Flink学习之流处理原理
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习之流处理原理相关的知识,希望对你有一定的参考价值。
💗💕💖今天是情人节,祝大家情人节快乐!今天我们来继续flink教程,我们今日要学习的是流处理的原理。注意一下,我这里的流处理指的不是flink的流处理,而是流处理的基础模型——Dataflow模型。对以前内容感兴趣的同学可以参考如下内容👇:
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
💙💜❤️本篇文章介绍的Dataflow模型可以誉为“现代流数据计算的基石”,flink借鉴的其中大部分的内容,让我们开始今日份的学习吧!
目录
1. 流数据特征
流数据一般具有如下特征:
- 数据连续,实时产生,无结束边界。
- 数据本身可以携带时间标签。
- 数据到达顺序可能和产生时间不一致。
- 数据量大,数据规模可以达亿级别。
- 数据二次处理代价高昂,不存储全量数据。
一般来说,流处理应用使用延迟和吞吐量这两个指标来表示性能水平。其中延迟表示处理事件所需的时间。而吞吐量是衡量流处理应用计算能力的指标,它代表每个单位时间里,流处理应用最大可以处理事件的数量。
在流处理应用中,通过分布式并行计算,来完成低延迟和高吞吐二者之间的平衡。对于一个流计算系统来说,一般具备如下的特征:
- 延迟低,几毫秒到几秒之间。
- 高吞吐,可以处理大量的事件数据。
- 分布式,可以动态扩容。
- 可靠性,计算过程状态可保存,可从故障中恢复。
2. Dataflow模型
业界中,把Google公司的Dataflow模型比作现代流数据计算的基石。Google公司在2015年发表了一篇关于Dataflow模型的论文“The dataflow model: a practical approach to balancing correctness,latency,and cost in massive-scale,unbounded, out-of-order data processing”,它提供了一种统一流处理和批处理的系统框架。
Dataflow模型对于无序的流数据,提供了一套基于事件时间(Event Time)、水位线(Watermark)和延迟处理的机制,从而实现窗口(Window)聚合计算的能力,以实现流数据计算的正确性、高吞吐和延迟这三者之间的平衡。
由于很多系统都是分布式部署的,各个系统之间的数据通过网络进行传输,那么数据在采集和传输过程中,不可避免会产生数据乱序和延迟到达的情况。换句话说,流处理系统在对数据流进行处理时,其接收到的数据次序很有可能与数据产生的原始次序不同,为了正确和高效地对乱序流数据进行处理,引入2个非常重要的概念:
- 事件时间(Event Time)
数据产生时从原设备获取的时间戳,即事件真实发生的时间,用事件时间作为时间属性的好处是同样的数据输入,多次运行的结果是一致的。 - 处理时间(Processing Time)
流数据中某个事件被流处理程序处理时所记录的时间戳。由于流数据场景下,产生数据的设备和处理数据的设备可能是分布式的,因此不同设备的时间应该进行同步。通常情况下,处理时间比事件时间晚一些,用处理时间作为时间属性会导致同样的数据输入,多次运行的结果是不一致的。
2.1 Dataflow解决难题
Dataflow模型解决了流处理的4个问题:
- 需要产出什么结果?
这个要根据实际业务需求,用户自行进行设计和实现。由于这部分流处理框架不能提前预置,但需要提供良好的编程接口,以实现灵活的数据处理自定义功能。
- 计算什么时间的数据?
窗口模型(Window Model)实现基于时间属性对数据进行窗口操作的目的。它可以将无界的数据按照时间属性划分为一个一个有限的数据集合,从而实现在窗口中对有限数据进行分组和聚合等操作。
- 什么时候触发计算?
触发模型(Trigger Model)能够将数据结果与事件的时间属性或事件数量进行关联,解决了作业应该在什么时候触发的问题。另外,可以结合水位线来解决事件数据乱序到达带来的计算问题。
- 如何确定规定时间内事件以到达?
采用了水位线(Watermark)机制。水位线从本质上来说,也是一个时间戳。按照约定,水位线T就表示窗口已经接收到所有t <=T的数据。其他t > T的数据都将被视为迟到,而对于迟到数据的处理,则需要采用增量更新模型。水位线T的确定是一个难题,另外单靠水位线机制也不能确保100%可靠。
3. 数据流图
在流处理应用系统中,一个流计算作业的内部计算过程可以用数据流图进行描述。它给出了流数据如何在不同算子之间进行流转的示意,通常表示为一个具有流转方向的有向无环图(DAG)。
数据流图中,有数据源、数据处理算子和数据输出。其中图中的节点称为算子,连接不同节点的线代表数据之间的依赖性,也给出了数据流转的方向。算子是流处理应用当中最基本的功能单元,代表相关的业务处理逻辑。
数据流图有逻辑数据流图和物理数据流图之分。以大数据领域常见的单词计数(Word Count)为例,如图:


