多模态预训练CLIP模型的强大为例
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多模态预训练CLIP模型的强大为例相关的知识,希望对你有一定的参考价值。
微信公众号“圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~ 后台回复“交流”加入“圆圆的算法笔记”交流群;回复“时间序列“、”多模态“、”迁移学习“、”NLP“等获取各个领域干货算法笔记~
最近在看ACL 2022论文的时候,发现了一篇很有意思的文章:CLIP Models are Few-shot Learners。这个文章标题马上让人联想起GPT3那篇文章Language Models are Few-Shot Learners。CLIP自2021年被提出以来一直是多模态领域研究的热点,结合对比学习和prompt这两种方法,利用文本信息进行图像的无监督训练,实现zero-shot的图像分类,也可以被应用到图片文本匹配等多模态任务中。CLIP Models are Few-shot Learners这篇文章对CLIP进行了更加深入的探索,包括如何利用CLIP通过zero-shot、few-shot的方式解决VQA任务、图文蕴含任务。下面带大家详细梳理一下这篇论文的工作。

1. CLIP回顾
这一小节我们来简单回顾一下CLIP。Learning Transferable Visual Models From Natural Language Supervision(ICML 2021)提出CLIP模型,利用对比学习使用文本对图像进行无监督训练,再利用prompt进行zero-shot的图像分类。一般的图像分类任务,都需要对图像进行大量的标注得到标注数据,然后用户模型训练。而本文提出,使用天然的图片和对应的图片说明文本,预训练一个图片文本匹配的模型,就能实现效果很好的图片表示提取。
首先,作者构建了海量的图片-文本对,从多个数据集中筛选出图像和对应的图像标注为自然语言的数据,构造了image-text pair。这些数据会作为预训练的输入,用来学习文本和图片的匹配任务。模型采用了ResNet、ViT两种模型作为图像端的encoder,采用Transformer作为文本端的encoder。在预训练阶段采用对比学习的思路,给定一个batch的N条图像-文本的pair对,它们可以组成一个矩阵,对角线上的元素为正样本,其他组合为负样本。通过这种方式每个batch的数据生成N个样本,以及N*(N-1)个负样本。在Finetune阶段,文本端采用了prompt的方式,例如分类任务,构造分类模板,并将各个类别填入模板空缺处,预测每个模板实体和当前图像的匹配得分,得分最高的即为图像的分类结果。
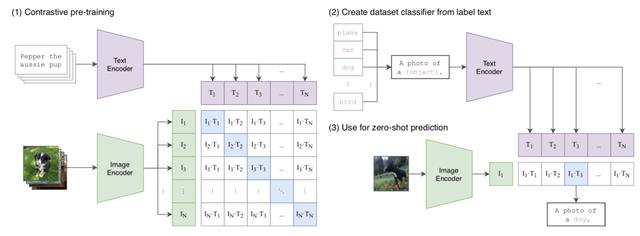
文中最开始也尝试了基于预测的方法,根据image的信息预测对应的文本的每个词是什么。然而由于对于一个图像的描述可以有很多种,因此预测一个图像具体的描述词是一个非常困难的任务,导致模型收敛存在问题。因此,CLIP使用对比学习的方法,将任务简单化,只去判断图文pair是否匹配,极大提升了模型收敛速度。
2. Zero-shot
解决VQA问题之前关于CLIP的一些研究就尝试过用CLIP解决VQA问题,但是效果很差。作者认为效果差不是CLIP的问题,而是之前的人都没用好,没有完全发挥出CLIP的潜力。为了通过zero-shot learning解决VQA任务,一个核心的问题是如何将VQA任务利用prompt的思路转化成完形填空任务。只有将VQA任务转换成更接近CLIP预训练阶段的任务,才能更好发挥预训练CLIP的能力。为此,作者提出了一个两阶段的VQA prompt生成方法(作者起名叫TAP-C)。
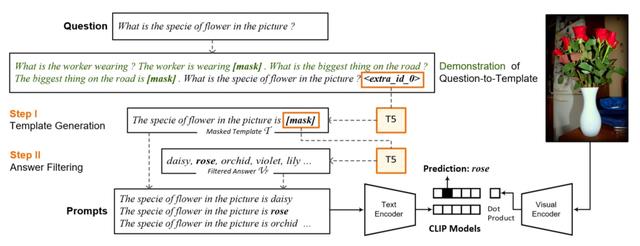
