SQL 求 3 列异值的 4 种方法
Posted dbLenis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL 求 3 列异值的 4 种方法相关的知识,希望对你有一定的参考价值。

点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长
前两天在抽一段数据时,碰到一个典型问题,初一想,有很多解法,所以特想做一次归纳。
回想往事,其实有好些想法,可以深究,因没及时记录,事后就再也想不起来,白白浪费好多这样的机会。
所以为了不留遗憾,今天沉下心来,好好复盘下。
问题的原型,大概是这样的:一张表,有三列数据,表示了同一个维度的数据。
表结构大约是这样的:
CREATE TABLE `tianchi_mobile_user_stage` (
`user_id` varchar(50) DEFAULT NULL,
`app_user_id` varchar(50) DEFAULT NULL,
`global_user_id` varchar(50) DEFAULT NULL,
`item_id` int DEFAULT NULL,
`behavior_type` int DEFAULT NULL,
`user_geohash` varchar(1024) DEFAULT NULL,
`item_category` int DEFAULT NULL,
`time` varchar(1024) DEFAULT NULL,
`crc64_user_id` int DEFAULT NULL,
`crc64_user_id_2` bigint DEFAULT NULL,
`crc64_user_id_3` bigint unsigned DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;其中,user_id, app_user_id, global_user_id 这三列,是互相包含的。即,我中有你,你中有我。但其中有一列,数据最全。现在,需要找到这一列,单抽出来做维度。
粗粗地看,很简单,就是个排列组合的问题,俩俩对比,用 6 组,就能求解出来。求解的最佳方法,有两个要求:快和准。
任何数据模型,放到大数据量背景下(这张表大约有 400多万的数据),都会变得不简单。不管如何,还是先做出来,再追求最优解。
于是,我马上能想到的两个方法,就是 Left Join 和 Not IN( 很遗憾,mysql 8 了,都还不支持 Except)
先看 Left Join 怎么写:
SELECT user.user_id
FROM tianchi_mobile_user_stage user
LEFT JOIN tianchi_mobile_user_stage app_user
on app_user.app_user_id = user.user_id
WHERE app_user.app_user_id IS NULL
