摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台相关的知识,希望对你有一定的参考价值。
简介:本文将介绍和梳理我们对云原生 AI 这个新领域的思考和定位,介绍云原生 AI 套件产品的核心场景、架构和主要能力。

作者:张凯
前言
云原生(Cloud Native)[1]是云计算领域过去 5 年发展最快、关注度最高的方向之一。CNCF(Cloud Native Computing Foundation,云原生计算基金会)2021年度调查报告[2]显示,全球已经有超过 680 万的云原生技术开发者。同一时期,人工智能 AI 领域也在“深度学习算法+GPU 大算力+海量数据”的推动下持续蓬勃发展。有趣的是,云原生技术和 AI,尤其是深度学习,出现了很多关联。
大量 AI 算法工程师都在使用云原生容器技术调试、运行深度学习 AI 任务。很多企业的 AI 应用和 AI 系统,都构建在容器集群上。为了帮助用户更容易、更高效地在基于容器环境构建 AI 系统,提高生产 AI 应用的能力,2021 年阿里云容器服务 ACK 推出了云原生 AI 套件产品。本文将介绍和梳理我们对云原生 AI 这个新领域的思考和定位,介绍云原生 AI 套件产品的核心场景、架构和主要能力。
AI 与云原生极简史
回顾 AI 的发展历史,我们会发现这早已不是一个新的领域。从 1956 年达特茅斯学术研讨会上被首次定义,到 2006 年 Geoffery Hinton 提出了“深度信念网络”(Deep Believe Network),AI 已历经 3 次发展浪潮。尤其是近 10 年,在以深度学习(Deep Learning)为核心算法、以 GPU 为代表的大算力为基础,叠加海量生产数据积累的推动下,AI 技术取得了令人瞩目的进展。与前两次不同,这一次 AI 在机器视觉、语音识别、自然语言理解等技术上实现突破,并在商业、医疗、教育、工业、安全、交通等非常多行业成功落地,甚至还催生了自动驾驶、AIoT 等新领域。
然而,伴随 AI 技术的突飞猛进和广泛应用,很多企业和机构也发现想要保证“算法+算力+数据”的飞轮高效运转,规模化生产出有商业落地价值的 AI 能力,其实并不容易。昂贵的算力投入和运维成本,低下的 AI 服务生产效率,以及缺乏可解释性和通用性的 AI 算法,都成为横亘在 AI 用户面前的重重门槛。
与 AI 的历史类似,云原生领域的代表技术 —— 容器(container),也不是一个新的概念。其最早可追溯到 1979 年诞生的 UNIX chroot 技术,就开始显现出容器的雏型。接下来又出现了 FreeBSD Jails,Linux VServer,OpenVZ,Warden 等一系列基于内核的轻量级资源隔离技术。直到 2013 年 Docker 横空出世,以完善的容器对象封装、标准的 API 定义和友好的开发运维体验,重新定义了使用数据中心计算资源的界面。随后的故事大家都知道了,Kubernetes 在与 Docker Swarm 和 Mesos 的竞争中胜出,成为容器编排与调度的事实标准。Kubernetes 和容器(包括 Docker,Containerd,CRI-O 等多种容器运行时和管理工具)构成了 CNCF 定义的云原生核心技术。经过 5 年高速发展,云原生技术生态已经覆盖了容器运行时、网络、存储和集群管理、可观测性、弹性、DevOps、服务网格、无服务器架构、数据库、数据仓库等 IT 系统的方方面面。
为何出现云原生 AI
据 CNCF 2021 年度相关调查报告显示, 96% 的受访企业正在使用或评估 Kubernetes,这其中包括了很多 AI 相关业务的需求。Gartner 曾预测,到 2023 年 70% 的 AI 应用将基于容器和 Serverless 技术开发。
现实中,在研发阿里云容器服务 ACK[3](Alibaba Container service for Kubernetes)产品过程中,我们看到越来越多用户希望在 Kubernetes 容器集群中管理 GPU 资源,开发运行深度学习和大数据任务,部署和弹性管理 AI 服务,且用户来源于各行各业,既包括互联网、游戏、直播等快速增长的公司,也有自动驾驶、AIoT 这类新兴领域,甚至不乏政企、金融、制造等传统行业。
