--packages org.apache.spark:spark-avro_2.12:3.0.1 \\
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"2)、通过--jars指定
将avro的jar包下载下来放到自定目录下即可,hudi编译的jar也都放到一起(方便)

bin/spark-shell \\
--master local[2] \\
--jars /opt/module/spark-3.0.0-bin-hadoop2.7/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar, \\
/opt/module/spark-3.0.0-bin-hadoop2.7/hudi-jars/spark-avro_2.12-3.0.1.jar\\
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"启动成功
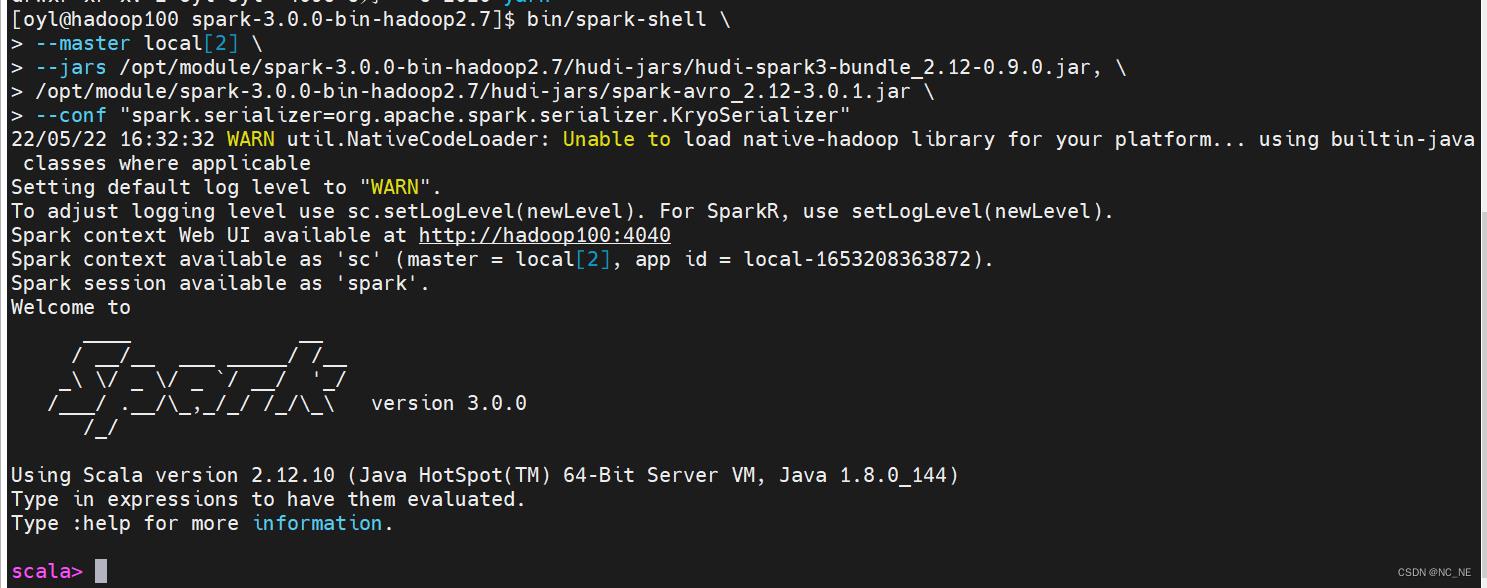
2.2、保存数据至Hudi表
1)、导入park及Hudi相关包
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._2)、定义变量(表的名称和数据存储路径,路径可以本地也可以hdfs)
##创建表名
val tableName = "hudi_trips_cow"
##指定数据存放路径(本地)
val basePath = "file:///tmp/hudi_trips_cow"
##指定数据存放路径(hdfs)
val basePath = "hdfs://192.168.0.154:8020/datas/hudi-warehouse/hudi_trips_cow"3)、模拟生成Trip乘车数据
##构建DataGenerator对象,用于模拟生成10条Trip乘车数据
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))数据格式
"ts": 1653124172267,
"uuid": "80ad40d1-95f8-4677-ad1c-6eee1eeb72dd",
"rider": "rider-213",
"driver": "driver-213",
"begin_lat": 0.4726905879569653,
"begin_lon": 0.46157858450465483,
"end_lat": 0.754803407008858,
"end_lon": 0.9671159942018241,
"fare": 34.158284716382845,
"partitionpath": "americas/brazil/sao_paulo"
4)、将模拟数据List转换为DataFrame数据集,查看数据
##转成df
val df = spark.read.json(spark.sparkContext.parallelize(inserts,2))
##查看数据结构
df.printSchems()
##查看数据
df.show()
5)、将数据写入到hudi
直接通过format指定数据源hudi,设置相关属性保存数据即可
df.write.format("hudi").
