数据结构-集成算法-随机森林
Posted 辉常努腻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构-集成算法-随机森林相关的知识,希望对你有一定的参考价值。
数据结构-集成算法-随机森林 [内附spark-ml代码]
随机森林
集成模型指将基础模型组合成为一个模型。Spark 支持两种主要的集成算法:随机森林和梯度提升树。
集成算法
集成学习(ensemble learning)
- 是目前非常流行的机器学习策略,基本上所有问题都可以借用其思想来得到效果上的提升。基本出发点就是把算法和各种策略集中在一起,说白了就是一个搞不定大家一起上!集成学习既可以用于分类问题,也可以用于回归问题,在机器学习领域会经常看到它的身影,本章就来探讨一下几种经典的集成策略,并结合其应用进行通俗解读。
Bagging算法
- 集成算法有3个核心的思想:bagging、boosting和stacking,这几种集成策略还是非常好理解的,下面向大家逐一介绍。
并行的集成
- Bagging即boostrap aggregating,其中boostrap是一种有放回的抽样方法,抽样策略是简单的随机抽样。其原理很直接,把多个基础模型放到一起,最后再求平均值即可,这里可以把决策树当作基础模型,其实基本上所有集成策略都是以树模型为基础的,公式如下:

首先对数据集进行随机采样,分别训练多个树模型,最终将其结果整合在一起即可,思想还是非常容易理解的,其中最具代表性的算法就是随机森林。
随机森林是机器学习中十分常用的算法,也是bagging集成策略中最实用的算法之一。那么随机和森林分别是什么意思呢?森林应该比较好理解,分别建立了多个决策树,把它们放到一起不就是森林吗?这些决策树都是为了解决同一任务建立的,最终的目标也都是一致的,最后将其结果来平均即可,如图所示

随机森林的特点
我们前边提到,随机森林是一种很灵活实用的方法,它有如下几个特点:
- 在当前所有算法中,具有极好的准确率 It is unexcelled in accuracy among current algorithms;
- 能够有效地运行在大数据集上 It runs efficiently on large data bases;
- 能够处理具有高维特征的输入样本,而且不需要降维 It can handle thousands of input variables without variable deletion;
- 能够评估各个特征在分类问题上的重要性 It gives estimates of what variables are important in the classification;
- 在生成过程中,能够获取到内部生成误差的一种无偏估计 It generates an internal unbiased estimate of the generalization error as the forest building progresses;
- 对于缺省值问题也能够获得很好得结果 It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing
随机森林的相关基础知识
1.信息、熵以及信息增益的概念
这三个基本概念是决策树的根本,是决策树利用特征来分类时,确定特征选取顺序的依据。理解了它们,决策树你也就了解了大概。
信息是用来消除随机不确定性的东西。当然这句话虽然经典,但是还是很难去搞明白这种东西到底是个什么样,可能在不同的地方来说,指的东西又不一样。对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义如下:

- I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率。
- 熵是用来度量不确定性的,当熵越大,X=xi的不确定性越大,反之越小。对于机器学习中的分类问题而言,熵越大即这个类别的不确定性更大,反之越小。
- 信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。
信息
这个是熵和信息增益的基础概念,我觉得对于这个概念的理解更应该把他认为是一用名称,就比如‘鸡‘(加引号意思是说这个是名称)是用来修饰鸡(没加引号是说存在的动物即鸡),‘狗’是用来修饰狗的,但是假如在鸡还未被命名为’鸡’的时候,鸡被命名为‘狗’,狗未被命名为‘狗’的时候,狗被命名为’鸡’,那么现在我们看到狗就会称其为‘鸡’,见到鸡的话会称其为‘鸡’,同理,信息应该是对一个抽象事物的命名,无论用不用‘信息’来命名这种抽象事物,或者用其他名称来命名这种抽象事物,这种抽象事物是客观存在的。
熵
既然信息已经说完,熵说起来就不会那么的抽象,更多的可能是概率论的定义,熵是约翰.冯.诺依曼建议使用的命名(当然是英文),最初原因是因为大家都不知道它是什么意思,在信息论和概率论中熵是对随机变量不确定性的度量,与上边联系起来,熵便是信息的期望值,可以记作:

熵只依赖X的分布,和X的取值没有关系,熵是用来度量不确定性,当熵越大,概率说X=xi的不确定性越大,反之越小,在机器学期中分类中说,熵越大即这个类别的不确定性更大,反之越小,当随机变量的取值为两个时,熵随概率的变化曲线如下图:

当p=0或p=1时,H§=0,随机变量完全没有不确定性,当p=0.5时,H§=1,此时随机变量的不确定性最大
条件熵
条件熵是用来解释信息增益而引入的概念,概率定义:随机变量X在给定条件下随机变量Y的条件熵,对定义描述为:X给定条件下Y的条件干率分布的熵对X的数学期望,在机器学习中为选定某个特征后的熵,公式如下:

这里可能会有疑惑,这个公式是对条件概率熵求期望,但是上边说是选定某个特征的熵,没错,是选定某个特征的熵,因为一个特征可以将待分类的事物集合分为多类,即一个特征对应着多个类别,因此在此的多个分类即为X的取值。
信息增益
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差(这里指的是经验熵或经验条件熵,由于真正的熵并不知道,是根据样本计算出来的),公式如下:
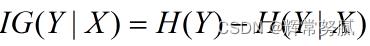
注意:这里不要理解偏差,因为上边说了熵是类别的,但是在这里又说是集合的熵,没区别,因为在计算熵的时候是根据各个类别对应的值求期望来等到熵
决策树
- 决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。常见的决策树算法有C4.5、ID3和CART。
随机森林的生成
前面提到,随机森林中有许多的分类树。我们要将一个输入样本进行分类,我们需要将输入样本输入到每棵树中进行分类。打个形象的比喻:森林中召开会议,讨论某个动物到底是老鼠还是松鼠,每棵树都要独立地发表自己对这个问题的看法,也就是每棵树都要投票。该动物到底是老鼠还是松鼠,要依据投票情况来确定,获得票数最多的类别就是森林的分类结果。森林中的每棵树都是独立的,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会超脱于芸芸“噪音”,做出一个好的预测。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想(关于bagging的一个有必要提及的问题:bagging的代价是不用单棵决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性。)。下图可以形象地描述这个情况:

有了树我们就可以分类了,但是森林中的每棵树是怎么生成的呢?
每棵树的按照如下规则生成:
- 如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本(理解这点很重要)。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging(装袋)的必要;
为什么要有放回地抽样?
我理解的是这样的:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的"(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
-
如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
-
每棵树都尽最大程度的生长,并且没有剪枝过程。
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
随机森林
- 随机森林即决策树的集成,它由多个决策树组合而成。如决策树一样,随机森林能处理类别特征、支持多分类而且不需要特征缩放。
- Spark MLlib 的随机森林算法同时支持二分类和多类别分类,以及连续型和类别型特征上的回归。
- 下面用 Spark 的随机森林算法来构建模型,在 StumbleUpon 数据集上进行训练,并得到在测试数据集上的评估指标。同样,数据会按照 9∶1 分为训练数据和测试数据。
def randomForestPipeline(vectorAssembler: VectorAssembler, dataFrame: DataFrame) =
val Array(training, test) = dataFrame.randomSplit(Array(0.9, 0.1), seed = 12345)
// 设置 Pipeline
val stages = new mutable.ArrayBuffer[PipelineStage]()
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
stages += labelIndexer
val RandomForest = new RandomForestClassifier()
.setFeaturesCol(vectorAssembler.getOutputCol)
.setLabelCol("indexedLabel")
.setNumTrees(20)
.setMaxDepth(5)
.setMaxBins(32)
.setMinInstancesPerNode(1)
.setMinInfoGain(0.0)
.setCacheNodeIds(false)
.setCheckpointInterval(10)
stages += vectorAssembler
stages += RandomForest
val pipeline = new Pipeline().setStages(stages.toArray)
// 拟合 Pipeline
val startTime = System.nanoTime()
val model = pipeline.fit(training)
val elapsedTime = (System.nanoTime() - startTime) / 1e9
println(s"Training time: $elapsedTime seconds")
val holdout = model.transform(test).select("prediction","label")
// 选择(prediction, true label)并计算测试误差
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val mAccuracy = evaluator.evaluate(holdout)
println("Test set accuracy = " + mAccuracy)
其输出如下:
Accuracy: 0.348
在二维散点图中可视化预测数据和实际数据,其结果如下所示

