Flink学习之流处理架构
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习之流处理架构相关的知识,希望对你有一定的参考价值。
🐋在上一章的学习中,我们学习了docker安装flink环境,并搭配了一系列流处理框架的组建,在这一章我们将介绍一下流式处理框架的原理,对往期其内容感兴趣的同学可以参考如下内容👇:
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🐳本篇博客主要讲解流处理框架与传统框架的比较,以及流处理框架的组成结构,让我们开始今日份的学习吧。
目录
1. 引言
数据架构设计领域正在发生一场变革,其影响不仅限于实时或近实时的项目。这场变革将基于流的数据处理流程视为整个架构设计的核心,而不是只作为某些专业化工作的基础。了解为何向流处理架构转变,可以帮助我们理解 Flink 和它在现代数据处理中所扮演的角色。
作为新型系统,Flink 扩展了“流处理”这个概念的范围。有了它,流处理不仅指实时、低延迟的数据分析,还指各类数据应用程序。其中,有些应用程序基于流处理器实现,有些基于批处理器实现,有些甚至基于事务型数据库实现。
2. 传统框架和流处理框架
对于后端数据而言,传统架构是采用一个中心化的数据库系统,用于存储事务类型性数据,比如,mysql存储的业务数据,反应当前状况下的业务状态。需要新鲜数据的应用程序都依靠数据库实现。分布式文件系统则用来存储不需要经常更新的数据,它们也往往是大规模批量计算所依赖的数据存储方式。但随着时间的推移,这种传统的方式遇见如下的问题:
- 在许多项目中,从数据到达到数据分析所需的工作流程太复杂、太缓慢。
- 传统的数据架构太单一:数据库是唯一正确的数据源,每一个应用程序都需要通过访问数据库来获得所需的数据。
- 采用这种架构的系统拥有非常复杂的异常问题处理方法。当出现异常问题时,很难保证系统还能很好地运行。
除了这些,传统架构的另一个问题是,需要通过在大型分布式系统中不断地更新来维持一致的全局状态。随着系统规模扩大,维持实际数据与状态数据间的一致性变得越来越困难;流处理架构则少了对这方面的要求,只需要维持本地的数据一致性即可。
作为一种新的选择,流处理架构解决了企业在大规模系统中遇到的诸多问题。以流为基础的架构设计让数据记录持续地从数据源流向应用程序,并在各个应用程序间持续流动。没有一个数据库来集中存储全局状态数据,取而代之的是共享且永不停止的流数据,它是唯一正确的数据源,记录了业务数据的历史。 在流处理架构中,每个应用程序都有自己的数据,这些数据采用本地数据库或分布式文件进行存储。
3. 消息传输层和流处理层
一个flink项目主要包含两个部分:消息传输层和流处理层
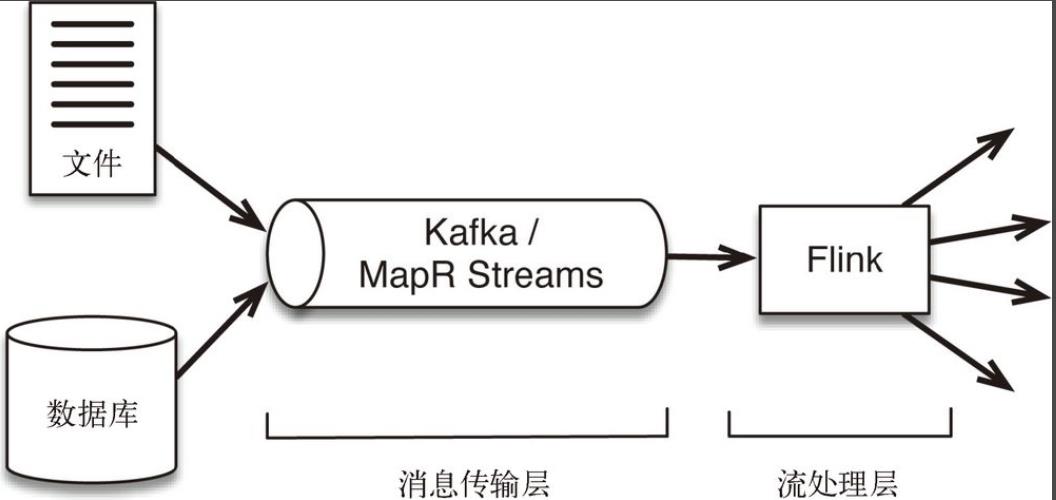
- 消息传输层从各种数据源(生产者)采集连续事件产生的数据,并传输给订阅了这些数据的应用和服务(消费者)。
- 流处理层有 3 个用途:①持续地将数据在应用程序和系统间移动;②聚合并处理事件;③在本地维持应用程序的状态。
在大家看来,都会把注意力放在流处理层上,这一层不止有flink还有像saprk streaming、strom等,但其实消息传输层也很关键,没有消息传递方式的改变,流处理框架也很难工作!