mode(Overwrite).
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
##
重要参数说明
参数:getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目
参数:PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段
参数:RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段
参数:PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段6)、HDFS数据结构(全是parquet格式)
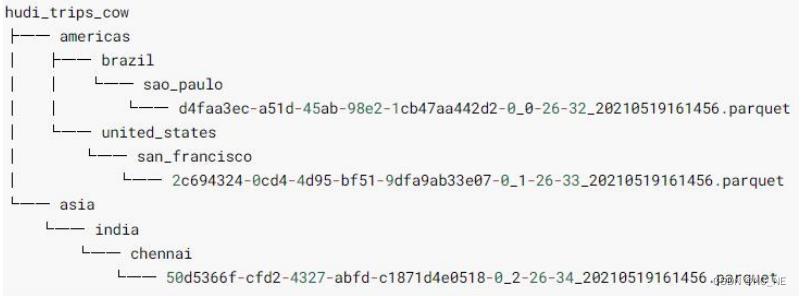
2.3、读取hudi表数据
1)、采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath + "/*/*/*/*")
##创建临时表
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
##参数说明
参数 /*/*/*/* 其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相当于Hive中表指定三个分区字段)2)、查询乘车费用 大于 20 信息数据
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()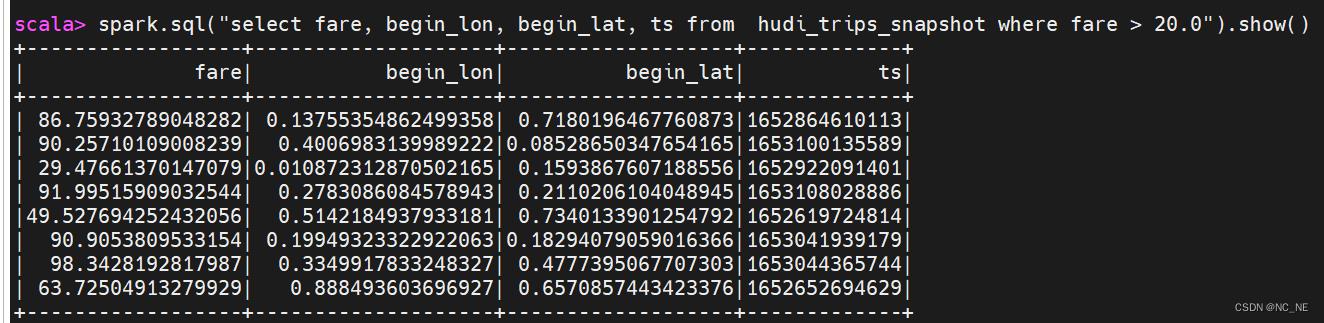 2.4、更新hudi表数据
2.4、更新hudi表数据
类似于插入新数据,用官方提供工具类DataGenerator模拟生成更新update数据
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
##参数说明
参数:Append 追加数据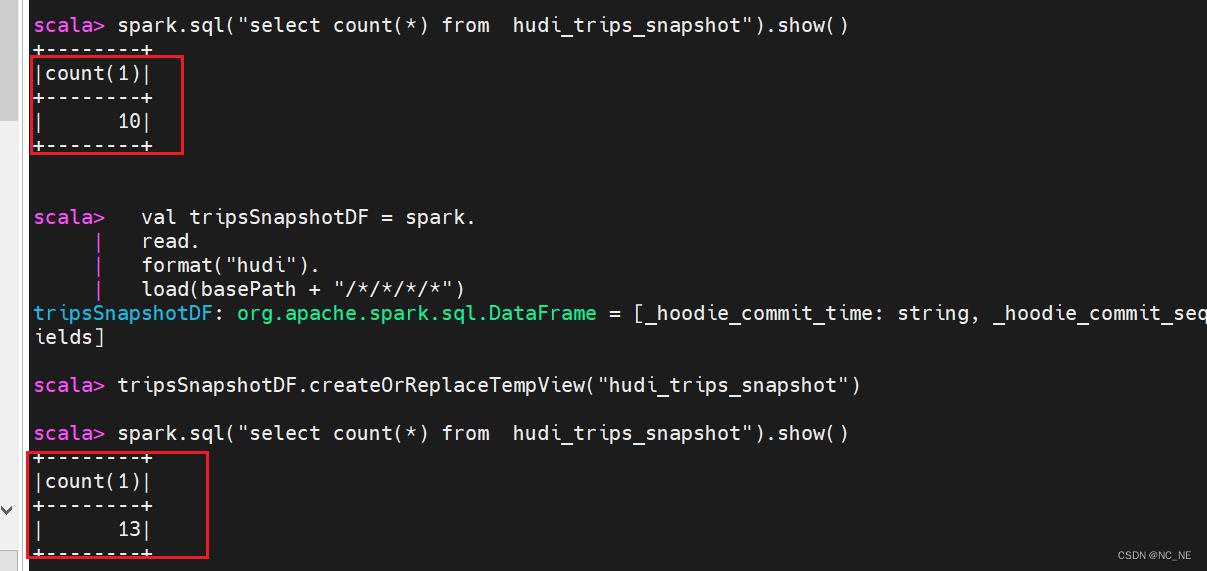
2.5、删除hudi表数据
1)、先从Hudi表获取2条数据,然后构建出删除数据格式
##查询数据总条数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
##获取2条数据,然后构建出数据格式
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2));2)、再重新保存到Hudi表
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
参数说明
参数:OPERATION_OPT_KEY,delete 删除数据(必须Append模式)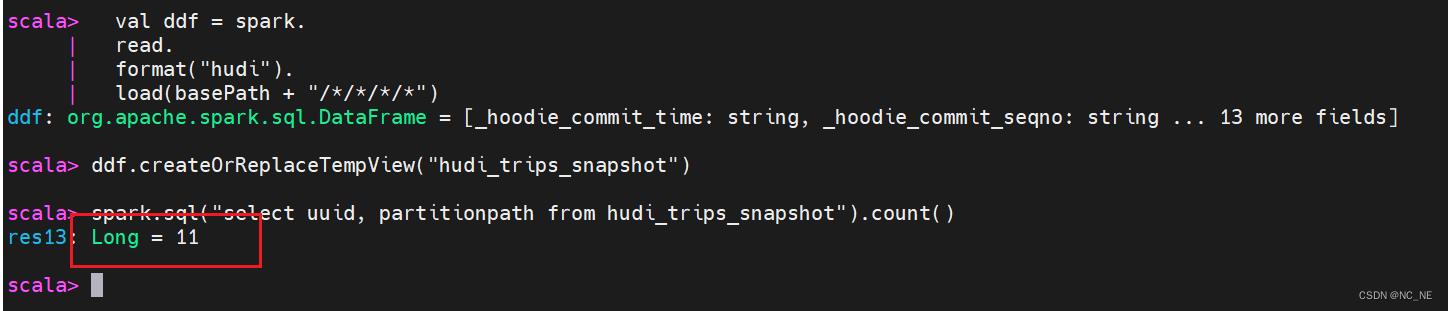
以上是关于数据湖 Hudi 学习二的主要内容,如果未能解决你的问题,请参考以下文章