用户在开发、生成、使用 AI 能力时碰到很多共性的挑战,包括 AI 开发门槛高、工程效率低、成本高、软件环境维护复杂、异构硬件管理分散、计算资源分配不均、存储接入繁琐等等。其中不少用户已经在使用云原生技术,并成功提升了应用和微服务的开发运维效率。他们希望能将相同经验复制到 AI 领域,基于云原生技术构建 AI 应用和系统。
在初期,用户利用 Kubernetes,Kubeflow,nvidia-docker 可以快速搭建 GPU 集群,以标准接口访问存储服务,自动实现 AI 作业调度和 GPU 资源分配,训练好的模型可以部署在集群中,这样基本实现了 AI 开发和生产流程。紧接着,用户对生产效率有了更高要求,也遇到更多问题。比如 GPU 利用率低,分布式训练扩展性差,作业无法弹性伸缩,训练数据访问慢,缺少数据集、模型和任务管理,无法方便获取实时日志、监控、可视化,模型发布缺乏质量和性能验证,上线后缺少服务化运维和治理手段,Kubernetes 和容器使用门槛高,用户体验不符合数据科学家的使用习惯,团队协作和共享困难,经常出现资源争抢,甚至数据安全问题等等。
从根本上解决这些问题,AI 生产环境必然要从“单打独斗的小作坊”模式,向“资源池化+AI 工程平台化+多角色协作”模式升级。为了帮助有此类诉求的“云原生+AI”用户实现灵活可控、系统化地演进,我们在 ACK 基础上推出云原生 AI 套件[4]产品。只要用户拥有一个 ACK Pro 集群,或者任何标准 Kubernetes 集群,就可以使用云原生 AI 套件,快速定制化搭建出一个自己的 AI 平台。把数据科学家和算法工程师从繁杂低效的环境管理、资源分配和任务调度工作中解放出来,把他们更多的精力留给“脑洞”算法和“炼丹”。
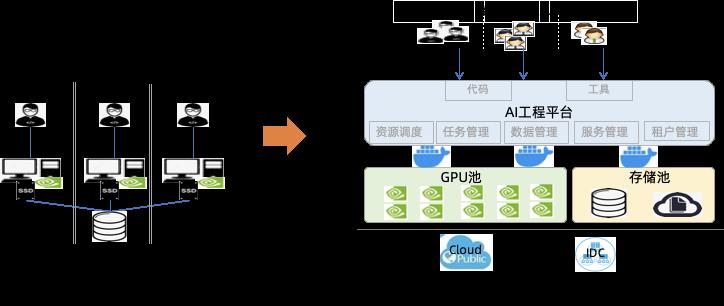
图0:AI 生产环境向平台化演进
如何定义云原生 AI
随着企业 IT 架构逐步深入地向云计算演进,以容器、Kubernetes、服务网格等为代表的云原生技术,已经帮助大量应用服务快速落地云平台,并在弹性、微服务化、无服务化、DevOps 等场景中获取很大价值。与此同时,IT 决策者们也在考虑如何通过云原生技术,以统一架构、统一技术堆栈支撑更多类型的工作负载。以避免不同负载使用不同架构和技术实现,带来“烟囱”系统、重复投入和割裂运维的负担。
深度学习和 AI 任务,正是社区寻求云原生支撑的重要工作负载之一。事实上,越来越多深度学习系统、AI 平台已经构建在容器和 Kubernetes 集群之上。在 2020 年,我们就明确提出“云原生 AI”的概念、核心场景和参考技术架构,以期为这个全新领域提供具象的定义,可落地的路线图和最佳实践。
阿里云容器服务 ACK 对云原生 AI 的定义 - 充分利用云的资源弹性、异构算力、标准化服务以及容器、自动化、微服务等云原生技术手段,为 AI/ML 提供工程效率高、成本低、可扩展、可复制的端到端解决方案。
核心场景
我们将云原生 AI 领域聚焦在两个核心场景:持续优化异构资源效率,和高效运行 AI 等异构工作负载。
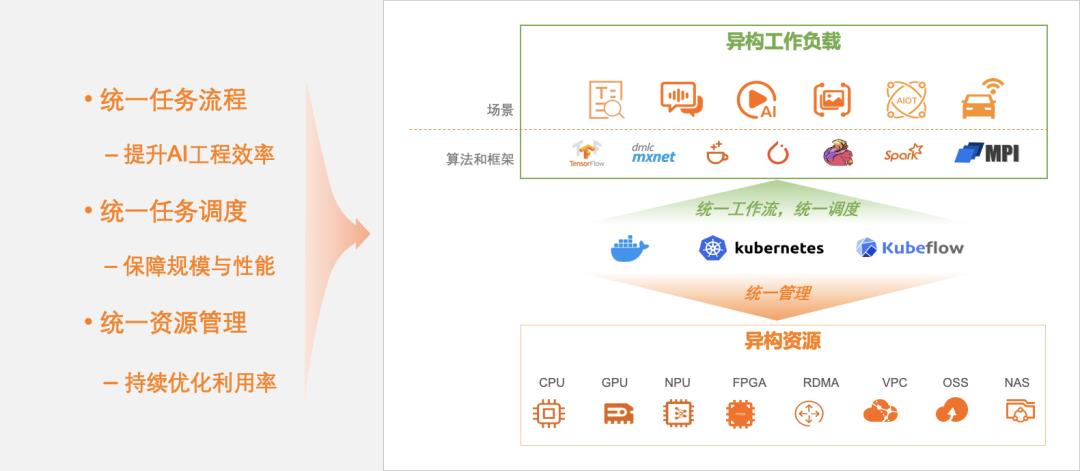
图1:云原生 AI 的核心场景
场景 1、优化异构资源效率
对阿里云 IaaS 或者客户 IDC 内各种异构的计算(如CPU,GPU,NPU,VPU,FPGA,ASIC)、存储(OSS,NAS, CPFS,HDFS)、网络(TCP, RDMA)资源进行抽象,统一管理、运维和分配,通过弹性和软硬协同优化,持续提升资源利用率。
场景 2、运行 AI 等异构工作负载
兼容 Tensorflow,Pytorch,Horovod,ONNX,Spark,Flink 等主流或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载流程,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。一方面不断提升运行任务的性价比,另一方面持续改善开发运维体验和工程效率。
围绕这两个核心场景,可以扩展出更多用户定制化场景,比如构建符合用户使用习惯的 MLOps 流程;或者针对 CV 类(Computer Vision, 计算机视觉)AI 服务特点,混合调度 CPU,GPU,VPU(Video Process Unit)支持不同阶段的数据处理流水线;还可以针对大模型预训练和微调场景,扩展支持更高阶的分布式训练框架,配合任务和数据调度策略,以及弹性、容错方案,优化大模型训练任务成本和成功率。