第一步:将问题转换成一个回答的prompt模板,也就是变成一个描述性的句子。举个例子,如下图,假设当前VQA的样本问的问题是What is the specie of flower in the picture ? 我们其实可以根据这个一个模板,把这个问题变成陈述句:The specie of flower in the picture is [mask]。生成了这个模板,后面就可以基于prompt的思路,将这个模板输入到预训练CLIP的text encoder侧,通过对[mask]的预测,得到答案。
根据问题生成描述性句子,文中提出了两种方法。第一种是使用预训练的T5模型,以及一些demonstration,生成问题的描述性句子。下表是一个例子,demonstration都是一个问题+一个描述性句子,在这些demonstration后面拼接上当前样本的question部分以及一个特殊的mask符号,让T5模型自动生成被mask的部分,也就是描述性文本。这种demonstration的方法在GPT等工作中被经常使用。由于T5的预训练任务就是对随机mask的span进行预测,且被mask的span没有长度限制,因此天然适合这个任务。

生成描述性句子的第二种方法是利用part-of-speech tagging和语法解析的方法,识别问题中的各个成分,并重新生成描述性句子。这种方法看起来更稳妥。在最终使用时,作者结合了两种方法,如果第一种模型生成的置信度较高,就用第一种方法生成的句子,否则使用第二种方法生成的句子。
第二步:使用预训练语言模型过一遍生成的描述性文本,让语言模型填充mask部分的候选答案。这一步其实是在做一个答案过滤,利用预训练语言模型在大量语料上学习到的一般性知识,生成在当前描述性文本给定的上下文信息下,最有可能的top K个候选答案。
通过上述方式,就生成了很多个文本侧的填充了答案的描述性语句。这部分作为文本侧输入,同时在图像侧输入图像信息,使用预训练CLIP给出打分结果,实现了zero-shot的VQA任务。这种数据构造方法,把下游任务变得和CLIP预训练任务完全一致,能够最大限度发挥CLIP模型的作用。而以前的工作,例如ViLT(在之前的多模态文章中介绍过该工作,感兴趣的同学可以查看),是将VQA任务看做一个多分类任务,然后在预训练CLIP的基础上进行finetune。虽然将VQA视为分类任务是一个非常传统的做法,但是这样导致预训练CLIP和下游任务差距太大,无法充分利用CLIP学到的知识,因此也导致ViLT在VQA任务上的效果并不好。
3. Zero-shot 解决图文蕴含问题
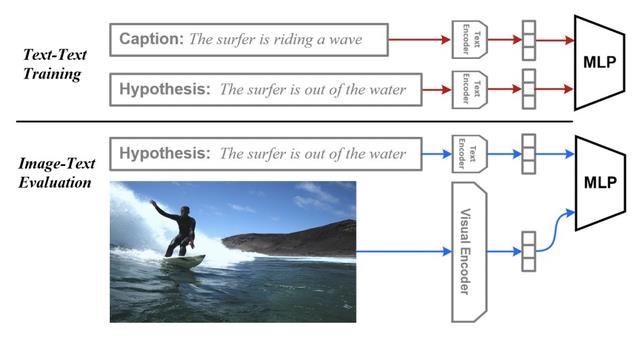
文中希望验证的另一个点是,CLIP这种多模态模型,image侧的encoder和text侧的encoder是否有很强的跨模态能力,即两个encoder的表示在隐空间中是完全对齐的。为了验证这个问题,作者将预训练CLIP的参数固定不动,使用纯文本的caption和hypothesis训练一个文本蕴含任务的分类器。接下来,对于图像-文本的蕴含任务,将图像侧信息输入到image encoder中,文本侧仍然输入到text encoder中,使用基于文本训练好的分类器进行预测。这样其实是只用文本蕴含任务的数据训练,得到了图文蕴含任务的模型,是zero-shot learning。这个过程的简单示意图如下:
4. Few-shot 解决VQA问题
文中还验证了CLIP + few-shot learning能给VQA任务带来多少提升,通过在小样本上finetune CLIP模型的部分参数,提升CLIP在zero-shot VQA上的效果。作者将VQAv2数据集按照问题类型和答案类型划分成65*3=195个类别,每个类别从数据中采样K个样本,使用一半作为queryset,另一半作为supportset。利用这些数据对CLIP进行finetune,只finetune网络的bias部分和layer normalization部分的参数。
利用这些样本,可以构造和TAP-C中相同的文本侧输入和图像侧输入。文本则相当于已经知道答案,将问题转换成描述性文本。然后让CLIP在这些数据上学习,使用图像侧和文本侧的表示的点积结果,用交叉熵损失优化。这个过程就是让CLIP先见一些TAP-C中将要预测的样本,以此提升模型效果。
