极智AI | 详解 ViT 算法实现
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智AI | 详解 ViT 算法实现相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文详细介绍一下 ViT 算法的设计与实现,包括代码。
ViT 全称 Vision Transformer,是 transformer 在 CV 领域应用表现好的开始,而在此之前,CV 领域一直是 CNN 的天下,虽然 ViT 主要用于图像分类这个简单的任务,但它说到底挑战了自从 2012 年 AlexNet 出世以来,卷积神经网络在计算机领域绝对统治的地位。ViT 的重要性不只在于证明了 transformer 在图像分类上也能 work 的很好,其贡献还在于它给大家挖了个大坑,并随之而来井喷出了大量 ViT 变种以及其他视觉任务的应用,如目标检测 (DETR)、语义分割 (SETR)、图像生成 (GANsformer) 、多模态应用 (CLIP) 等。
本文不止会介绍 ViT 的原理,还会介绍 ViT 的实现,包括代码。下面开始。
参考 Paper:《An Image is Worth 16x16 words Transformers for image recognition at scale》。
文章目录
1 ViT 算法原理
用 CNN 来提图像特征是大家所熟悉的,CNN 里最重要的算子是 卷积,卷积具有两个很重要的特性:translation equivariance 平移等价性 和 locality 局部性。来解释一下:
- translation equivariance 平移等价性:卷积是个滑窗的过程,每次的滑窗会对应一次矩阵乘,平移等价性的意思是你先做矩阵乘还是先平移滑窗,对卷积结果是不影响的,这最大的好处就是很容易进行并行化,以加速推理;
- locality 局部性:一般卷积核大小用 3 x 3 的比较多,3 x 3 卷积的感受野是有限的,只能 看 到局部区域,而不能一下子看到全局区域,所以卷积侧重关注在提取局部区域特征的关联,而不能很好的做全局特征的联系,这当然有好有坏;
ViT 里面的提特征方法和 CNN 的不一样,套用了 NLP Transformer 的方式,具体是怎么做的呢,用下面这个图可以很好的解释:

首先思考在 NLP 里,句子都是一维的,而图像数据是二维的,那怎么把二维的图像数据套成跟 NLP 一样一维的呢,有几种方法:
- 按像素展开,每个像素就是一个patch (一个 patch 类比 NLP 中的一个词),这样的话,如果以 224*224 的输入尺寸来说,patch数 = 224 x 224 = 50176。这样的做的缺点就是 patch数 太大了,是不可接受的,拿 BERT 对比一下,BERT 具有 4810 亿个参数,在 2048 块 TPUv4 下需要训练 20 个小时,而 BERT 的 patch数 也不过 512 而已,所以这显然不行;
- 用特征图作为 Transformer 的输入,比如先接一个 resnet50,出来 14x14 的特征图,即 patch数 = 14x14 = 196,再输入 Transformer;
- 按轴展开,这种是做了两次的自注意力,一次是横轴的自注意力,另一次是纵轴的自注意力,把 H x W 的复杂度 拆成了 H + W 的复杂度;
- 把窗口块作为一个 patch,思想就像卷积那样;
ViT 即用了等分窗口图片块的思想来构造 patch,把图像打成块,如 输入 224 x 224 的图,patch 大小为 16 x 16,则 patch 数为 (224/16) x (224/16) = 14 x 14 = 196,这个时候相当于把 16 x 16 的 patch 当做 NLP 里面的单词,如上图 (上图是打成了 9 个 patch)。
然后要做的是给图像块嵌入位置信息,也就是所谓的 Position Embedding,位置信息的嵌入是怎么做的呢。先在图像块后面接一个 fc 层,将图像数据转换为 tensor 数据,然后将位置编码嵌入用于表达图像块在原图的位置信息,这样就完成了位置嵌入。具体从方法上可以位置编码分为几种:
- Providing no positional information:不考虑位置信息;
- 1-dimensional positional embedding:把 CV 当 NLP 来做,只考虑一维位置信息;
- 2-dimensional positional embedding:考虑 CV 特殊的二维空间位置信息;
- Relative positional embedding:相对位置编码,既考虑相对位置信息又考虑绝对位置信息;
虽然位置编码的方法挺多,但从实验来看对网络最后的结果影响不大(No Pos 会相对低一点),数据如下:
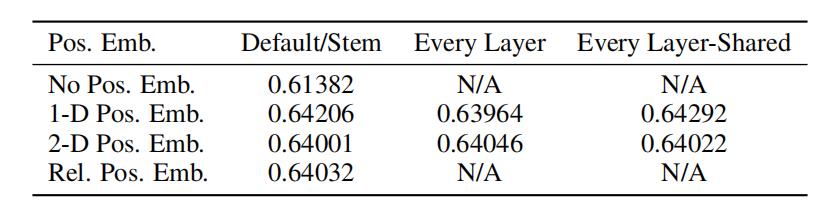
嵌入操作还有一个特殊的地方是在最前端需要加入一个类别编码,也即 class embedding,类别编码用于最后的类别输出,参考至 BERT 的 class token,整个过程示意如下图:

这里比较有趣的一点是,最后预测类别的时候 (1) 使用 class token;(2) 使用输出特征全局平均池化,出来的结果其实是差不多的,也就是这两种方式都是可行的,更倾向于使用 class token 是因为想把原滋原味的 transformer 直接应用到 CV 领域。这两种预测类别的方式试验效果如下,其中蓝色是 class token 的,橙色和绿色是 全局平均池化的,橙色的存在告诉你需要好好调参,结果的好坏和你调参的姿态关系很大:

然后进入标准的 Transformer Encoder,Transformer Encoder 里面有些什么呢,其实比较清爽,就是两个块的堆叠,然后再整体叠加 L 次。这两个块指的是:
- LayerNorm + Multi-Head Attention
- LayerNorm + MLP

来说说 LayerNorm,这个可能很容易引起我们的注意,在 CV 里用的比较多的是 BatchNorm,那这里 (或 NLP) 里为啥不喜欢用 BN 呢?因为 NLP 里输入序列往往是动态的,即序列的长度不定,一个序列对于我们来说就是一个样本,而 BN 计算的是样本间的归一化,这样做一定会导致值域波动很大;而 LN 是在样本内做,不用考虑类间差异,波动就相对小很多。
来说说 Multi-Head Attention 多头注意力机制,来源于论文《Attention Is All You Need》,示意如下:
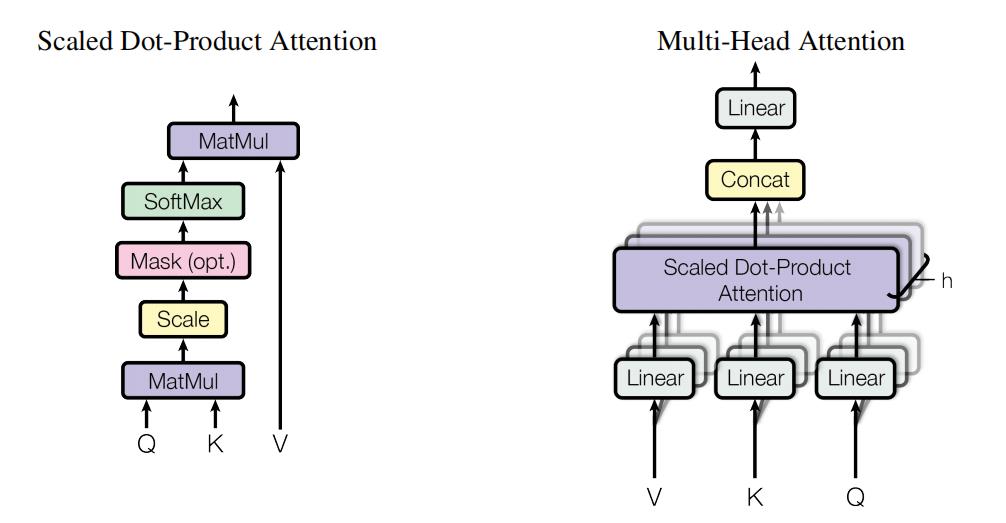
多头即将模型分为多个头,形成多个子空间,让模型去关注不同方面的信息,将 Scaled Dot-Product Attention 过程做 h 次,再把输出做 cat。这样做的目的是为了使网络能够综合利用多方面角度提取更加准确的表示,从而可以捕捉到更加丰富的特征,可以类比 CNN 中多个核分别提取特征的作用,原文是这么说的:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
再来说说 MLP,MLP 全称 multi-layer perceptron,里面使用非线性激活函数去做分类的预测。
最后直接上性能数据,可以看到在多个权威数据集上的表现都是最好的:

再来一张最直观的图,下图中 BiT 代表 ResNet,ViT* 代表 ViT 系列,可以看到在相对小一些的数据集上如 ImageNet,ViT 普遍比不过 ResNet,而在 ImageNet-21k 这种中型的数据集上 ViT 性能和 ResNet 旗鼓相当,慢慢开始超越了,当在 JFT-300M 这种大型一些的数据集上时,ViT 开始全面超越 ResNet,如下:

接下来说说 ViT 的实现。
2 ViT 算法实现
我这里是参考了 CLIP 中的 ViT 实现部分,因为 CLIP 实质上就是两个分支:image encoder 和 text encoder,其中的 image encoder 分支提特征就是直接用了 ViT 的网络,故可以直接参考。
ViT 的实现模块很清晰,主要是以下几个模块:
(1) 图片打成块;
(2) 位置编码;
(3) 多头注意力模块;
(4) MLP;
所以整个网络的定义会是这个样子的 (由于其他一些需求,我改了一些代码,不过不影响解释算法实现):
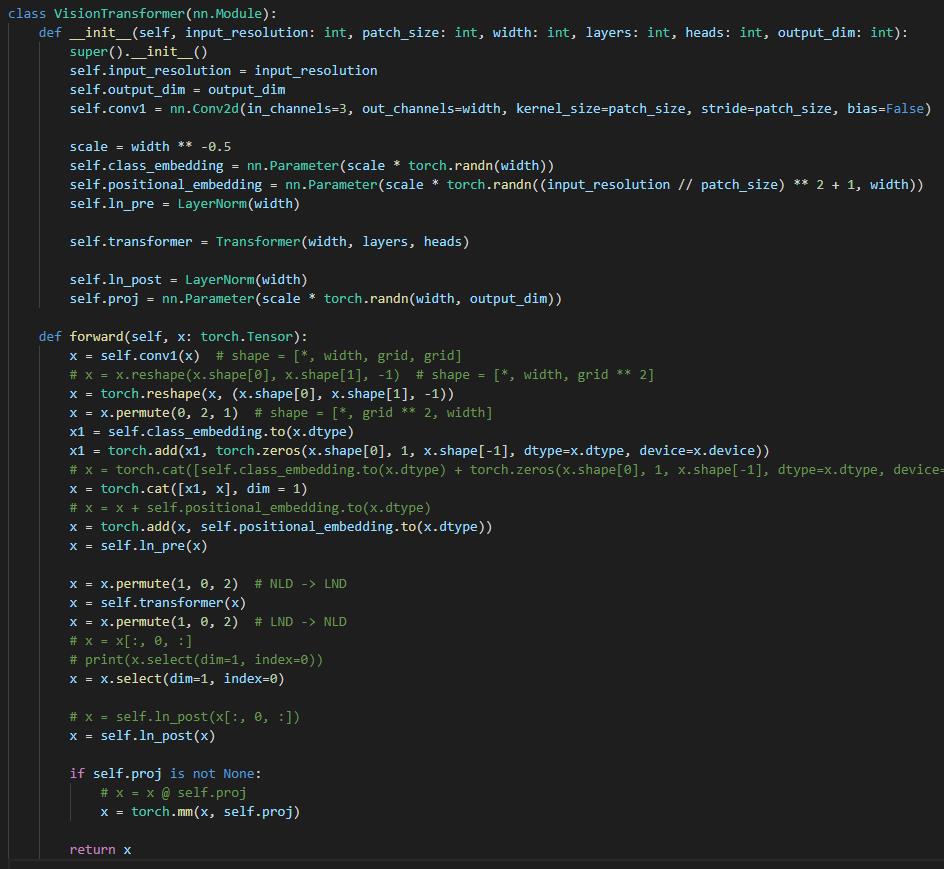
这里主要关于前向 forward,下面逐一展开。
2.1 图片打成块
### 图片打成块,直接用卷积
x = self.conv1(x) # shape = [*, width, grid, grid]