参考架构
为了能支撑上述核心场景,我们提出了云原生 AI 参考技术架构。
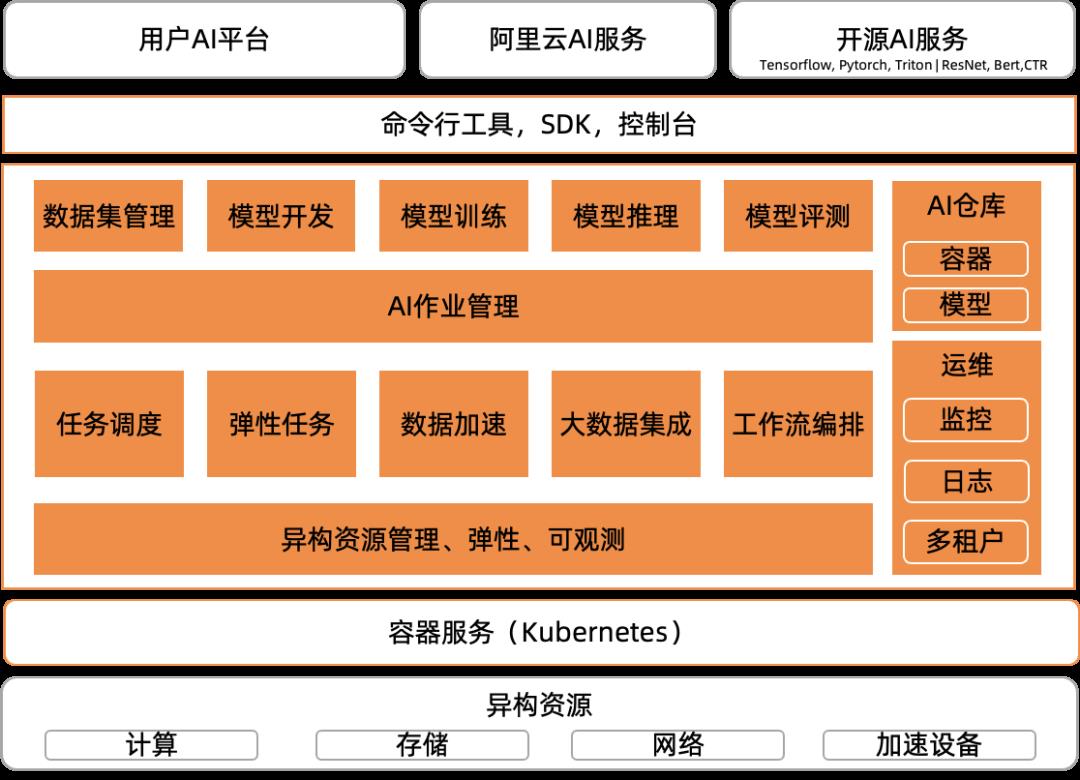
图 2:云原生 AI 参考架构图
云原生 AI 参考技术架构以组件化、可扩展和可组装的白盒化设计原则,以 Kubernetes 标准对象和 API 暴露接口,支持开发运维人员按需选择任意组件,进行组装和二次开发,快速定制化构建出自己的 AI 平台。
参考架构中以 Kubernetes 容器服务为底座,向下封装对各类异构资源的统一管理,向上提供标准 Kubernetes 集群环境和 API,以运行各核心组件,实现资源运维管理、AI 任务调度和弹性伸缩、数据访问加速、工作流编排、大数据服务集成、AI 作业生命周期管理、各种 AI 制品管理、统一运维等服务。再向上针对 AI 生产流程(MLOps)中的主要环节,支持 AI 数据集管理,AI模型开发、训练、评测,以及模型推理服务;并且通过统一的命令行工具、多种语言 SDK 和控制台界面,支持用户直接使用或定制开发。而且通过同样的组件和工具,也可以支持云上 AI 服务、开源 AI 框架和第三方 AI 能力的集成。
企业需要什么样的云原生 AI 能力
我们定义了云原生 AI 的概念、核心场景、设计原则和参考架构。接下来,需要提供什么样的云原生 AI 产品给用户呢?通过对 ACK 上运行 AI 任务的用户调研,对云原生、MLOps、MLSys 等社区的观察,结合业界一些容器化 AI 产品的分析,我们总结出一款云原生 AI 产品需要具备的特征和关键能力。

图 3:企业需要什么样的云原生 AI 能力
- 效率高
主要包括:异构资源使用效率,AI 作业运行和管理效率,租户共享和团队协作效率等三个维度
- 兼容性好
兼容常见的 AI 计算引擎和模型。支持各类存储服务,并能提供通用的数据访问性能优化能力。可以与多种大数据服务集成,并能被业务应用方便地集成。特别地,还要符合数据安全与隐私保护的要求。
- 可扩展
产品架构实现可扩展、可组装、可复现。提供标准API和工具,便于使用、集成和二次开发。同样的架构下,产品实现尽量适配公共云,专有云,混合云,以及边缘等多种环境的交付。
阿里云容器服务 ACK 云原生 AI 套件
基于云原生 AI 参考架构,面向上述核心场景和用户需求,阿里云容器服务团队在 2021 年正式发布了 ACK 云原生 AI 套件产品[5],已经在全球 27 个区域同步上线公测,帮助 Kubernetes 用户快速定制化构建自己的云原生 AI 平台。
ACK 云原生 AI 套件主要面向 AI 平台开发运维团队,帮助其快速、低成本地管理 AI 基础设施。同时将各组件功能封装成命令行和控制台工具,供数据科学家和算法工程师直接使用。用户在 ACK 集群中安装云原生 AI 套件后,所有组件开箱即用,快速实现统一管理异构资源和低门槛运行 AI 任务。产品安装和使用方式,可以参考产品文档[6]。
架构设计
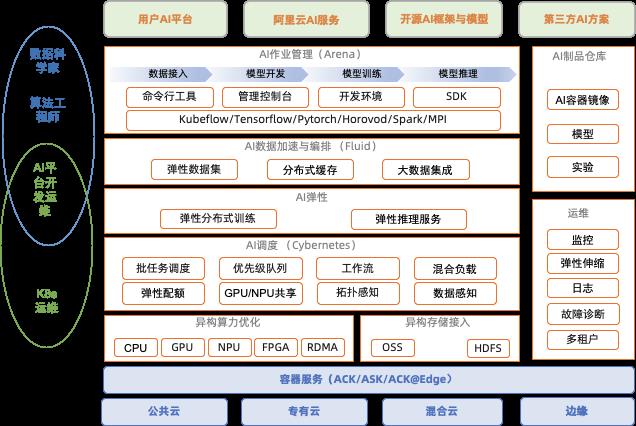
图 4:云原生 AI 套件架构大图
云原生 AI 套件的功能从底向上分为:
- 异构资源层,包括异构算力优化和异构存储接入
- AI 调度层,包括各种调度策略优化
- AI 弹性层,包括弹性 AI 训练任务和弹性 AI 推理服务
- AI 数据加速与编排层,包括数据集管理,分布式缓存加速,大数据服务集成
- AI 作业管理层,包括 AI 作业全生命周期管理服务和工具集
- AI 运维层,包括监控、日志、弹性伸缩、故障诊断和多租户
- AI 制品仓库,包括 AI 容器镜像,模型和 AI 实验记录
下文将简要介绍云原生 AI 套件产品中异构资源层,AI 调度层,AI 弹性任务层,AI 数据加速与编排层和 AI 作业管理层的主要能力和基本架构设计。
1、异构资源统一管理
云原生 AI 套件在 ACK 上,增加了对 Nvidia GPU,含光 800 NPU,FPGA,VPU,RDMA 高性能网络等各种异构资源的支持,基本覆盖了阿里云上所有设备类型,使得在 Kubernetes 中使用这些资源的方式和使用 CPU、内存一样简单,只要在任务参数中声明需要的资源数量即可。针对 GPU,NPU 这类比较昂贵的资源,还提供了多种资源利用率优化方法。
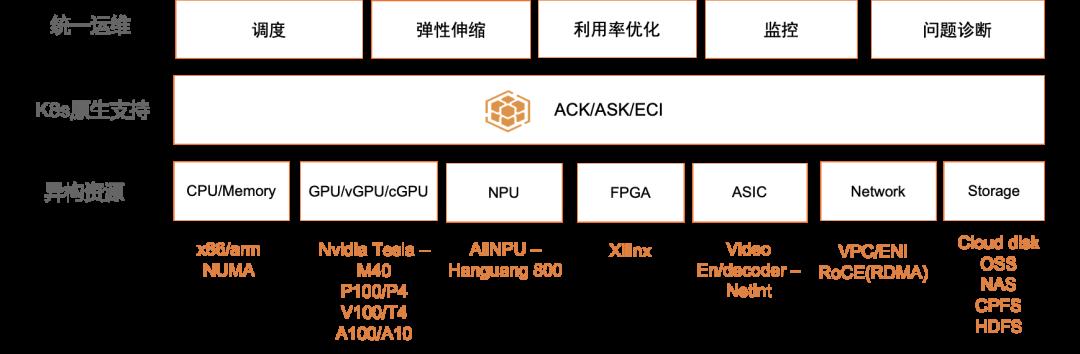