;假使有结果,证明 user_id 比 app_user_id 多出一些。于是,就像冒泡算法一样,user_id 成为最有可能的候选列。
但是,等等。这能说明 user_id 包含了所有的 app_user_id 吗,恐怕不能。这只能说明,user_id 中,有部份人不在 app_user_id中,要证明 user_id 数据最全,还需要反证,app_user_id 中的人,全部都在 user_id 中。
于是求解如下:
SELECT app_user.app_user_id
FROM tianchi_mobile_user_stage app_user
LEFT JOIN tianchi_mobile_user_stage user
on user.user_id = app_user.app_user_id
WHERE user.user_id IS NULL
;未有结果,可证明,app_user_id 的人,全部都在 user_id 中,确实没漏。
但,要对比这剩下的几组,每次都靠人眼来查找,似乎有些累眼睛。于是,省去互相包含的那部份数据,并选择 一条不包含的即可:
SELECT user.user_id
FROM tianchi_mobile_user_stage user
LEFT JOIN tianchi_mobile_user_stage app_user
on app_user.app_user_id = user.user_id
WHERE app_user.app_user_id IS NULL
LIMIT 1
;这样,user_id, app_user_id, global_user_id 互相对比,顶多 6 次,即找出最全的那列。
但是等等,400多万数据,会不会太慢呢?那几乎是肯定的,因为我去剥了颗开心果回来,界面还是这样的:

于是我看了下执行计划:
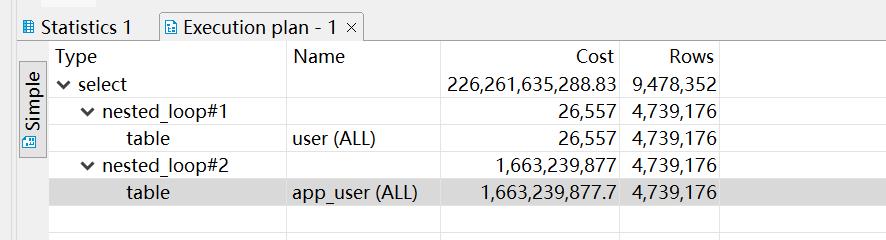

走了表扫,还用了 Hash Join 算法。显然要给三个列,分别加一个单列索引:
create index idx_user_id on tianchi_mobile_user_stage (user_id);
create index idx_app_user_id on tianchi_mobile_user_stage (app_user_id);
create index idx_global_user_id on tianchi_mobile_user_stage (global_user_id);想着可能对其他的方案也有用,就把索引留着,等完工了再删。
等建完索引,我又发现一个可以优化的地方。在本题中,只需找出散值(即每列的单值)的差异即可,完全没必要把整张表的数据,都拉出来。因为 user_id 肯定会有重复值嘛。
于是,将 SQL 语句改写如下:
SELECT
user_1.user_id,user_2.app_user_id
FROM
(
SELECT
distinct user.user_id as user_id
FROM
tianchi_mobile_user_stage user ) user_1
