数模算法-随机森林
Posted Eric%258436
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数模算法-随机森林相关的知识,希望对你有一定的参考价值。
** 如有错误,感谢指正**
如有错误,感谢指正,请私信博主,有辛苦红包,拜“一字之师”。
请根据目录寻找自己需要的段落
导语:本博客为个人整理MATLAB学习记录帖,如有错误,感谢指正。系统学习,欢迎持续关注,后续陆陆续续更新
Java 交流qq群 383245788
序
本文旨在记录个人数模美赛备赛经历。转载请注明出处。
Ensemble Learning

集成学习原理图
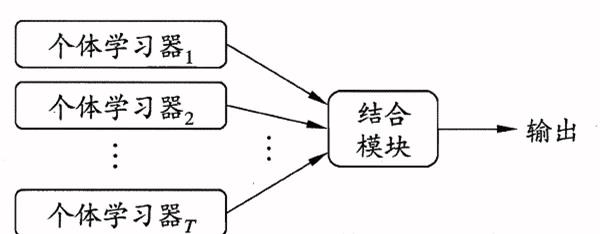 集成学习法的优点:
集成学习法的优点:
1.将多个分类方法聚集在-起,以提高分类的准确率。(这些算法可以是不同的算法,也可以是相同的算法。)
2.集成学习法由训练数据构建一-组基分类器, 然后通过对每个基分类器的预测进行投票来进行分类
3.严格来说,集成学习并不算是一 种分类器,而是一 -种分类器结合的方法。
4.通常一个集成分类器的分类性能会好于单个分类器
5.如果把单个分类器比作一个决策者的话 ,集成学习的方法就相当于多个决策者共同进行同一项决策。
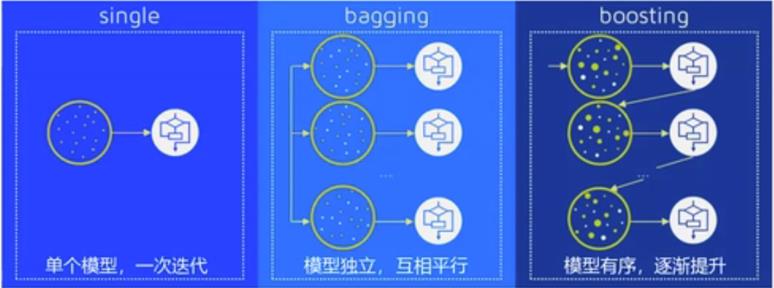
集成学习的两大算法:
Boosting
bagging与随机森林
Bagging(装袋法):每个模型相互独立,相互平行。然后对其预测结果进行平均或者多数表决的原则来决定集成评估器的结果
Boosting(提升法):模型循序渐进,依次增强。基评估器是相关的,是按顺序一-构建的, 其核心思想是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。
Bootstrap Sampling
在现实任务中,个体学习器是为解决同一个问题训练出来的,它们之间是不可能完全独立的,虽然“独立"在现实任务中无法做到,但可以设法使基学习器尽可能的具有较大的差异,由此我们引入了自助采样法(Bootstrap sampling)
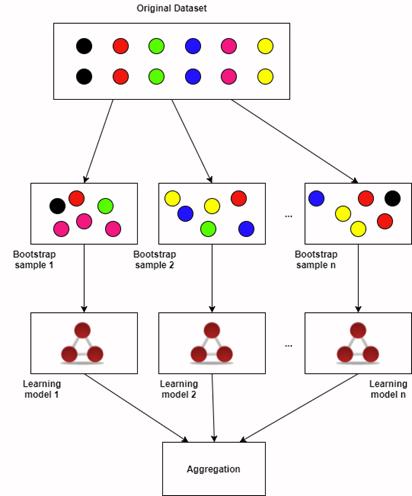
步骤
1.在原有的样本中通过重抽样抽取-定数量(比如100) 的新样本,重抽样(Re-sample) 的意思就是有放回的抽取,即一个数据有可以被重复抽取超过一次。
2.基于产生的新样本,计算我们需要估计的统计量。
3.重复上述步骤n次(一般是n> 1000次)
决策树概念
决策树算法相比于K-means等分类算法,优点在于能够理解数据中所蕴涵的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列的规则,这些机器根据数据集创建规则的过程,就是机器学习的过程。
决策树主要功能是从一张有特征和标签的表格中, 通过对特定特征进行提问,为我们总结出一系列决策规则,并用树状图来呈现这些决策规则。
决策树的构建
划分数据集最大的原则:将无序的数据变得更加有序
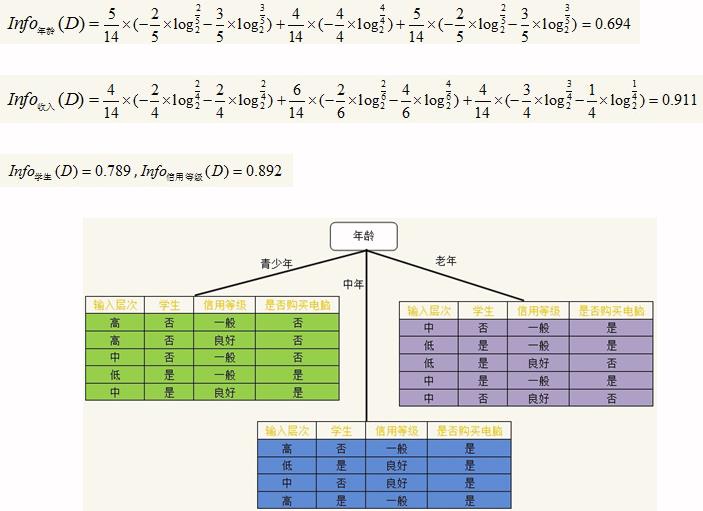
在划分数据集前后信息发生的变化成为信息增益(information gain), 知道如何计算信息增益,我们就可以计算每一个特征划分数据集后获得的信息增益, 获得信息增益最高的特征是最好的选择。

demo
随机森林
随机森林重要是"随机"
1、 训练数据的随机选取
2、待选特征的随机选取