图 5:异构资源统一管理
GPU 监控
针对 GPU 提供了多维度监控能力,使得 GPU 的分配、使用和健康状态一目了然。通过内置Kubernetes NPD(Node Problem Detector)自动检测和告警 GPU 设备异常。
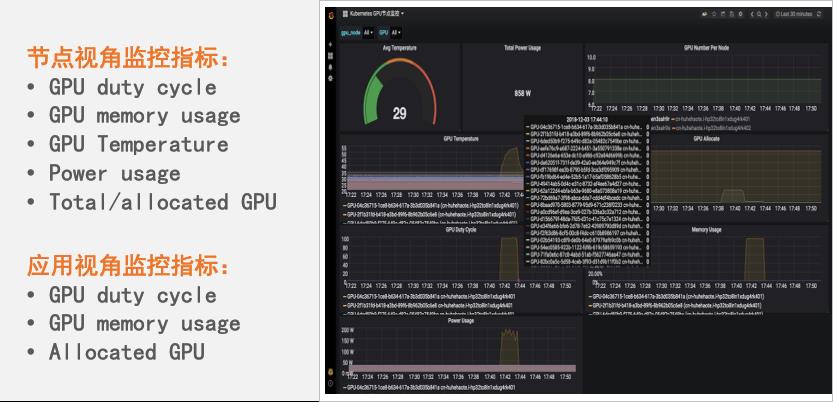
图 6:GPU 监控
GPU 弹性伸缩
结合 ACK 弹性节点池提供的多种弹性伸缩能力,对 GPU 在资源节点数和运行任务实例数两层都可以按需自动伸缩。触发弹性的条件既有 GPU 的资源使用指标,也支持用户自定义指标。伸缩节点类型支持普通 EGS 实例,也支持 ECI 实例,Spot 实例等。
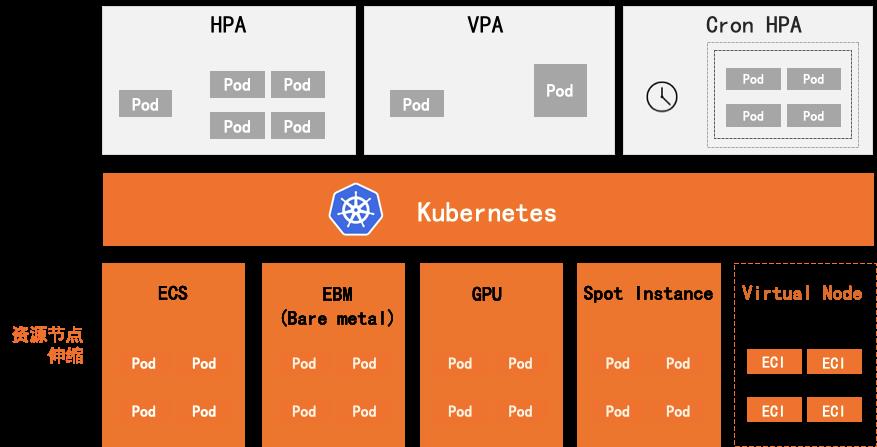
图 7:GPU 弹性伸缩
GPU 共享调度
原生 Kubernetes 仅支持以 GPU 整卡粒度为单位调度,任务容器会独占 GPU 卡。如果任务模型比较小(计算量、显存用量),就会造成 GPU 卡资源空闲浪费。云原生 AI 套件提供了 GPU 共享调度能力,可以按模型的 GPU 算力和显存需求量,将一块 GPU 卡分配给多个任务容器共享使用。这样理论上就能够用更多任务最大限度地占满 GPU 资源。
同时,为了避免共享 GPU 的多个容器之间相互干扰,还集成了阿里云 cGPU 技术,确保共享使用GPU的安全性和稳定性。容器间使用 GPU 资源是相互隔离的。不会出现超用,或者发生错误时彼此影响。
GPU 共享调度还支持多种分配策略,包括单容器单 GPU 卡共享,常用于支持模型推理场景;单容器多 GPU 卡共享,常用于开发环境中调试分布式模型训练;GPU 卡Binpack/Spread 策略,可以平衡 GPU 卡的分配密度和可用性。类似的细粒度共享调度能力也适用于 ACK 集群中的阿里自研含光 800 AI 推理芯片。
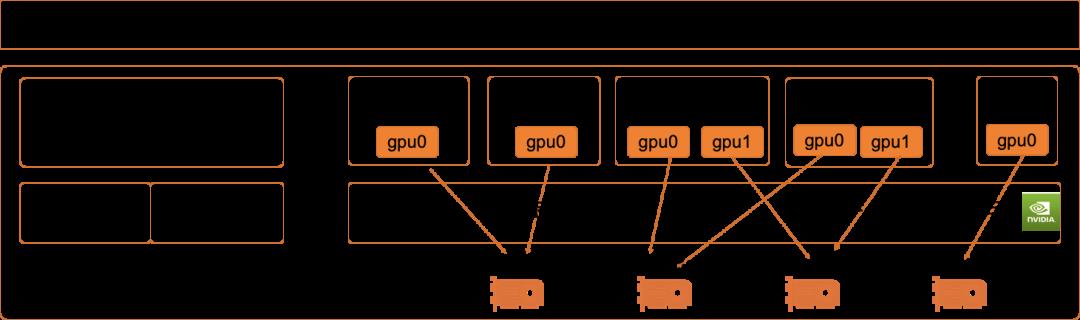
图 8:GPU 共享调度
GPU 共享调度和 cGPU 隔离对 GPU 资源利用率提升是显而易见的,已经有很多用户案例。比如某客户将数百台不同型号 GPU 实例,以显存维度统一划分池化,利用 GPU 共享调度和显存自动弹性伸缩,部署了上百种 AI 模型。既大幅度提高资源利用率,也显著降低运维复杂度。
GPU 拓扑感知调度
随着深度学习模型复杂度和训练数据量提升,多 GPU 卡分布式训练已经很非常普遍。对于使用梯度下降优化的算法,多 GPU 卡之间需要频繁传输数据,数据通信带宽往往成为限制 GPU 计算性能的瓶颈。
GPU 拓扑感知调度功能,通过获取计算节点上所有 GPU 卡间连接拓扑结构,调度器为多卡训练任务选择 GPU 资源时,根据拓扑信息考虑 NVLINK,PCIe Switch,QPI 以及 RDMA 网卡等所有互联链路,自动选择出能够提供最大通信带宽的 GPU 卡组合,避免带宽限制影响 GPU 计算效率。开启 GPU 拓扑感知调度完全是可配置的工作,对模型和训练任务代码都是零侵入的。
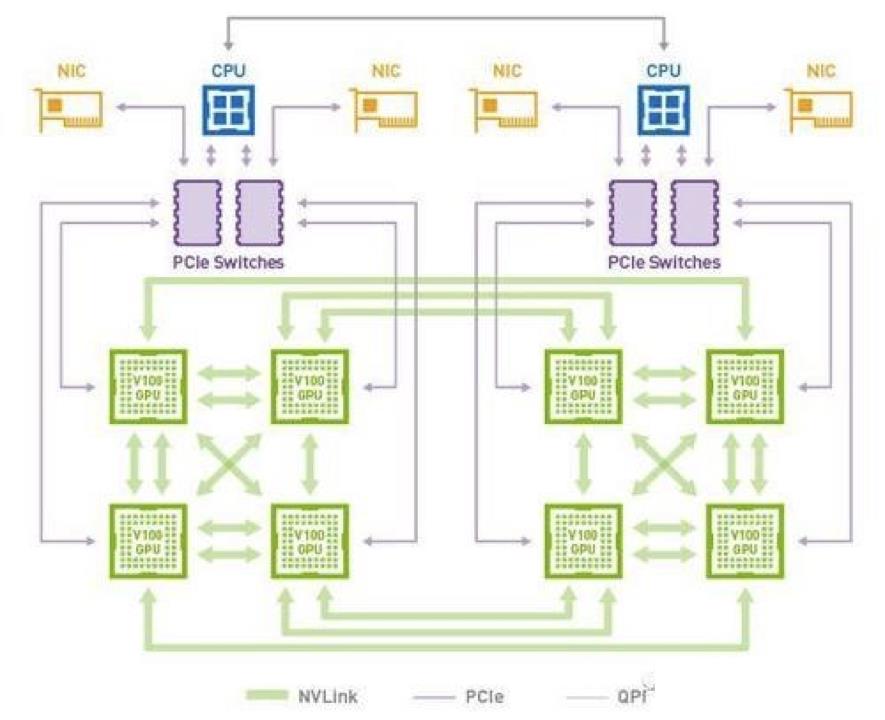
图 9:GPU 拓扑感知调度
通过与普通 Kubernetes 调度和运行多卡 GPU 分布式训练任务的性能对比,可以发现对于同样的计算引擎(如 Tensorflow,Pytorch 等)和模型任务(Resnet50, VGG16等),GPU 拓扑感知调度可以零成本带来效率提升。相较于较小的 Resnet50 模型,由于 VGG16 模型训练过程引入的数据传输量较大,更优的GPU 互联带宽对训练性能提升效果会更加明显。
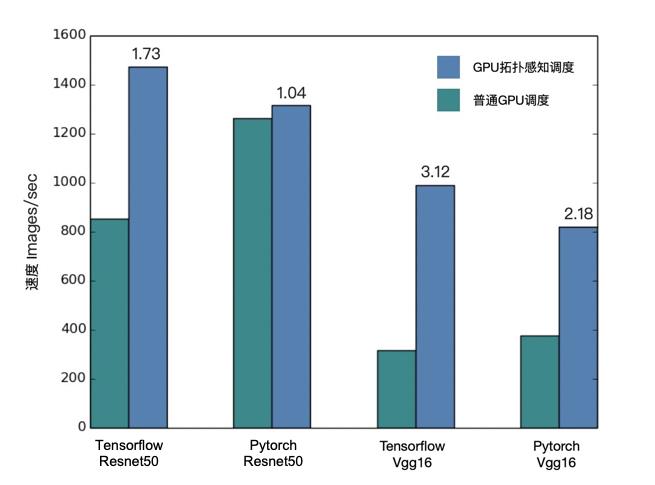
图 10:GPU 拓扑感知调度 vs 普通多卡 GPU 调度的训练性能
2、 AI 任务调度(Cybernetes)
AI 分布式训练是典型的批量任务类型。用户提交的一个训练任务(Job),在运行时一般会由一组子任务(Task)共同运行才能完成。不同AI训练框架对子任务分组有不同的策略,比如 Tensorflow 训练任务可以采用多个 Parameter Servers 子任务 + 多个 Workers 子任务的分组,Horovod 运行 Ring all-reduce 训练时,采用一个 Launcher + 多个 Workers 的策略。