LEFT JOIN (
SELECT
DISTINCT app_user.app_user_id
FROM
tianchi_mobile_user_stage app_user ) user_2
on
user_2.app_user_id = user_1.user_id
WHERE
user_2.app_user_id IS NULL
LIMIT 1
;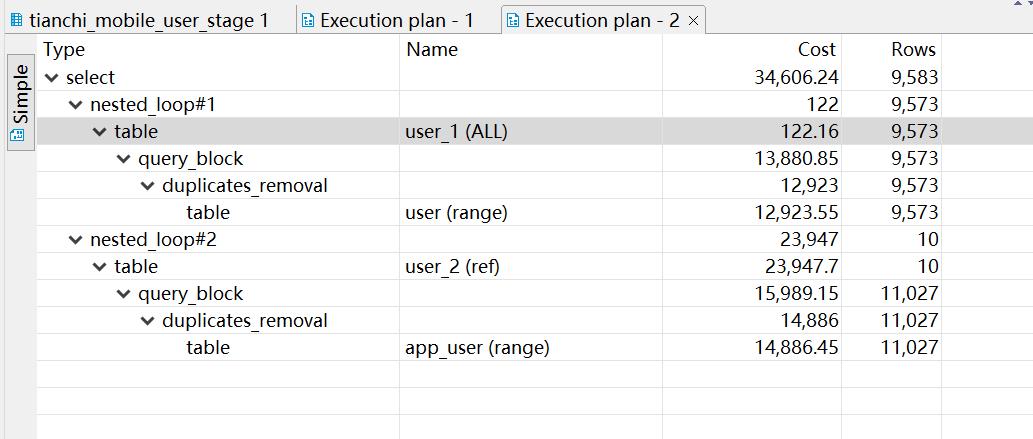
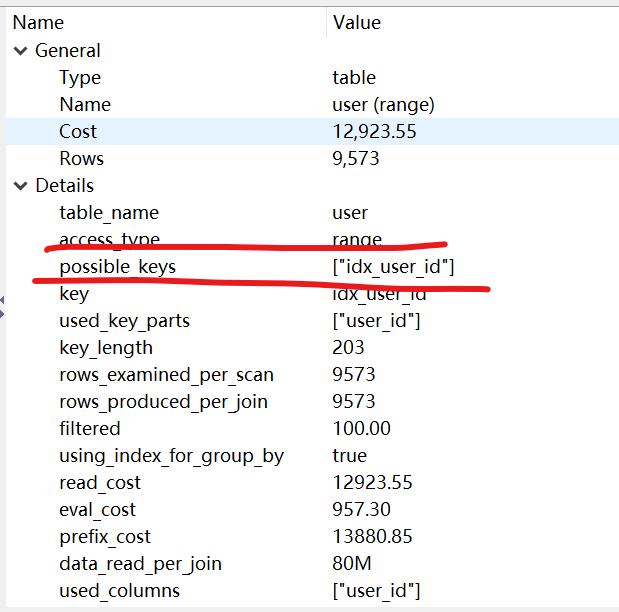
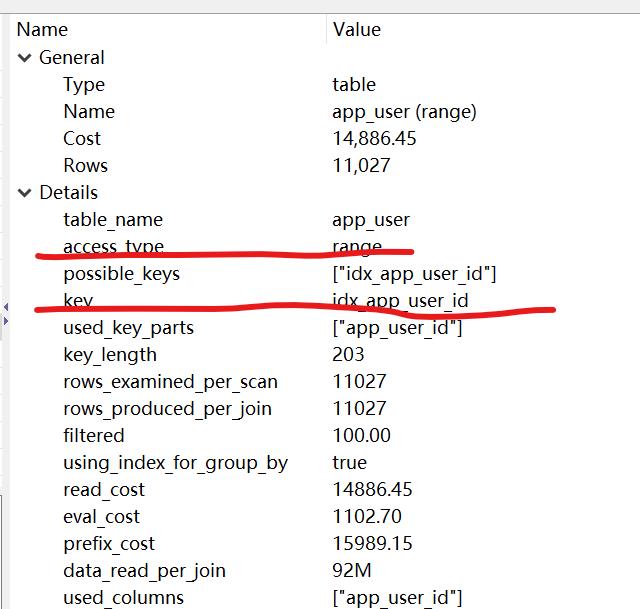
从执行计划看出,表扫变索引查找,而数据量也下降了 400倍,执行时间秒出。
那么,同样的思路,再用 NOT IN 来试下:
SELECT
distinct user.user_id as user_id
FROM
tianchi_mobile_user_stage user
WHERE user.user_id NOT IN (
SELECT
DISTINCT app_user.app_user_id
FROM
tianchi_mobile_user_stage app_user
)
LIMIT 1 ;由于有了之前的索引,这次的查询也快很多
但是,上面的做法,太过于繁琐,有没有什么方法,可以一次性就知道,这三列到底有没有差别呢?于是我又想到了两个方法:count 和 checksum 聚合
要对比这三列有没有不同,最简单的就是计算三列的总数。如果 user_id 有 400万,app_user_id 有 300万,global_user_id 有 200万,那么毋庸置疑,user_id 就是最全的。并且这种方法,只走一边全表扫描,效率应该没问题。
SELECT COUNT(DISTINCT user_id) as user_id_cnt
,COUNT(DISTINCT app_user_id) as app_user_id_cnt
,COUNT(DISTINCT global_user_id) as global_user_id_cnt
FROM tianchi_mobile_user_stage ;


事实证明,效果显著,性能拉胯。
虽然,count 值一样,两列包含的数据,就绝对一样了吗,答案是否定的。假设,user_id, app_user_id 各包含 400万数据。其中 app_user_id 有 200万数据,是可以在 user_id 找到的,而另外 200万,并不在 user_id 中。总数相等,但还是有区别的。
于是,我又想到了一种方案,那就是求 CRC 的总和。CRC 方法,简单来说,就是求每个 user id 的哈希值,然后求和。若和一致,则说明两列包含了相同的散值。
我之前提过一篇文章讲 CRC,详细的用法在这篇文章里:
|SQL中的数据检验, CRC or MD5?
在这里,涉及到的数据量比较大,MySQL 自带的 CRC32 发生的重合率比较大,因此换用 CRC64.