2.2 位置编码
### 位置和类别编码
# x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = torch.reshape(x, (x.shape[0], x.shape[1], -1))
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
### 类别编码
x1 = self.class_embedding.to(x.dtype)
x1 = torch.add(x1, torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device))
# x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = torch.cat([x1, x], dim = 1)
# x = x + self.positional_embedding.to(x.dtype)
### 位置编码
### 类别和位置编码结合
x = torch.add(x, self.positional_embedding.to(x.dtype))
2.3 多头注意力
接下来就开始进入提特征主干网络:
x = self.transformer(x) # self.transformer = Transformer(width, layers, heads)
来看下 Transformer 的定义:
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
很明显这里最关键的是 ResidualAttentionBlock,来看:
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
# x = x + self.attention(self.ln_1(x))
x = torch.add(x, self.attention(self.ln_1(x))) ## 多头注意力
# x = x + self.mlp(self.ln_2(x))
x = torch.add(x, self.mlp(self.ln_2(x))) ## MLP
return x
这里就会形成 多头注意力 和 MLP 的交替堆叠,至于堆叠多少轮,由上面的 for _ in range(layers) 也就是 layers 的大小控制。先说 多头自注意力。
self.attn = nn.MultiheadAttention(d_model, n_head) ## embed_dim, num_heads
其中 d_model(embed_dim) 和 n_head(num_heads) 是两个重要调参,一个控制 patch 大小,一个控制多头有几个头。
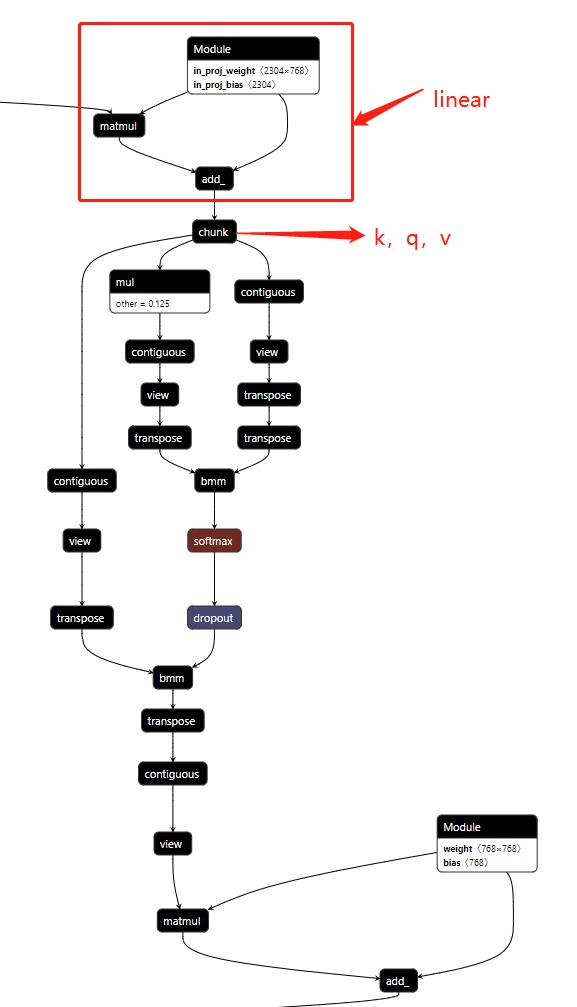
2.4 MLP
接着是 MLP:
x = torch.add(x, self.mlp(self.ln_2(x)))
其中 self.mlp 为:
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
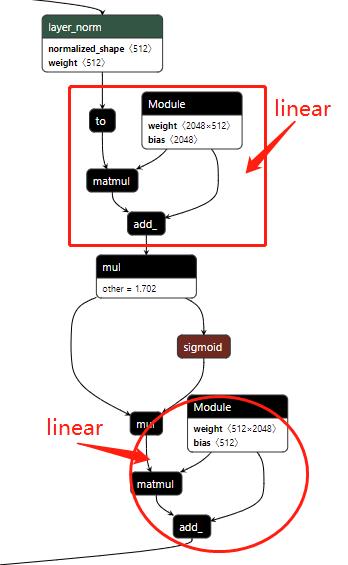
可以看出 MLP 的实现其实很简单,为:LN + fc + gelu + fc,其中 gelu 是激活函数,这里使用了一个简单的 sigmoid:
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
x = torch.mul(x, 1.702)
x1 = torch.sigmoid(x)
x = torch.mul(x, x1)
return x
总体结构如下:
好了,以上分享了 ViT 算法的实现,包括原理和代码。希望我的分享能对你的学习有一点帮助。
【公众号传送】

扫描下方二维码即可关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智AI | 详解 ViT 算法实现的主要内容,如果未能解决你的问题,请参考以下文章
极智AI | 变形金刚大家族 Transformer ViT CLIP BLIP BERT 模型结构