3.1 消息传输层
流处理框架下的消息传输层需要有哪些功能呢?
- 高性能和持久性
消息传输层的一个作用是作为流处理层上游的安全队列——它相当于缓冲区,可以将事件数据作为短期数据保留起来,以防数据处理过程发生中断。直到最近几年,高性能和持久性不可兼得的困境才被打破。人们习惯上认为流数据从消息传输层到流处理层之后就被丢弃:用了就没了。
为了设计新一代的流处理架构,高性能和持久性不可兼得是首先要改变的一个观念。兼具高性能和持久性对于消息传输系统来说至关重要;Kafka可以满足这个需求。
具有持久性的好处之一是消息可以重播。这个功能使得像 Flink 这样的处理器能对事件流中的某一部分进行重播和再计算。正是由于消息传输层和流处理层相互作用,才使得像 Flink 这样的系统有了准确处理和重新处理数据的能力。
- 生产者和消费者解耦
采用高效的消息传输技术,可以从多个源(生产者)收集数据,并使这些数据可供多个服务或应用程序(消费者)使用,如图 所示。Kafka 把从生产者获得的数据分配给既定的主题。数据源将数据推送给消息队列,消费者(或消费者群组)则拉取数据。事件数据只能基于给定的偏移量从消息队列中按顺序读出。生产者并不向所有消费者自动广播。这一点听起来微不足道,但是对整个架构的工作方式有着巨大的影响。
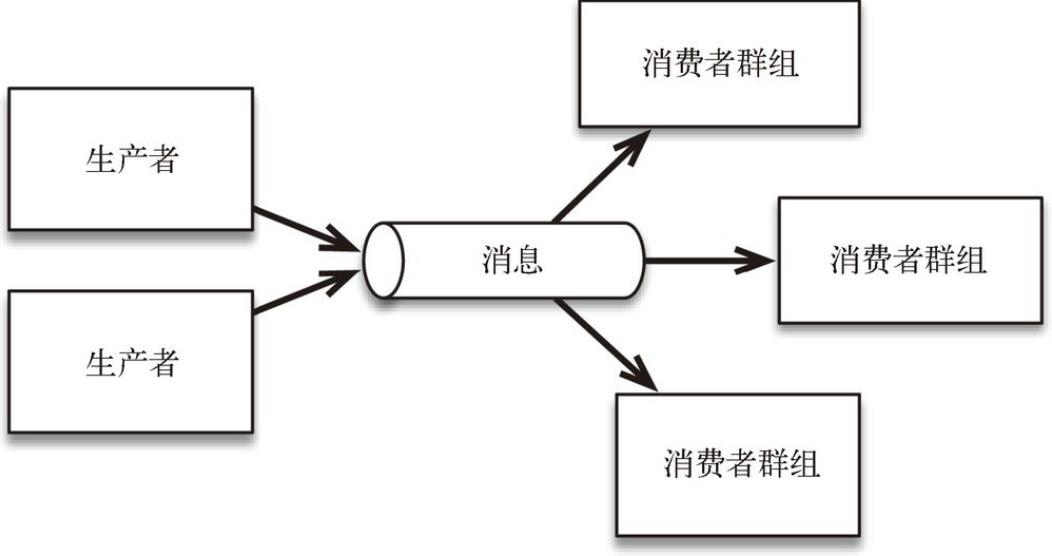