梯度提升树
- 梯度提升树是决策树的集成。它迭代地对决策树进行训练以最小化损失函数。它能处理类别型特征、支持多类别分类且不需要特征缩放。
- Spark MLlib 中梯度提升树是通过现有决策树的实现而实现的。它同时支持分类和回归。
- 下面用 Spark 的梯度提升树算法来构建模型,在 StumbleUpon 数据集上进行训练,并得到在测试数据集上的评估指标。同样,数据会按照 9∶1 分为训练数据和测试数据。代码如下:
val Array(training, test) = dataFrame.randomSplit(Array(0.9, 0.1), seed = 12345)
// 设置 Pipeline
val stages = new mutable.ArrayBuffer[PipelineStage]()
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
stages += labelIndexer
// 创建梯度提升树模型
val gbt = new GBTClassifier()
.setFeaturesCol(vectorAssembler.getOutputCol)
.setLabelCol("indexedLabel")
.setMaxIter(10)
stages += vectorAssembler
stages += gbt
val pipeline = new Pipeline().setStages(stages.toArray)
// 拟合 Pipeline
val startTime = System.nanoTime()
val model = pipeline.fit(training)
val elapsedTime = (System.nanoTime() - startTime) / 1e9
println(s"Training time: $elapsedTime seconds")
val holdout = model.transform(test).select("prediction","label")
// 需将类型转为 RegressionMetrics
val rm = new RegressionMetrics(holdout.rdd.map(x => (x(0).asInstanceOf[Double],
x(1).asInstanceOf[Double])))
logger.info("Test Metrics")
logger.info("Test Explained Variance:")
logger.info(rm.explainedVariance)
logger.info("Test R^2 Coef:")
logger.info(rm.r2)
logger.info("Test MSE:")
logger.info(rm.meanSquaredError)
logger.info("Test RMSE:")
logger.info(rm.rootMeanSquaredError)
val predictions =
model.transform(test).select("prediction").rdd.map(_.getDouble(0))
val labels = model.transform(test).select("label").rdd.map(_.getDouble(0))
val accuracy = new MulticlassMetrics(predictions.zip(labels)).precision
println(s" Accuracy : $accuracy")
输出如下:
Accuracy: 0.3647

多层感知分类器
- 神经网络是一个复杂的自适应系统,它会借助各权重的变更而改变信息流,进而改变自己的内部结构。针对多层神经网络的权重优化过程也称为反向传播(backpropagation)。反向传播超出了本书讨论范围,另也涉及激活函数和基本的微积分知识。
- 多层感知分类器(multilayer perceptron classifier)基于前向反馈(feed-forward)人工神经网络。它由多个神经层构成,每层都与下一层全连接。其输入层的各节点对应输入数据。其他节点都会对经该节点的输入、相应的权重和偏置(bias)进行线性组合,再应用一个激活函数(activationfunction)或连接函数后,映射为对应的输出。
- 下面用 Spark 的多层感知分类器算法来构建模型,在 libsvm 样例数据集上进行训练,并得到在测试数据集上的评估指标。同样,数据会按照 6∶4 分为训练数据和测试数据。代码如下:
object MultilayerPerceptronClassifierExample
def main(args: Array[String]): Unit =
val spark = SparkSession
.builder
.appName("MultilayerPerceptronClassifierExample")
.getOrCreate()
// 将 LIBSVM 格式的数据载入并转为一个 DataFrame
val data = spark.read.format("libsvm")
.load("/Users/manpreet.singh/Sandbox/codehub/github/machinelearning/spark-ml
/Chapter_06/2.0.0/scala-spark-app/src/main/scala/org/sparksamples/classification/
dataset/spark-data/sample_multiclass_classification_data.txt")
// 将数据分割为训练数据和测试数据
val splits = data.randomSplit(Array(0.6, 0.4), seed = 1234L)
val train = splits(0)
val test = splits(1)
// 指定神经网络的层:
// 输入层有 4 个特征,中间的两层分别有 5 个特征和 4 个特征
// 输出层的大小则为 3
val layers = Array[Int](4, 5, 4, 3)
// 创建并设置训练器
val trainer = new MultilayerPerceptronClassifier()
.setLayers(layers)
.setBlockSize(128)
.setSeed(1234L)
.setMaxIter(100)
// 训练模型
val model = trainer.fit(train)
// 计算在测试数据集上的准确度
val result = model.transform(test)
val predictionAndLabels = result.select("prediction", "label")
val evaluator = new MulticlassClassificationEvaluator()
.setMetricName("accuracy")
println("Test set accuracy = " + evaluator.evaluate(predictionAndLabels))
spark.stop()
以上是关于数据结构-集成算法-随机森林的主要内容,如果未能解决你的问题,请参考以下文章