注意:使用 CRC64 函数,必须安装 common_schema
MySQL.com
由此,又产生了一种解法:
select 'user_id' as category,sum(common_schema.crc64( user_id)) as user_id_crc64
from (
select distinct user_id
from tianchi_mobile_user_stage tmu
) tmp
union all
select 'app_user_id' as category, sum(common_schema.crc64( app_user_id)) as user_id_crc64
from (
select distinct app_user_id
from tianchi_mobile_user_stage tmu
) tmp
union all
select 'global_user_id' as category,sum(common_schema.crc64( global_user_id)) as user_id_crc64
from (
select distinct global_user_id
from tianchi_mobile_user_stage tmu
) tmp ;
而且,看执行计划,也都是走了索引,执行效率满意
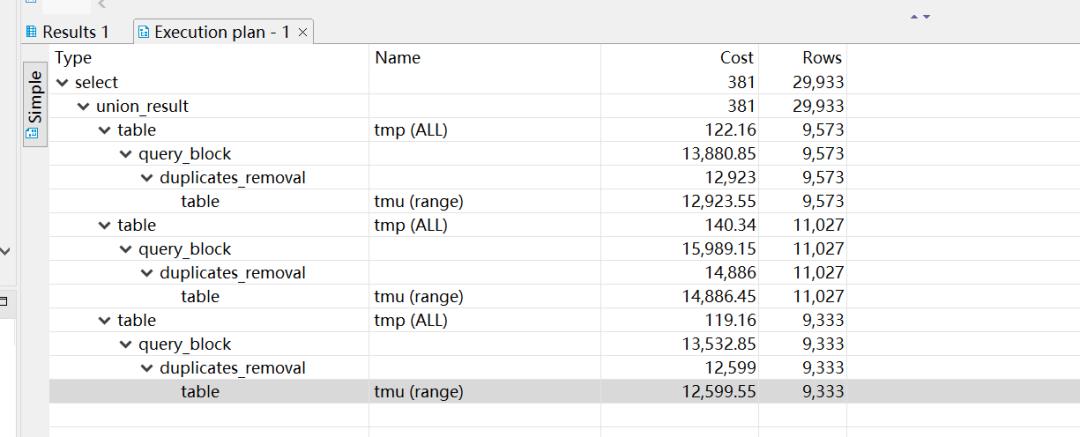
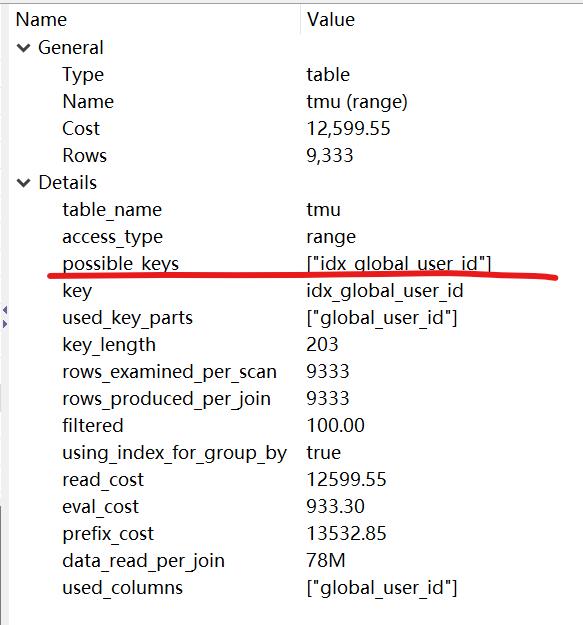
由此可知,user_id 和 global_user_id 拥有相同的散值,而 app_user_id 有异值。而求两列异值,最快的方法,由上可知,便是Left Join 求 Null,
并且只要有一条数据存在,就足以说明集合的包含关系.
因此综合本次经验,要完美的解决这个问题,需要两种方案并行:
- CHECKSUM 求和(本例采用 CRC64 算法)
- 集合求差
HOHO~~ 写出来,果然舒服多了!
--完--
往期精彩:

以上是关于SQL 求 3 列异值的 4 种方法的主要内容,如果未能解决你的问题,请参考以下文章
第05题给定 n,求 1 × 2 × 3 × ... × n 的乘积 | 两种解法