- 逻辑数据流图:逻辑数据流图一般以一种更加简练和宏观的角度来对流数据处理过程进行描述。它往往并不完全代表实际的物理执行情况。对于一个分布式流处理引擎来说,它会将逻辑数据流图转换为物理数据流图,来调度内部任务的执行。
- 物理数据流图:代表实际的物理执行情况。在物理数据流图中,节点是任务。其中的拆分、映射和分组求和算子有两个并行算子实例(任务),每个算子实例对输入数据的部分数据进行处理。
4. 流处理操作
流处理的本质就是一种高效的增量数据处理机制,流处理系统可以在每接收到一个事件数据后,就进行逻辑处理。
一个流处理应用也会包含如下3个部分:
- 流数据源
流数据源是一个与外部系统进行交互的接口,它可以从外部系统获取到原始的数据。流数据源种类繁多,比如HDFS文件系统、数据库或消息队列。 - 流数据转换
从数据源获取流数据后,内部就需要根据业务逻辑对数据流进行转换操作。一般来说,这些转换会将一个输入数据流转换成一个新的数据流。(转换和聚合操作) - 流数据输出
流计算引擎从数据源获取数据,经过转换操作对数据进行处理后,需要将计算结果进行输出,以供外部系统进行使用。比如将可燃气体浓度传感器中的数据作为数据源,经过过滤操作算子处理,过滤出浓度大于0.97这个阈值的事件数据,并将过滤后的数据流写入到外部系统中,如消息队列,或者写入数据库中。
5. 窗口操作
在流数据上的操作,除了支持常规的转换操作和滚动聚合操作外(一个事件数据到达就会触发计算,延迟低),还支持基于窗口的操作,它会接收并缓冲一定量的数据后才会触发相应的计算逻辑。
基于窗口上的求和操作,程序只对窗口中的有界数据集进行求和操作,而不是全部的历史数据。窗口操作一般以时间属性来划分窗口。
窗口有不同的类型,一般分为3种:
- 滚动窗口
滚动窗口是将无界的流数据,按照固定大小进行拆分成不同的窗口,不同窗口中的事件数据没有交叉。当某个事件数据到达时,如果满足窗口触发规则,则会触发计算机制,将窗口内全部数据进行逻辑处理,并给出结果。
滚动窗口分为基于数量的滚动窗口(满足一定数量触发计算)和基于时间的滚动窗口(每隔一段时间出发计算)
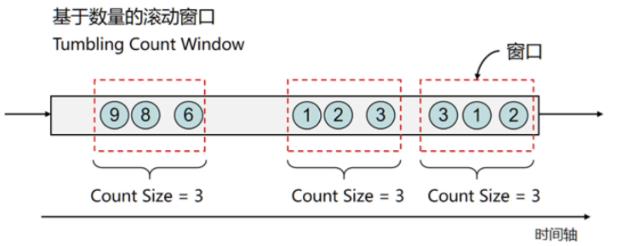

- 滑动窗口
滑动窗口有两个参数,一个是窗口大小,一个是滑动大小。当滑动大小等于窗口大小时,就是滑动窗口。滑动窗口将事件数据分配到固定大小的窗口中,但不同窗口中的元素可能有交叉,即一个元素可能同时属于多个窗口。
滑动窗口可以分为基于数量的滑动窗口和基于时间的滑动窗口

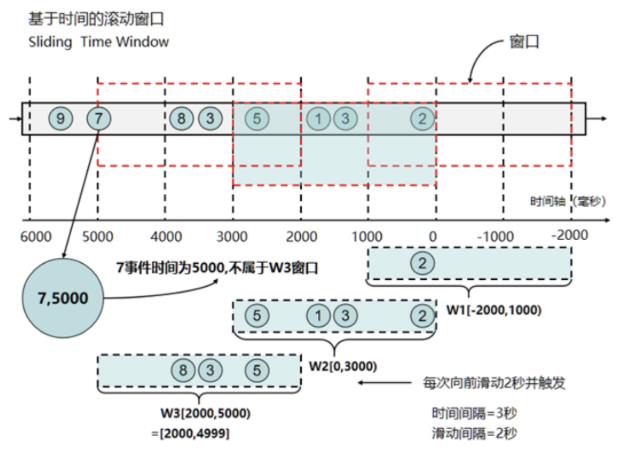
- 会话窗口
除了滚动窗口和滑动窗口外,还有一种窗口类型,即会话窗口。在某些场景下,会话窗口非常好用,而且这些场景用滑动窗口和滚动窗口实现起来非常难。
会话窗口用一个时间间隙阈值来区分不同的窗口。比如,一个Web应用,在服务器端会维护一个Session ID,当用户在网页上不进行相关操作时,超过服务器设定的会话超时时间,则此Session ID失效。

6. 总结
本篇博客主要是从Dataflow流处理模型中介绍了一些流处理中的关键特点,以及解决流处理的问题,为后续flink处理流数据做铺垫。这里我们需要记住一些名词:事件时间、处理时间、水位线、数据流图等,和flink都极大相关。
7. 参考资料
《Flink入门与实战》
《Kafka权威指南》
《Apache Flink 必知必会》
《docker菜鸟教程》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink学习之流处理原理的主要内容,如果未能解决你的问题,请参考以下文章