此外,另一种方式是使用GPT-3中的in-context demonstration方法来提升TAP-C的效果,即将一些有标注的样本作为一些示例,和TAP-C中根据question构造的prompt一起输入。
5. 实验结果
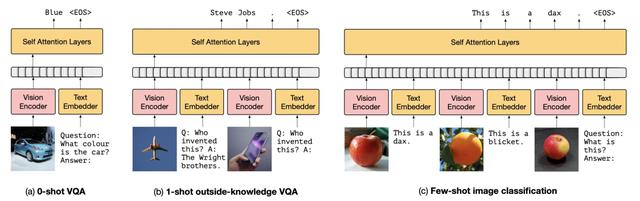
在zero-shot VQA任务上,作者和另外两种方法进行了对比。第一种方法是Multimodal Few-Shot Learning with Frozen Language Models(2021,Frozen)。这篇文章的方法是将图像侧的信息用一个vison encoder当成prefix prompt,融入到一个已经训练好的语言模型中。可以理解为将prefix prompt替换成了vision embedding。感兴趣的同学可以参考之前关于prompt的文章,下图是这篇文章中的zero-shot方法。
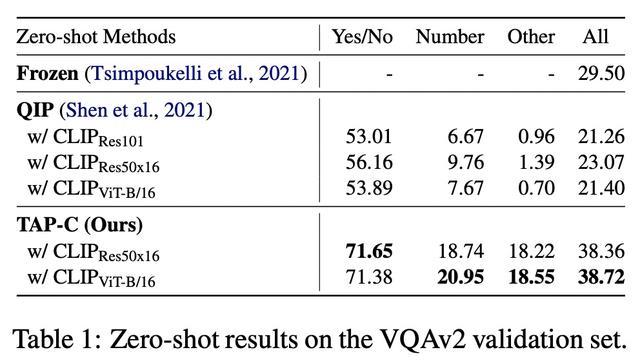
第二种方法是How Much Can CLIP Benefit Vision-and-Language Tasks?(2021,QIP)提出的,原始的CLIP在文本侧将图像的label对应的prompt拼到一起,预测哪对文本-图片打分最高进行图像分类;这篇文章中直接构造了“question: [question text] answer: [answer text]”这样的prompt,将问题和每个答案分别填到对应的位置,判断生成的每个文本的分数,和原始的CLIP思路相同。这种方法的问题在于所构造的prompt和具体问题是无关的,相比本文构造的prompt,其实是问题的一个描述性转换,是和问题相关的。
作者对比了自己的方法和Frozen、QIP这两种VQA zero-shot learning方法,效果提升非常显著。对比QIP和TAP-C可以发现,虽然用的都是CLIP模型,但是不同的prompt构造方法,效果差异非常大。TAP-C这种根据问题构造prompt的方法,要明显好于QIP这种所有问题用简单统一模板构造的方法。
另一个实验是验证zero-shot learning在图文蕴含任务中的效果。从下面的实验结果可以看出,使用文本+文本进行训练,迁移到Image+文本的文本蕴含任务效果,已经能够和使用Image+文本训练的分类器效果差不多了,这说明预训练的CLIP确实已经很好的完成图像和文本的对齐工作。
最后,文中验证了zero-shot对预训练CLIP的提升情况。如下表,引入few-shot会带来效果的提升,并且随着k-shot中k的增加,让模型见到更多样本,效果也会提升更明显。
除了上面的实验结论外,文中进行了一些消融实验,例如T5生成和语法解析两种方法生成带来的效果提升;prompt模板不考虑问题会带来一半的效果下降;finetune阶段是采用文中提到的只finetune bias和batch normalization参数要优于所有参数都finetune。
最后,本文也总结了目前CLIP方法仍然存在的问题。其中一个问题是CLIP对于一些比较微小的语义差异分辨能力不足,需要后面对CLIP模型的text encoder进行进一步优化。
微信公众号“圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~ 后台回复“交流”加入“圆圆的算法笔记”交流群;回复“时间序列“、”多模态“、”迁移学习“、”NLP“等获取各个领域干货算法笔记~
【历史干货算法笔记】
最新NLP Prompt代表工作梳理!ACL 2022 Prompt方向论文解析
一网打尽:14种预训练语言模型大汇总
Vision-Language多模态建模方法脉络梳理
Spatial-Temporal时间序列预测建模方法汇总
12篇顶会论文,深度学习时间序列预测经典方案汇总
花式Finetune方法大汇总
NLP中的绿色Finetune方法
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
缺少训练样本怎么做实体识别?小样本下的NER解决方法汇总
以上是关于多模态预训练CLIP模型的强大为例的主要内容,如果未能解决你的问题,请参考以下文章