Flink运行时之流处理程序生成流图
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink运行时之流处理程序生成流图相关的知识,希望对你有一定的参考价值。
流处理程序生成流图
DataStream API所编写的流处理应用程序在生成作业图(JobGraph)并提交给JobManager之前,会预先生成流图(StreamGraph)。
什么是流图
流图(StreamGraph)是表示流处理程序拓扑的数据结构,它封装了生成作业图(JobGraph)的必要信息。它的类继承关系如下图所示:
当你基于StreamGraph的继承链向上追溯,会发现它实现了FlinkPlan接口。
Flink效仿了传统的关系型数据库在执行SQL时生成执行计划并对其进行优化的思路。FlinkPlan是Flink生成执行计划的基接口,定义在Flink优化器模块中,流处理程序对应的计划是StreamingPlan,但是当前针对流处理程序没有进行优化,因此这个类可看作是一个预留设计。
一个简单的实现“word count”的流处理程序,其StreamGraph的形象化表示如下图:

Flink官方提供了一个来图形化执行计划,该计划可视化器基于Flink API所生成的计划的JSON格式表示绘制图形。但是需要注意的是,计划的JSON形式表示缺失了很多属性以及部分节点(比如虚拟节点等);
上面的图是由“节点”和“边”组成的。节点在Flink中对应的数据结构是StreamNode,而边对应的数据结构是StreamEdge,StreamNode和StreamEdge之间有着双向的依赖关系。StreamEdge包含了其连接的源节点sourceVertex和目的节点targetVertex:

而StreamNode中包含了与其连接的入边集合inEdges和出边集合outEdges:

StreamEdge和StreamNode都有唯一的编号进行标识,但是各自编号的生成规则并不相同。
StreamNode的编号id的生成是通过调用StreamTransformation的静态方法getNewNodeId获得的,其实现是一个静态计数器:
protected static Integer idCounter = 0;
public static int getNewNodeId() {
idCounter++;
return idCounter;
}StreamEdge的编号edgeId是字符串类型,其生成的规则为:
this.edgeId = sourceVertex + "_" + targetVertex + "_" + typeNumber + "_" + selectedNames
+ "_" + outputPartitioner;它是由多个段连接起来的,语义的文字表述如下:
源顶点_目的顶点_输入类型数量_输出选择器的名称_输出分区器edgeId除了用来实现StreamEdge的hashCode及equals方法之外并没有其他实际意义。
StreamNode是表示流处理中算子的数据结构,source和sink在StreamGraph中也是以StreamNode表示,它们也是一种算子,只是因为它们是流的输入和输出因而有特定的称呼。
StreamNode除了存储了输入端和输出端的StreamEdge集合,还封装了算子的其他关键属性,比如其并行度、分区的键信息、输入与输出类型的序列化器等。
从直观上来看你已经知道了StreamNode和StreamEdge是StreamGraph的重要组成部分,但是为了生成JobGraph,StreamGraph很显然必须得包含更多的内容。总结一下,StreamGraph中包含的属性可分为三大类:
- 流处理程序的执行配置;
- 流处理程序拓扑中包含的节点和边的信息;
- 迭代相关的信息;
