极智AI | 多模态领域先行者 详解 CLIP 算法实现
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智AI | 多模态领域先行者 详解 CLIP 算法实现相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文详细介绍一下 CLIP 算法的设计与实现,包括代码。
多模态一定不是一个新鲜的话语,随着 AI 的发展,也正成为一种趋势,而 CLIP 做的就是在多模态领域里迈出了简单的一步,之所以说简单,是因为 CLIP 使用的方法出奇的简单,但效果又出奇的好。CLIP 具有非常好的迁移学习能力,预训练好的模型可以在任意一个视觉分类数据集上取得不错的效果,而且是 Zero-Shoot 的,意思是完全不需要再去这些数据集上做训练,就能得到这么好的结果。
本文不止会介绍 CLIP 的原理,还会介绍 CLIP 的实现,包括代码。下面开始。
参考 Paper:《Learning Transferable Visual Models From Natural Language Supervision》。
文章目录
1 CLIP 算法原理
CLIP 全称 Contrastive Language-Image Pre-training,具有十分强悍的迁移学习能力,为了佐证这个能力,在超过 30 多个视觉数据上进行测试,涵盖面十分广泛,包括 OCR、视频动作检测、坐标定位和许多细分类任务,在所有的结果中最炸裂的一条就是在 ImageNet 上的结果,CLIP 在不使用任意一张 ImageNet 图片训练的情况下,直接 Zero-Shoot 推理,就能获得跟之前有监督训练的 ResNet-50 同样优秀的结果。这在 CLIP 出来之前,很多人都认为这是不太可能的事情。说到这里,应该可以调足了大伙儿的口味了,下面讲讲 CLIP 到底是个啥。
回答 CLIP 是啥的最好的答案可能就是下面这张图。很直观,有三个阶段:
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 Zero-Shoot 推理预测;

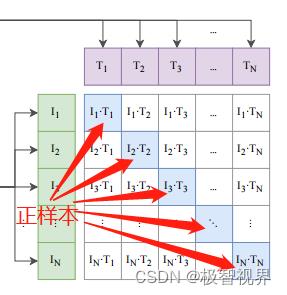
进行一些说明。在预训练阶段,对比学习十分灵活,你只需要定义好 正样本对 和 负样本对 就行了,其中能够配对的图片 - 文本对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成 I1、I2 … In 的特征向量,文本对应生成 T1、T2 … Tn 的特征向量,然后中间对角线为正样本,其余均为负样本。这样的话就形成了 n 个正样本,n^2 - n 个负样本,如下。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。当然,自监督的训练需要大量的数据,OPEN AI 的这个训练数据量大约在 4亿个 的数量级。
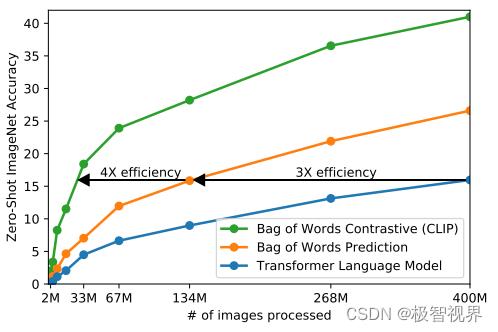
由于训练数据巨大,训练是个十分耗费时间的事情,所以必须对训练策略进行一些改进以提升训练效率。采用对比学习进行训练的一个重要原因也是考虑到 训练效率。来看图,最下面的蓝线表示像 GPT2 这种预测型的任务(预测型的任务是指,我有一张图片,去预测图片对应的描述,这个时候因为人类的语言是个奇妙又伟大的东西,一张图往往能对应出多种文本描述,比如 姚明篮球打得好 和 姚明真高,对于描述同一张图并不冲突),可以看到是最慢的。中间黄线是指一种 bag of words 的方式,不需要逐字逐句地去预测文本,文本已经抽象成特征,相应的约束也放宽了,这样做训练速度立马提高了 3 倍。接下来进一步放宽约束,不再去预测单词,而是去判断图片 - 文本对,也就是绿色的线 对比学习的方法,这样效率又可以一下提升至 4 倍。
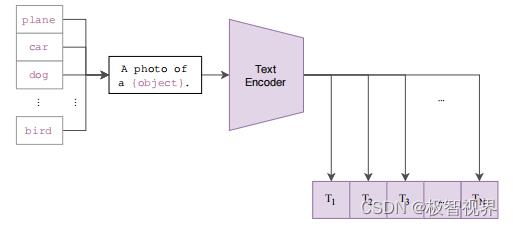
等训练好了,然后进入前向预测阶段。首先需要对文本类别进行一些处理,拿 ImageNet 数据集的 1000 个类别来说,原始的类别都是单词,而 CLIP 预训练时候的文本端出入的是个句子,这样一来为了统一就需要把单词构造成句子,怎么做呢?可以使用 A photo of a object. 的提示模板 (prompt template) 进行构造,比如对于 dog,就构造成 A photo of a dog.,然后再送入 Text Encoder 进行特征提取,就 ImageNet 而言就会得到一个 1000 维的特征向量,整个过程如下:
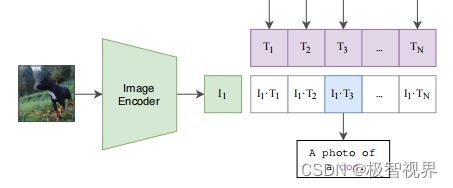
最后就是推理见证效果的时候,怎么做的呢。这个时候无论你来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 1000 个文本特征做余弦相似度对比,最相似的即为我们想要的那个结果,比如这里应该会得到 A photo of a dog.,整个过程如下:
流程应该上面说的比较清楚了,然后再说扩展性 / 泛化能力。上面是拿 ImageNet 那 1000 个类进行展示的,在实际使用中,这个类别文本不限于 ImageNet 那 1000 个类,而预测的图片也不限于 ImageNet 那 1.28 万张图片。然而,我依旧可以使用检索相似度的方式去得到输出,这样网络的灵活性就特别高了。不难发现,类别文本提取的特征类似于人脸识别里的检索库,图片提取特征就是待检测的那个。
以上就是 CLIP 工作的总览,可以看到 CLIP 在一次预训练后,可以方便的迁移到其他视觉分类任务上进行 Zero-Shoot 的前向预测。
下面来看一些效果。
由于 CLIP 学习的是文本语义信息,而不是单类别信息,这样做的好处可以体现在迁移能力上。CLIP 不仅在 ImageNet 常规数据集上表现优秀,对于 ImageNet Sketch 素描图、ImageNet-R 动漫图等非常规图像上的迁移学习能力依旧表现的非常好,如下:

来看最重要的 Zero-Shoot / Few-Shoot 的能力,主要对比有监督的 Base 网络,涉及的迁移数据集有 27 个之多,可以看到 CLIP 的 Zero-Shoot 能力十分突出,如下。 其中 Linear Probe 的意思是指训练的时候把预训练好的模型权重冻住,直接用其提取特征,然后只是去训练最后的 fc 分类头。
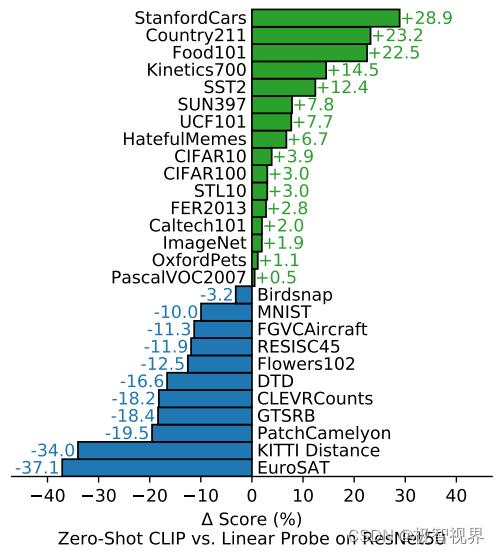
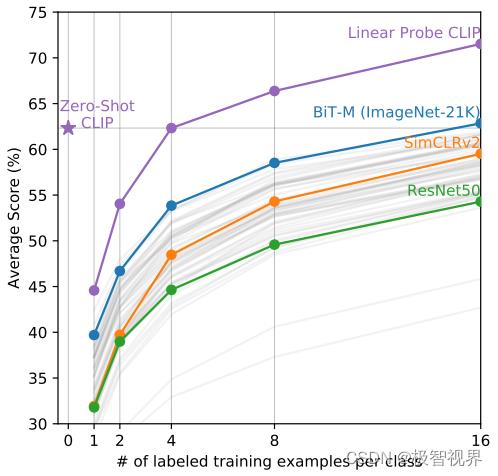
下面来看 CLIP 的实现。
2 CLIP 算法实现
CLIP 的整个逻辑比较清晰、简单,先看下 CLIP 整体伪代码:

其中视觉图片编码部分可以选择 ResNet 也可以选择 Vision Transformer,而本文编码部分就选择 Transformer。这里我以视觉部分用 ViT 来进行 CLIP 的实现讲解。
先看整体调用代码:
import torch
from clip import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device) # 预训练模型选择 ViT-B/32
image = preprocess(Image.open("./CLIP.png")).unsqueeze(0).to(device) # 预处理
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device) # 文本特征抽象化
with torch.no_grad():
# image_features = model.encode_image(image) # 图像提特征
# text_features = model.encode_text(text) # 文本提特征
logits_per_image, logits_per_text = model(image, text) # 输入图像、本文,输出
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
来看 CLIP 模型整体前向部分:
def forward(self, image, text):
image_features = self.encode_image(image) # 图片编码提特征
text_features = self.encode_text(text) # 文本编码提特征
# 特征归一化
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# 计算余弦相似度
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
其中 图片编码提特征实现:
# 图片编码提特征 image_features = self.encode_image(image)
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
# x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = torch.reshape(x, (x.shape[0], x.shape[1], -1))
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_post(x[:, 0, :])
if self.proj is not None:
x = x @ self.proj
return x
文本编码提特征实现如下:
# 文本编码提特征 text_features = self.encode_text(text)
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
其中文本 transformer 模块的实现如下:
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
最后当图像、文本特征都提取好后,对特征进行后处理及余弦相似度计算:
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
这样实现就差不多讲完了。
好了,以上分享了 多模态领域先行者 CLIP 的算法原理和实现。希望我的分享能对你的学习有一点帮助。
【公众号传送】

扫描下方二维码即可关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智AI | 多模态领域先行者 详解 CLIP 算法实现的主要内容,如果未能解决你的问题,请参考以下文章
极智AI | 变形金刚大家族 Transformer ViT CLIP BLIP BERT 模型结构