在 Kubernetes 中,一个子任务一般对应一个 Pod 容器进程。调度一个训练任务,就转化为对一组,或多组子任务 Pod 容器的共同调度。这类似 Hadoop Yarn 对 MapReduce,Spark 批量作业的调度。Kubernetes 默认调度器只能以单个 Pod 容器为调度单元,无法满足批量任务调度的需求。
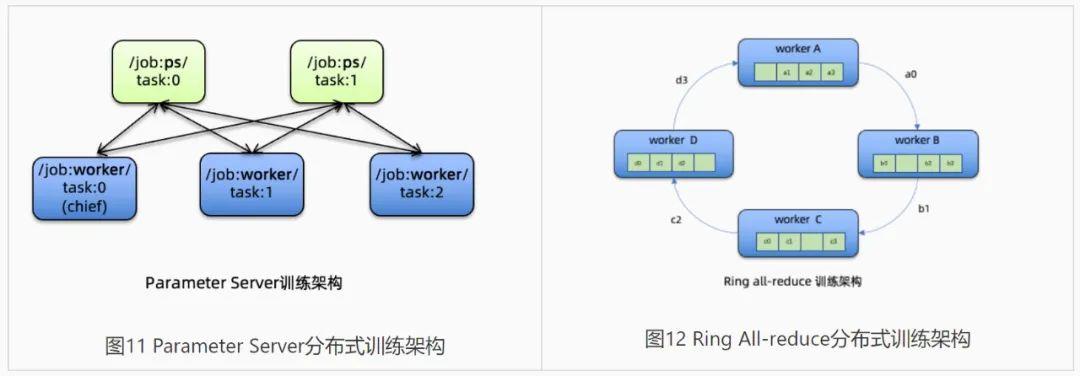
ACK 调度器(Cybernetes[7])扩展 Kubernetes 原生调度框架,实现了很多典型批量调度策略,包括 Gang Scheduling(Coscheduling)、FIFO scheduling、Capacity Scheduling、Fair sharing、Binpack/Spread 等。还增加了新的优先级任务队列,支持自定义的任务优先级管理和租户弹性资源配额控制;也可以集成 Kubeflow Pipelines 或 Argo 云原生工作流引擎,为复杂的 AI 任务提供工作流编排服务。由“任务队列+任务调度器+工作流+任务控制器”组成的架构,为基于 Kubernetes 构建批量任务系统提供了基础支撑,同时也显著提升集群整体资源利用率。
目前,云原生 AI 套件环境里不仅可以支持 Tensorflow,Pytorch,Horovod 等各种深度学习 AI 任务训练,也可以支持 Spark,Flink 等大数据任务,还能够支持 MPI 高性能计算作业。我们也将部分批量任务调度能力,贡献给了 Kubernetes 调度器上游开源项目,并持续推动社区向云原生任务系统基础架构演进。可前往 Github 了解相关项目详情:https://github.com/kubernetes-sigs/scheduler-plugins
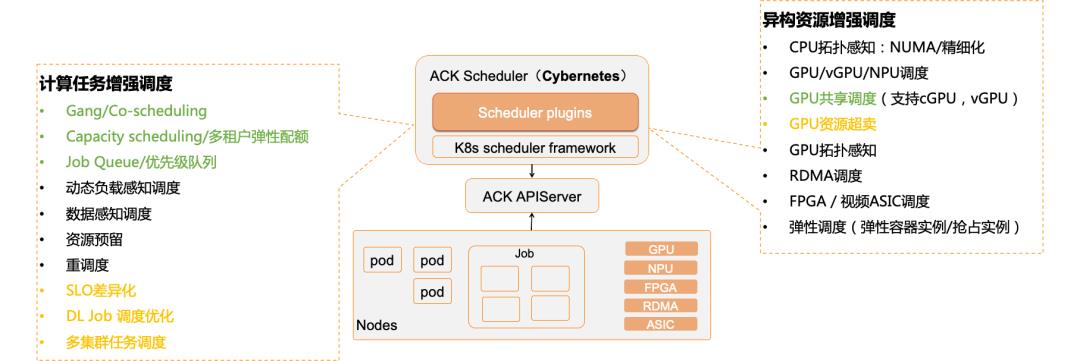
图 13:ACK Cybernetes 调度器
ACK 调度器支持的典型批量任务调度策略举例如下:
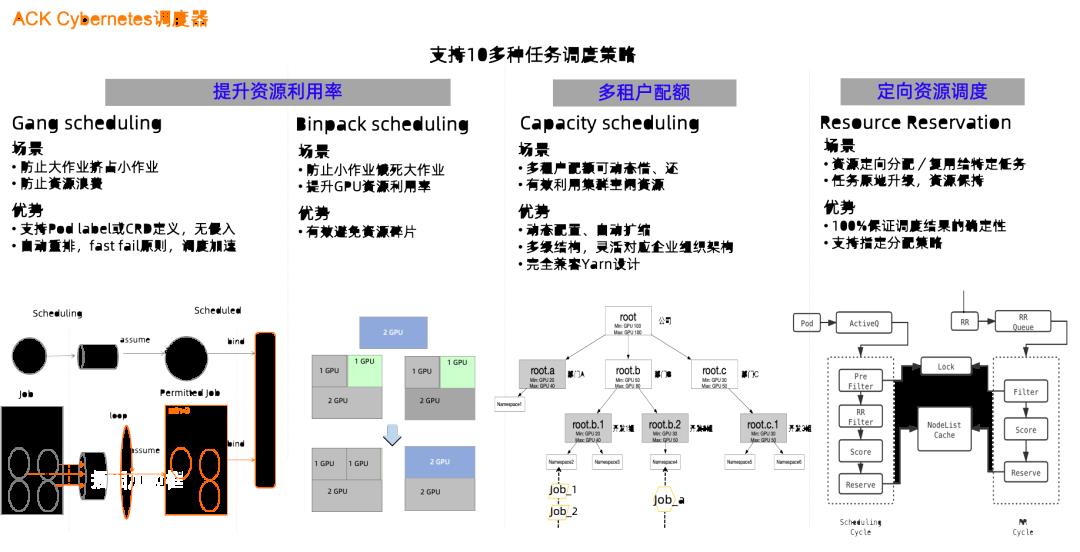
图 14:ACK 支持的典型任务调度策略
- Gang Scheduling
集群能够满足一个任务的所有子任务的需求时才为任务整体分配资源,否则不为其分配任何资源。避免由于资源死锁,导致大任务挤占小任务。
- Capacity Scheduling
通过提供弹性配额和租户队列的设置,确保在满足租户最低资源需求分配的基础上通过弹性配额共享来提升整体资源利用率。
- Binpack Scheduling
作业优先集中分配在某个节点,当节点资源不足时,依次在下一节点集中分配,适合单机多 GPU 卡训练任务,避免跨机数据传输。也可以防止大量小作业带来的资源碎片。
- Resource Reservation Scheduling
为特定作业预留资源,定向分配或者重复使用。既保证了特定作业获得资源的确定性,也加速了资源分配速度,还支持用户自定义预留策略。
3、弹性 AI 任务
弹性是云原生和 Kubernetes 容器集群最重要的基础能力。综合考虑资源状况、应用忙闲程度和成本约束,智能伸缩服务实例数和集群节点数,既要满足应用的基本服务质量,也要避免过度的云资源消费。云原生 AI 套件分别支持弹性模型训练任务和弹性模型推理服务。
弹性模型训练(Elastic Training)
支持弹性调度分布式深度学习训练任务。训练过程中可以动态伸缩子任务 worker 实例数量和节点数量,同时基本维持整体训练进度和模型精度。在集群资源空闲时,增加更多 worker 加速训练,在资源紧张时,可以释放部分 worker,保证训练的基本运行进度。这样可以极大提升集群的总体利用率,避免计算节点故障影响,同时显著减少用户提交作业之后等待作业启动的时间。
值得注意的是,弹性深度学习训练除了需要资源弹性能力外,还需要计算引擎和分布式通信框架的支持,还要算法、数据切分策略、训练优化器等多方面共同配合优化(找到最佳的方法保证 global batch size 和 learning rate 的适配),才能保证模型训练的精度目标和性能要求。目前业界还没有通用的手段,在普遍的模型上实现强复现的弹性训练。在一定约束下(模型特征,分布式训练方法,资源规模以及弹性幅度等),比如 32 卡GPU以内的 ResNet50,BERT 使用 Pytorch 和 Tensorflow 都有稳定的方法实现满意的弹性训练收益。