当然围绕这些属性的方法非常多,比如添加边和节点,创建迭代的source/sink等。
其中的一个关键方法getJobGraph将用于生成JobGraph:
public JobGraph getJobGraph() {
if (isIterative() && checkpointConfig.isCheckpointingEnabled()
&& !checkpointConfig.isForceCheckpointing()) {
throw new UnsupportedOperationException(
"Checkpointing is currently not supported by default for iterative jobs, as we cannot guarantee exactly once semantics. "
+ "State checkpoints happen normally, but records in-transit during the snapshot will be lost upon failure. "
+ "
The user can force enable state checkpoints with the reduced guarantees by calling: env.enableCheckpointing(interval,true)");
}
StreamingJobGraphGenerator jobgraphGenerator = new StreamingJobGraphGenerator(this);
return jobgraphGenerator.createJobGraph();
}从上面的代码段也可见,当流处理程序中包含迭代逻辑时,检查点功能暂时不被支持,在异常信息中Flink阐述了缘由:在迭代作业中无法保证“恰好一次”的语义。
流处理程序依赖StreamingJobGraphGenerator来生成JobGraph,至于如何生成,后续会进行剖析。
生成流图的源码分析
了解了什么是流图(StreamGraph)之后,我们来分析它是如何生成的。流图的生成是通过StreamExecutionEnvironment的getStreamGraph实例方法触发的:
public StreamGraph getStreamGraph() {
if (transformations.size() <= 0) {
throw new IllegalStateException("No operators defined in streaming topology. Cannot execute.");
}
return StreamGraphGenerator.generate(this, transformations);
}从代码段中可见,StreamGraph的生成依赖于一个名为transformations的集合对象,它是环境对象所收集到的所有的转换对象的集合,该集合中存储着一个流处理程序中所有的转换操作对应的StreamTransformation对象。
每当在DataStream对象上调用transform方法或者调用已经被实现了的一些内置的转换函数(如map、filter等,这些转换函数在内部也调用了transform方法),这些调用都会使得其对应的转换对象被加入到transformations集合中去。StreamTransformation表示创建DataStream对象的转换,流处理程序中存在多种DataStream,每种底层都对应着一个StreamTransformation。DataStream持有执行环境对象的引用,当调用transform方法时,它会调用执行环境对象的addOperator方法,将特定的StreamTransformation对象加入到transformations集合中去,这就是transformations集合中元素的来源。