数据的生产者和消费者是解耦的。到达的消息既可以立刻被使用,也可以稍后被使用。消费者从队列中订阅消息,而不是由生产者向所有消费者广播。在消息到达的时候,消费者不必处于运行状态,而是可以根据自身需求在任何时间使用数据。这样一来,添加新的消费者和生产者也很容易。采用解耦的消息传输系统很有意义,因为它能支持微服务,也支持将处理步骤中的实现过程隐藏起来,从而允许自由地修改实现过程。
4. 流数据在微服务架构下的应用
微服务是软件设计中的概念,主要是指将一个大型的系统分解成一个一个具有单一目的子系统,比如:我们有一个单体架构的买卖东西的系统,初期用户不是很多,我们将买商品,进货,交易模块等放在一起,随着用户越来越多,这个系统的功能模块也在不断增加,库存管理、人员管理、售后服务等,这时我们可以考虑将这些服务一个一个拆解开,构建自己的系统,分别管理,这就是简单的微服务。
流处理架构的核心是使各种应用程序互连在一起的消息队列。流处理器flink从消息队列中订阅数据并加以处理。处理后的数据可以流向另一个消息队列。这样一来,其他应用程序(包括其他 Flink 应用程序)都可以共享流数据。在一些情况下,处理后的数据会被存放在本地数据库中。
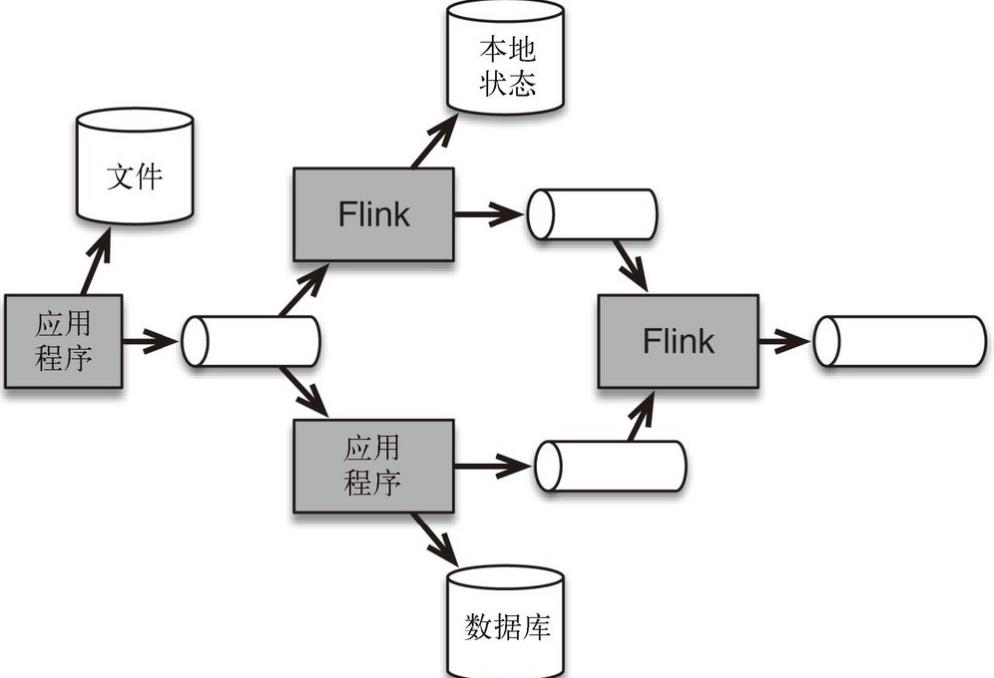
如图:在流处理架构中,消息队列(图中以水平圆柱体表示)连接应用程序,并作为新的共享数据源;它们取代了从前的大型集中式数据库。在本例中,Flink 被多个应用程序使用。本地化的数据能够根据微服务项目的需要被存储在文件或者数据库中。这种流处理架构的另一个好处是,流处理器Flink还可以保障数据一致性。