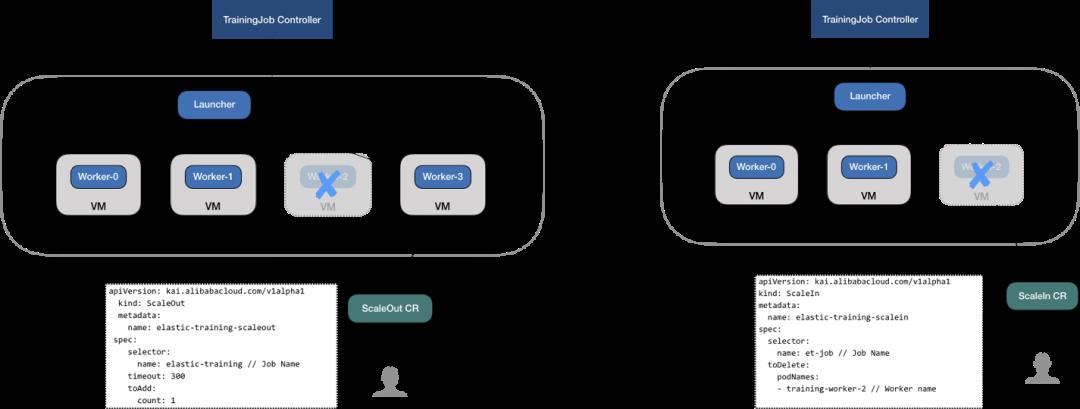
图 15:弹性 AI 训练
弹性模型推理服务(Elastic Inference)
结合阿里云丰富的资源弹性能力,充分利用包括停机不回收、弹性资源池、定时弹性、竞价实例弹性、 Spotfleet 模式等各种资源类型,自动扩缩容 AI 推理服务。在服务性能和成本之间维持较优化的平衡。
事实上,AI 模型在线推理服务的弹性,以及服务化运维,与微服务和 Web 应用是比较类似。很多云原生已有技术都可以直接用在在线推理服务上。但是 AI 模型推理依然有很多特殊之处,模型优化方法、流水线服务化、精细化的调度编排、异构运行环境适配等等方面都有专门诉求和处理手段,这里不再展开。
4、 AI 数据编排与加速(Fluid)
在云上通过云原生架构运行 AI、大数据等任务,可以享受计算资源弹性的优势,但同时也会遇到,计算和存储分离架构带来的数据访问延迟和远程拉取数据带宽开销大的挑战。尤其在 GPU 深度学习训练场景中,迭代式的远程读取大量训练数据方法会严重拖慢 GPU 计算效率。
另一方面,Kubernetes 只提供了异构存储服务接入和管理标准接口(CSI,Container Storage Interface),对应用如何在容器集群中使用和管理数据并没有定义。在运行训练任务时,数据科学家需要能够管理数据集版本、控制访问权限、数据集预处理、加速异构数据读取等。但是在 Kubernetes 中还没有这样的标准方案,这是云原生容器社区缺失的重要能力之一。
ACK 云原生 AI 套件对“计算任务使用数据的过程”进行抽象,提出了弹性数据集 Dataset 的概念,并作为“first class citizen”在 Kubernetes 中实现。围绕弹性数据集 Dataset,ACK 创建了数据编排与加速系统 Fluid,来实现 Dataset 管理(CRUD 操作)、权限控制和访问加速等能力。
Fluid 可以为每个 Dataset 配置缓存服务,既能在训练过程中将数据自动缓存在计算任务本地,供下轮迭代计算,也能将新的训练任务调度到已存在 Dataset 缓存数据的计算节点上运行。再加上数据集预热、缓存容量监控和弹性伸缩,可以大大降低任务远程拉取数据的开销。Fluid 可以将多个不同类存储服务作为数据源(比如 OSS,HDFS)聚合到同一个 Dataset 中使用,还可以接入不同位置的存储服务实现混合云环境下的数据管理与访问加速。
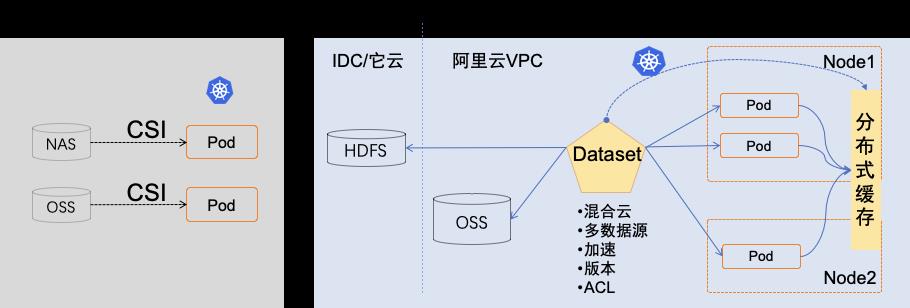
图 16:Fluid Dataset
算法工程师在 AI 任务容器中使用 Fluid Dataset 与在 Kubernetes 中使用 PVC(Persistent Volume Claim)的方式类似,只需在任务描述文件中指定 Dataset 的名字,并作为 volume 挂载到容器中任务读取数据的路径即可。我们希望为训练任务增加 GPU 资源,能近乎线性地加快模型的训练速度。但往往受限于更多 GPU 并发拉取 OSS bucket 的带宽限制,单纯增加 GPU 并不能有效提速训练。通过使用 Fluid Dataset 的分布式缓存能力,有效化解了远程并发拉数据的性能瓶颈,使得分布式训练扩展 GPU 获得更好的加速比。
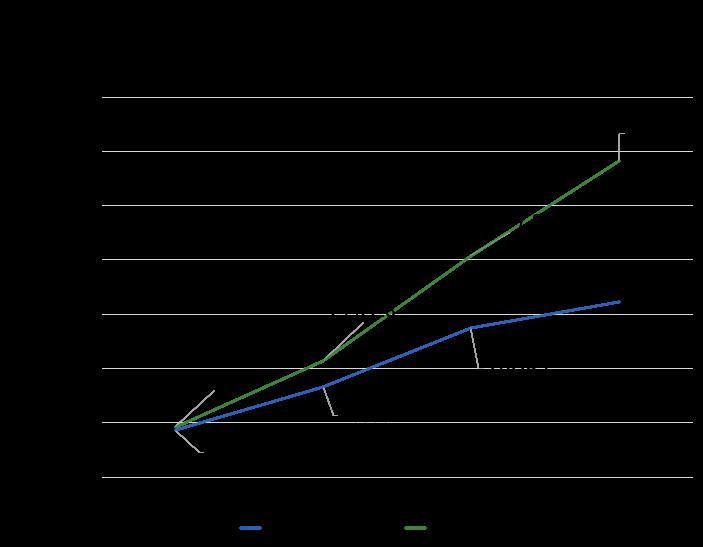
图 17:Fluid 分布式缓存加速模型训练性能对比
ACK 团队联合南京大学、Alluxio 公司,共同发起了 Fluid 开源项目[8],并托管为 CNCF 沙箱项目,希望能与社区一起推动云原生数据编排和加速领域的发展和落地。Fluid 的架构可以通过 CacheRuntime plugin 的方式,扩展兼容多种分布式缓存服务。目前已经支持了阿里云 EMR 的 JindoFS,开源的 Alluxio,Juicefs 等缓存引擎。无论在开源社区共建,还是云上用户落地都取得了不错的进展。
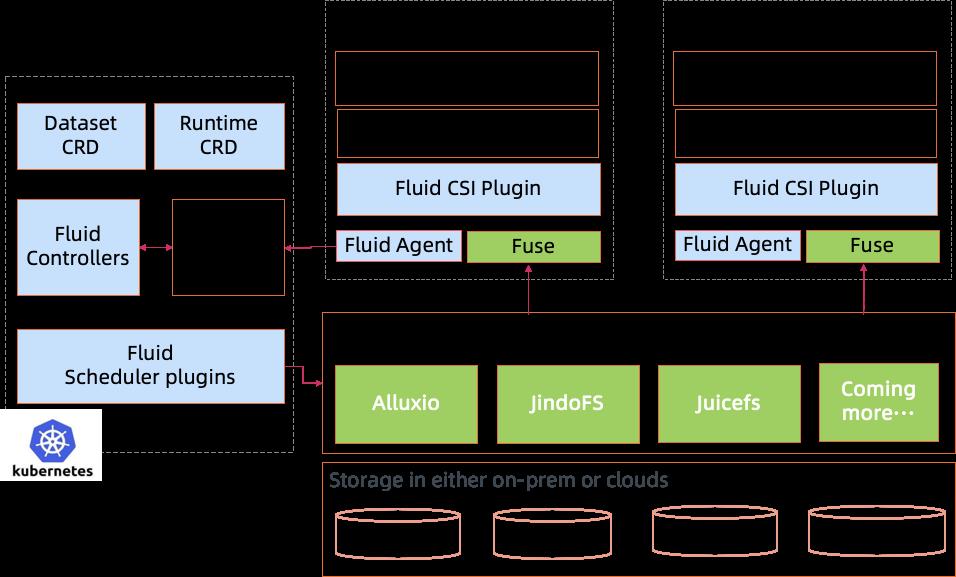
图 18:Fluid 系统架构
Fluid 云原生数据编排和加速的主要能力包括:
- 通过数据亲和性调度和分布式缓存引擎加速,实现数据和计算之间的融合,从而加速计算对数据的访问。