DataStream API的设计存在着多重对象的封装,我们以flatMap转换操作为例图示各种对象之间的构建关系:
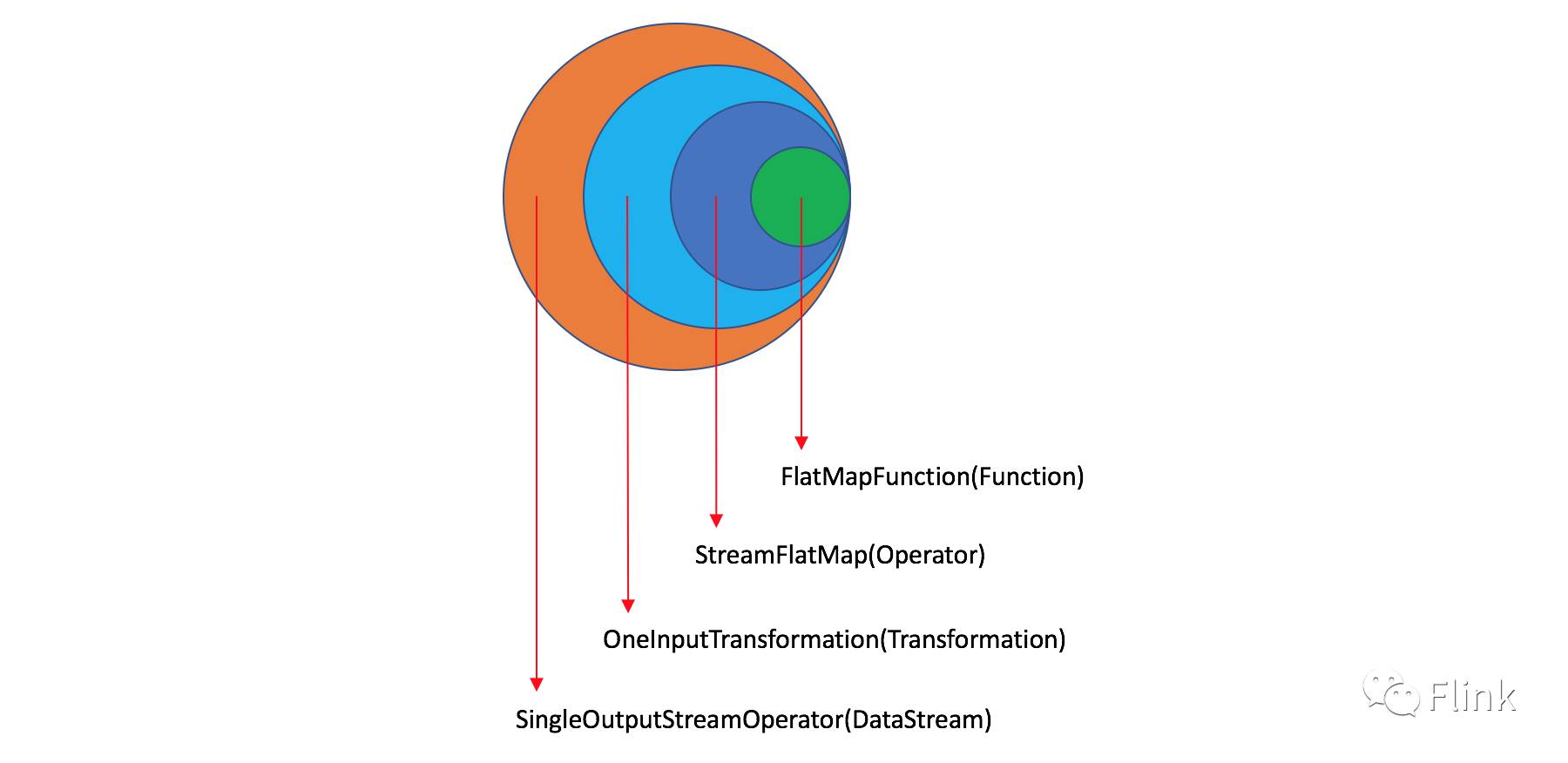
在Flink的源码中,这些对象的命名也并不是那么准确,比如上图中的SingleOutputStreamOperator其实是一种DataStream,但却以Operator结尾,让人匪夷所思。因此较为准确的鉴定它们类型的方式是通过查看它们的继承链来进行识别。
StreamGraph的生成依赖于生成器StreamGraphGenerator,每调用一次静态方法generate才会在内部创建一个StreamGraphGenerator的实例,一个实例对应着一个StreamGraph对象。StreamGraphGenerator调用内部的实例方法generateInternal来遍历transformations集合的每个对象:
private StreamGraph generateInternal(List<StreamTransformation<?>> transformations) {
for (StreamTransformation<?> transformation: transformations) {
transform(transformation);
}
return streamGraph;
}在transform方法中,它枚举了Flink中每一种转换类型,并对当前传入的转换类型进行判断,然后将其分发给特定的转换方法进行转换,最终返回当前StreamGraph对象中跟该转换有关的节点编号集合。
这里我们以常用的单输入转换方法transformOnInputTransform为例来进行分析:
private <IN, OUT> Collection<Integer> transformOnInputTransform(
OneInputTransformation<IN, OUT> transform) {
//递归地对该转换的输入端进行转换
Collection<Integer> inputIds = transform(transform.getInput());
// 递归调用可能会产生重复,这里需要以转换过的对象进行检查
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
//结合输入端对应的节点编号来判断并得出槽共享组的名称
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
//将当前算子(节点)加入到流图中
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
//如果有键选择器,则进行设置
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer =
transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(),
transform.getStateKeySelector(), keySerializer);
}
streamGraph.setParallelism(transform.getId(), transform.getParallelism());
//构建从当前转换对应的节点到输入转换对应的节点之间的边
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
//返回当前转换对应的节点编号
return Collections.singleton(transform.getId());