举例说明:对于一个测试数据, 将它投入到我们用于分类的随机森林中,每棵树对其会产生不同的测试结果,最后依据少数服从多数的原则选择最终测试结果。
解释:
随机森林算法就是一个分类算法。对原始训练样本进行随机重复放回抽样,获得诸多样本,对样本进行处理,得到一个个树,对树进行处理,得到一个个分类树,最后根据少数服从多数的操作得到最终结果。
遇事不决就百度解决,会用就行,cv大法。
用python解决数模问题比较简单,不需要自己调参,用最简单的默认参数就可以了。
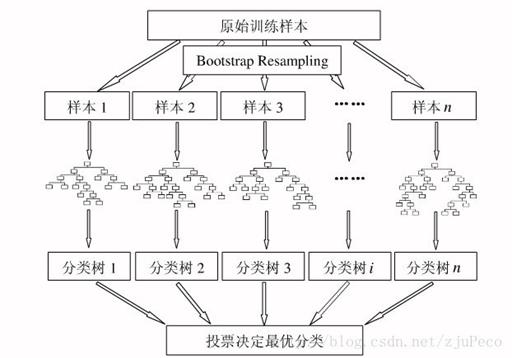
随机森林的优缺点
优点
- 由于采用了集成算法,本身精度比大多数单个算法要好,所以准确性高
- 在测试集.上表现良好,由于两个随机性的引入,使得随机森林不容易陷入过拟合(样本随机,特征随机)
- 由于两个随机性的引入,使得随机森林具有一定的抗噪声能力,对比其他算法具有一定优势
缺点
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会比较大
- 随机森林中还有许多不好解释的地方,有点算是黑盒模
- 在某些噪音比较大的样本集上,RF的模型容易陷入过拟合
随机森林demo
现有一组鸢尾花数据集(含有训练集与测试集),格式如下图,列名分别为#花萼长度(sepal length)、花萼宽度(sepalwidth) 、花瓣长度(petal length)、花瓣宽度(petal width),以及品种和是否为训练集。
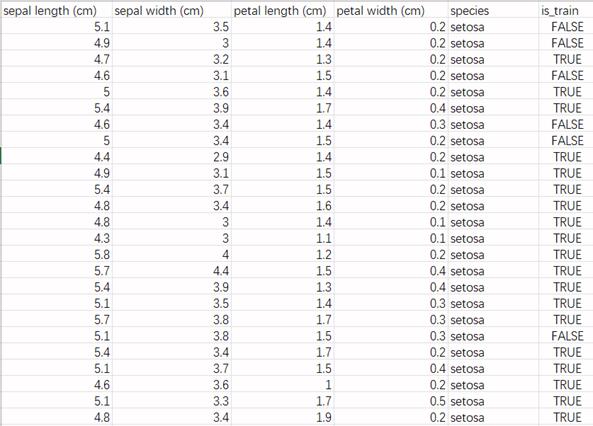
python代码实现
from sklearn.datasets import load_ iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_ iris()
df = pd.DataFrame(iris.data, columns=iris.feature_ names)
df['is_ train'] = np.random.uniform( low= 0 ,high= 1, size = len(df)) <= .75
df['species'] = pd.Categorical.from codes(iris.target, iris.target_ names)
train, test = df[df[is_ train']= = True], df[df['is_ train']= = False]
features = df.columns[:4]
clf = RandomForestClassifier()
y, _ = pd.factorize(train['species'])
cl.fit(train[features], y)
clf.predict(test[features])
predicts = iris.target names[clf.predict(test[features])]
print(pd.crosstab(test['species'], predicts, rownames=['actual'], colnames= ['predicts']))
# https://scikit-learn.org/stable/modules/generated/sklearn. ensemble .RandomForestClassifier.html
以上是关于数模算法-随机森林的主要内容,如果未能解决你的问题,请参考以下文章