- 将数据独立于存储进行管理,并且通过 Kubernetes 的命名空间进行资源隔离,实现数据的安全隔离。
- 将来自不同存储的数据联合起来进行运算,从而有机会打破不同存储的差异性带来的数据孤岛效应。
5、AI 作业生命周期管理(Arena)
ACK 云原生 AI 套件提供的所有组件都以 Kubernetes 标准接口(CRD)和 API 形式,交付给 AI 平台开发运维人员调用。这对基于 Kubernetes 构建云原生 AI 平台来说是非常方便和易用的。
但对于数据科学家和算法工程师开发训练 AI 模型来说,Kubernetes 的语法和操作却是一种“负担”。他们更习惯在 Jupyter Notebook 等 IDE 中调试代码,使用命令行或者 Web 界面提交、管理训练任务。任务运行时的日志、监控、存储接入、GPU 资源分配和集群维护,最好都是内置的能力,使用工具就可以简单操作。
对于 AI 服务的生产过程,主要包含数据准备与管理、模型开发构建、模型训练、模型评测、模型推理服务上线运维等阶段。这些环节以循环迭代的方式,根据线上数据变化,持续优化更新模型,通过推理服务将模型发布到线上,收集到新的数据,进入下一轮迭代。
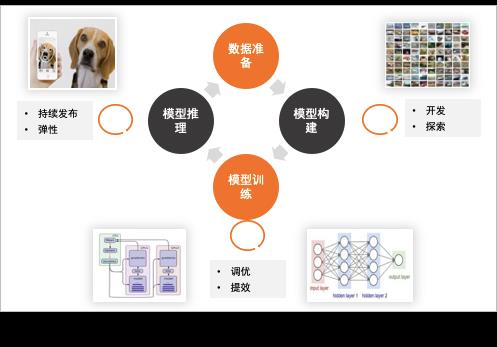
图 19:深度学习 AI 任务生命周期
云原生 AI 套件将这个生产过程中的主要工作环节进行抽象,并以命令行工具 Arena[9] 实现管理。Arena 完全屏蔽了底层资源和环境管理,任务调度,GPU 分配和监控的复杂性,兼容主流 AI 框架和工具,包括 Tensorflow, Pytorch, Horovod, Spark, JupyterLab, TF-Serving, Triton 等。
除了命令行工具,Arena 还支持 golang/java/python 语言 SDK,便于用户二次开发。另外,考虑到不少数据科学家习惯使用 Web 界面管理资源和任务,云原生 AI 套件也提供了简单的运维大盘和开发控制台,满足用户快速浏览集群状态、提交训练任务的需要。这些组件共同形成了云原生 AI 作业管理工具集 Arena。
Kubeflow[10] 是 Kubernetes 社区中支持机器学习负载的主流开源项目。Arena 已经内置 Kubeflow 的 TensorflowJob,PytorchJob,MPIJob 任务控制器,以及开源的 SparkApplication 任务控制器,也可以集成 KFServing,Kubeflow Pipelines 项目。用户在 ACK 集群中无需单独安装 Kubeflow,只需要使用 Arena 即可。
值得一提的是,ACK 团队早期也将 arena 命令行和 SDK 工具贡献到了 Kubeflow 社区,有很多企业用户通过扩展、封装 arena,构建了自己的 AI 平台 MLOps 流程和体验。
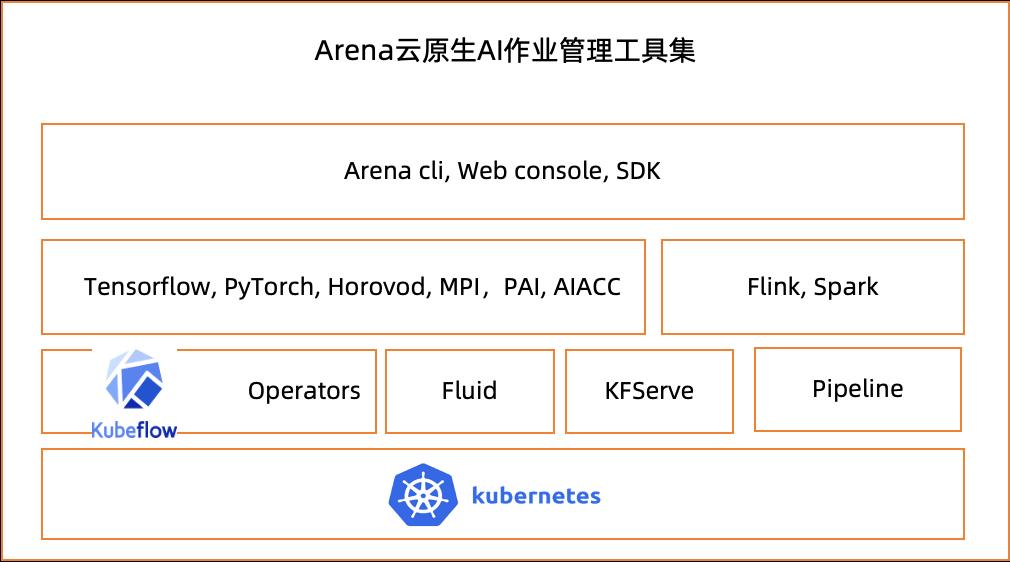
图 20:Arena 架构
云原生 AI 套件主要为以下两类用户解决问题:
- AI 开发人员,如数据科学家和算法工程师
- AI 平台运维人员,如 AI 集群管理员
AI 开发人员可以使用 arena 命令行或者开发控制台 Web 界面,创建 Jupyter notebook 开发环境,提交和管理模型训练任务,查询 GPU 分配情况,实时查看训练任务日志、监控和可视化数据,对比评测不同模型版本,并将选出的模型部署到集群,还可以对线上模型推理服务进行 AB 测试、灰度发布、流控和弹性伸缩。
# 提交Tensorflow分布式训练任务
arena submit mpijob
--name=tf-dist-data --workers=6 --gpus=2 --data=tfdata:/data_dir \\
--env=num_batch=100 --env=batch_size=80 --image=ali-tensorflow:gpu-tf-1.6.0 \\
"/root/hvd-distribute.sh 12 2”