}每遍历完一个转换对象,就离构建完整的流图更近一步。不同的转换操作类型,它们为流图提供的“部件”并不完全相同,有的转换只构建节点(如SourceTransformation),有的转换除了构建节点还构建边(如SinkTransformation),有的只构建虚拟节点(如PartitionTransformation、SelectTransformation等)。
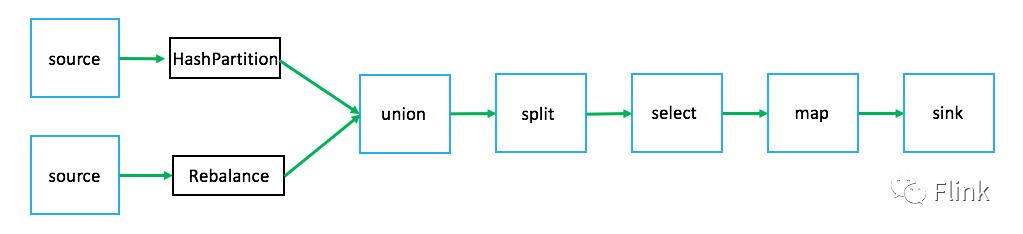
关于虚拟节点,这里需要说明的是并非所有转换操作都具有实际的物理意义(即物理上对应具体的算子)。有些转换操作只是逻辑概念(例如select,split,partition,union),它们不会构建真实的StreamNode对象。比如某个流处理应用对应的转换树如下图:
但在运行时,其生成的StreamGraph却是下面这种形式:
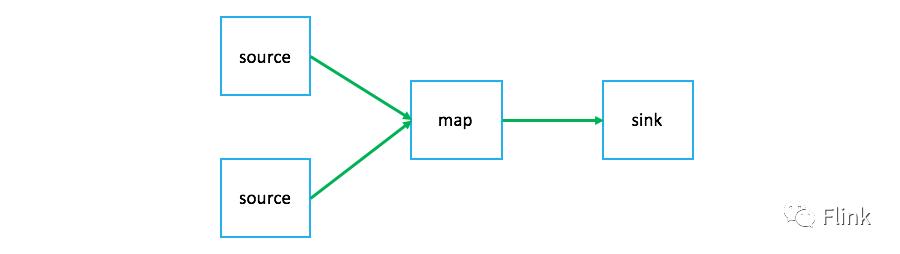
从图中可以看到,转换树中对应的一些逻辑操作在StreamGraph中并不存在,Flink将这些逻辑转换操作转换成了虚拟节点,它们的信息会被绑定到从source到map转换的边上。
Flink当前对于流处理的程序是不作优化的,所以StreamGraph就是它的执行计划。你可以通过Flink提供的执行计划的可视化器将StreamGraph所表述的信息以图形化的方式展示出来,就像上文我们展示的那幅图一样。那么我们如何查看我们自己所编写的程序的执行计划呢?其实很简单,我们以Flink源码中flink-examples-streaming模块中的SocketTextStreamWordCount为例,来看一下如何生成执行计划。
我们将SocketTextStreamWordCount最后一行代码注释掉:
env.execute("WordCount from SocketTextStream Example");然后将其替换成下面这句:
System.out.println(env.getExecutionPlan());这行语句的作用是打印当前这个程序的执行计划,它将在控制台产生该执行计划的JSON格式表示:
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data Source","contents":"Source: Socket Stream",
"parallelism":1},{"id":2,"type":"Flat Map","pact":"Operator","contents":"Flat Map","parallelism":2,
"predecessors":[{"id":1,"ship_strategy":"REBALANCE","side":"second"}]},{"id":4,"type":"Keyed Aggregation",
"pact":"Operator","contents":"Keyed Aggregation","parallelism":2,"predecessors":[{"id":2,
"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Unnamed","pact":"Data Sink",
"contents":"Sink: Unnamed","parallelism":2,"predecessors":[{"id":4,"ship_strategy":"FORWARD",
"side":"second"}]}]}把上面这段JSON字符串复制到Flink的执行计划可视化器的输入框中,然后点击下方的“Draw”按钮,即可生成。
以上是关于Flink运行时之流处理程序生成流图的主要内容,如果未能解决你的问题,请参考以下文章