5. 案例
我们通过一个案例来了解一下:欺诈检测系统
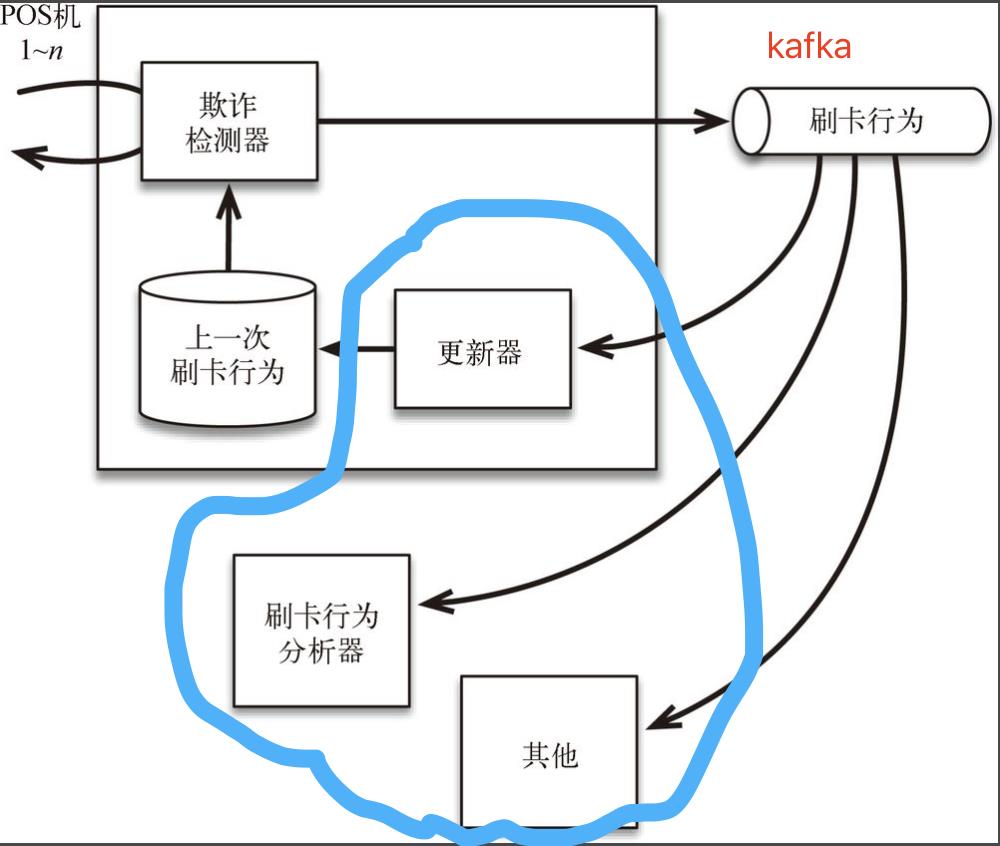
有很多POS机通过请求欺诈检测器看看这一次刷卡是否具有欺诈行为。这些来自POS机的请求需要立即被应答。
传统的欺诈检测器将刷卡的最后一次数据直接存储在数据库中,但这样的存储方式让其他需要数据的消费者不能轻易地使用刷卡数据,因为访问数据库可能会影响欺诈检测系统的正常工作;在没有经过认真仔细的审查之前,其他消费者绝不会被授权更改数据库。这将导致整个流程变慢,因为必须仔细执行各种检查,以避免核心的业务功能受到破坏或影响。
与传统方法相比,如图所示的流处理架构设计将欺诈检测器的输出发送给外部的消息队列(Kafka),再由如 Flink 这样的流处理器更新数据库,而不是直接将输出发送给数据库。这使得刷卡行为的数据可以通过消息队列被其他服务使用,例如刷卡行为分析器。上一次刷卡行为的数据被存储在本地数据库中,不会被其他服务访问。这样的设计避免了因为增加新的服务而带来的过载风险。
6. 参考资料
《Flink的数据科学的实用指南》
《Kafka权威指南》
《Apache Flink 必知必会》
《docker菜鸟教程》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink学习之流处理架构的主要内容,如果未能解决你的问题,请参考以下文章