# 查看训练任务状态 arena get tf-dist-data NAME STATUS TRAINER AGE INSTANCE NODE tf-dist-data RUNNING tfjob 3d tf-dist-data-tfjob-ps-0 192.168.1.120 tf-dist-data SUCCEEDED tfjob 3d tf-dist-data-tfjob-worker-0 N/A tf-dist-data SUCCEEDED tfjob 3d tf-dist-data-tfjob-worker-1 N/A Your tensorboard will be available on: 192.168.1.117:32594
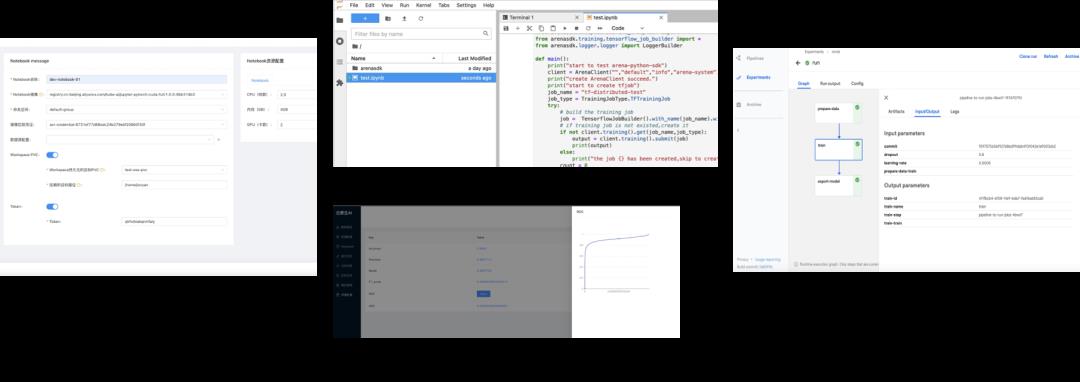
图 21:Arena 开发控制台
AI 集群管理员可以使用 Arena 运维大盘了解和管理集群资源、任务 ,配置用户权限、租户配额以及数据集管理等。
图 22:Arena 运维大盘
用户案例
云原生 AI 套件在早期公测时已经获得不少用户的兴趣和测试。用户行业包括了互联网、在线教育、自动驾驶等 AI 重度用户。这里分享两个代表性用户案例。
- 微博
微博深度学习平台[11]借助 Kubernetes 混合云集群,统一管理阿里云上的 GPU 实例和 IDC 内的资源。
通过异构资源调度、监控和弹性伸缩能力,统一管理大量 GPU 资源。利用 GPU 共享调度能力,在 AI 模型推理服务场景大幅提升 GPU 利用率。
通过封装 Arena,定制开发了微博自己的 AI 任务管理平台,将所有深度学习训练任务集中管理,工程效率获得 50% 提升。
通过使用 AI 任务调度器,实现大规模 Tensorflow 和 Pytorch 分布式训练任务的高效调度。
通过使用 Fluid + EMR Jindofs 分布式缓存能力,尤其是针对 HDFS 中的海量小文件缓存优化,把 Pytorch 分布式训练任务端到端速度提升了数倍。用户测试极端情况下,训练时长从两周缩短到 16 小时[12]。
- 毫末智行
毫末智行是长城汽车投资的智能驾驶明星创业公司。毫末很早期就启动了基于云原生技术构建统一 AI 工程平台的工作。毫末首先使用 Kubeflow, arena 工具集,GPU 统一调度等能力构建起自己的机器学习平台。进而集成了 Fluid+JindoRuntime,显著提升了云端训练和推理的效率,尤其是一些小模型,在云端做训练和推理 JindoRuntime 可以有效解决 IO 瓶颈问题,训练速度最高可提升约 300% 。同时也大幅度提升云端 GPU 使用效率,加速了在云端数据驱动的迭代效率。
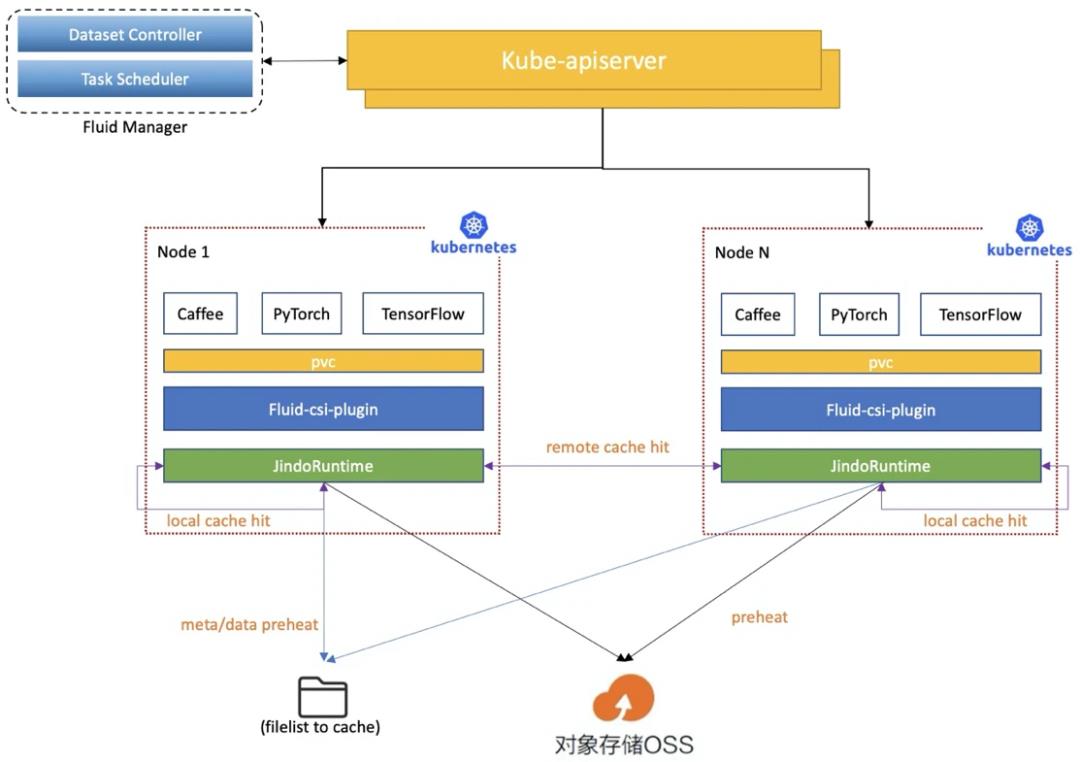
图 23:毫末智行 AI 平台使用 Fluid 数据集加速分布式 GPU 训练
毫末智行不仅分享了基于 ACK 的云原生 AI 在自动驾驶领域的应用探索与落地实践[13],也会和 Fluid 等云原生 AI 社区一起共建,计划进一步加强:
- 支持定时任务支持动态扩缩容
- 提供性能监控控制台
- 支持规模化 Kubernetes 集群中多数据集的全生命周期管理
- 支持对缓存数据和缓存元数据的动态删减
展望
企业 IT 转型大潮中对数字化和智能化的诉求越来越强烈,最突出的需求是如何能快速、精准地从海量业务数据中挖掘出新的商业机会和模式创新,以更好应对多变、不确定性的市场挑战。AI 人工智能无疑是当下和未来帮助企业实现这一目标最重要的手段之一。显然,如何持续提升 AI 工程效率,优化 AI 生产成本,不断降低 AI 门槛,实现 AI 能力普惠,具有很大的现实价值和社会意义。
我们清晰地看到,云原生在分布式架构、标准化 API 和生态丰富度上的优势,正在迅速成为用户高效使用云计算的新界面,来帮助业务提升服务敏捷性和可扩展性。越来越多用户也在积极探索如何基于云原生容器技术,提升 AI 服务的生产效率。进而利用同一套技术堆栈支撑企业内部各种异构工作负载。
阿里云 ACK 提供云原生 AI 套件产品,从底层异构计算资源,AI 任务调度,AI 数据加速,到上层计算引擎兼容和 AI 作业生命周期管理,全栈支撑 AI 生产和运维过程。以简洁的用户体验,可扩展的架构,和统一优化的产品实现,加速用户定制化构建云原生 AI 平台的进程。我们也将部分成果分享到社区,以共同推动云原生 AI 领域的发展和落地。
本文为阿里云原创内容,未经允许不得转载。
以上是关于摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台的主要内容,如果未能解决你的问题,请参考以下文章
如何基于EasyCVR视频能力与AI技术助力工业园区智能管理?