麻省理工研究:深度图像分类器,居然还会过度解读
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了麻省理工研究:深度图像分类器,居然还会过度解读相关的知识,希望对你有一定的参考价值。

作者 | 青苹果
来源 | 数据实战派
某些情况下,深度学习方法能识别出一些在人类看来毫无意义的图像,而这些图像恰恰也是医疗和自动驾驶决策的潜在隐患所在。换句话说,深度图像分类器可以使用图像的边界,而非对象本身,以超过 90% 的置信度确定图像类别。
不过,麻省理工学院的科学家最近发现了一种新颖的、更微妙的图像识别失败类:“过度解读”,即算法基于一些人类无法理解的细节,如随机模式或图像边界,而做出自信的预测。对于高风险的环境来说,这可能尤其令人担忧,比如自动驾驶汽车的瞬间决策,以及需要立即关注的疾病医疗诊断等,这都与生命安全息息相关。
研究团队发现,在 CIFAR-10 和 ImageNet 等流行数据集上训练的神经网络,就存在着过度解读的问题。
例如,在 CIFAR-10 上训练的模型,即使输入图像存在 95% 缺失的情况下,也能做出自信的预测。也就是说,在未包含语义显著特征的图像区域中,分类器发现强有力的类证据时,就会发生模型过度解释。
过度解释与过拟合有关,但过拟合可以通过降低测试精度来诊断。过度解释可能源于底层数据集分布中的真实统计信号,而这些统计信号恰好来自数据源的特定属性(如皮肤科医生的临床评分表)。
因此,过度解释可能更难诊断,因为它承认决策是由统计上有效的标准做出的,而使用这些标准的模型可以在基准测试中表现的较为出色。
过度解释发生在原始图像的未修改子集上。与使用额外信息修改图像的对抗性示例相反,过度解释基于训练数据中已经存在的真实模式,这些模式也可以泛化到测试分布。要想揭示过度解释,则需要一种系统的方法来识别哪些特征被模型用来做出决策。
这篇研究论文被 NIPS 收录,标题为“Overinterpretation reveals image classificationmodel pathologies”,文中引入了一种新的方法——批处理梯度 SIS(Sufficient Input Subsets),用于发现复杂数据集的充足的输入子集,并利用该方法在ImageNet中显示边界像素的充分性,用于训练和测试。
该文章的第一作者、MIT 计算机科学与人工智能实验室博士生Brandon Carter说,“过度解读实质上是一种数据集问题,由数据集中的无意义信号而引起的。这些高置信度图像不仅无法识别,而且在边界等不重要的区域,它们只包含不到 10% 的原始图像。我们发现这些图像对人类来说毫无意义,但模型仍然可以高度自信地对其进行分类。”

比如,在用于癌症检测的医学图像分类器的示例中,可以通过找到描述标尺的像素来识别病理行为,这足以让模型自信地输出相同的分类。
早先研究者便提出了 SIS 的概念,用于帮助人类解释黑盒模型的决策。SIS 子集是特征(如像素)的最小子集,它足以在所有其他特征被掩盖的情况下,产生高于某个阈值的类概率。
基准数据集的隐藏统计信号可能导致模型过度解释或不适用于来自不同分布的新数据。
CIFAR-10 和 ImageNet 已成为最流行的两种图像分类基准。大多数图像分类器由 CV 社区根据其在这些基准之一中的准确性进行评估。
除此之外,团队还使用 CIFAR-10-C 数据集来评估 CIFAR-10 模型可以泛化到分布外(OOD,Out-Of-Distribution)数据的程度。在这里,团队成员分析了在这些基准上流行的 CNN 架构的过度解释,以表征病理。通过一系列的实验证明,在 CIFAR-10 和 ImageNet 上训练的分类器,可以基于 SIS 子集进行决策,哪怕只包含少量像素和缺乏人类可理解的语义内容。
图1 显示了来自 CIFAR-10 测试图像的示例 SIS 子集(阈值为 0.99)。对于这些 SIS 子集图像,每个模型对预测类的置信度均≥99%,能够自信且正确地进行分类。

团队观察到,这些 SIS 子集具有高度稀疏的特征,在此阈值下,SIS 的平均尺寸小于每幅图像的 5%(如图2 所示),这表明这些 CNNs 可以自信地对那些对人类来说似乎毫无意义的图像进行分类,随之也就掀起了对鲁棒性和泛化性的关注热潮。此外,团队发现, SIS 的尺寸大小也是影响类预测准确性的重点因素。

到目前为止,深度图像分类器应用领域愈加广泛,除了医疗诊断和增强自动驾驶汽车技术外,在安全、游戏,甚至在一款可以告诉你某物是不是热狗的小程序上也有所应用。
考虑到机器学习模型能够捕捉到这些无意义的微妙信号,图像分类的难度之大也就不言而喻。比如,在 ImageNet 数据集上训练图像分类器时,它们便可以基于这些信号做出看似可靠的预测。
尽管这些无意义的信号会削弱模型在真实世界中的鲁棒性,但实际上,这些信号在数据集中是有效的,这也就意味着,基于该准确性的典型评估方法无法诊断过度解释。
为了找到模型对特定输入的预测的基本原理,本研究中的方法从整幅图像入手,反复研究,每一步究竟可以从图像上删除的内容。
团队采用局部后向选择(local backward selection),在每幅图像中保留 5% 的像素且用零掩码其余的 95%。从本质上说,这个过程会一直掩盖图像,直到残留的最小的部分仍然可以做出有把握的决定,让这些像素子集的分类精度堪比完整图像的分类精度。
如表1 所示,相比于从每幅图像中均匀随机选择的像素子集,通过后向选择所筛选的同样大小的子集具有更强的预测性。

图3a 显示了所有 CIFAR-10 的测试图像中,这些 5% 像素子集的像素位置和置信度。
研究发现,ResNet20 的底部边界上像素的集中是SIS向后选择过程中“决胜”的结果。此外,团队成员还在 CIFAR-10 上运行了分批梯度 SIS,并为 CIFAR-10 找到了充足的边缘输入子集。
而图3b 显示了来自 1000 张 ImageNet 验证图像的随机样本的 SIS 像素位置。关注度沿图像边界分布,表明该模型严重依赖于图像背景,存在严重的过度解释问题。

图4 显示了,在经过预训练的 Inception v3,通过批处理梯度 SIS 自信分类的图像上发现的例子 SIS 子集(阈值 0.9)。这些 SIS 子集看起来毫无意义,但网络将其分类的置信度≥90%。

CNNs 对图像分类的过度自信可能会引发怀疑,在语义无意义的 SIS 子集上观察到的过度自信是否是校准的伪像,而非数据集中的真实统计信号呢?
实验结果如表1 所示,随机 5% 的图像子集仍然能够捕捉到足够的信号,预测效果大约是盲猜的 5 倍,然而这并不足以捕捉到充足的信息,让模型做出准确的预测。
更多地,团队发现,无论是 CIFAR-10 测试图像(图5)还是 CIFAR-10- C OOD 图像,在所有 SIS 置信阈值上,正确分类图像的 SIS 子集都显著大于错误分类图像的 SIS 子集。

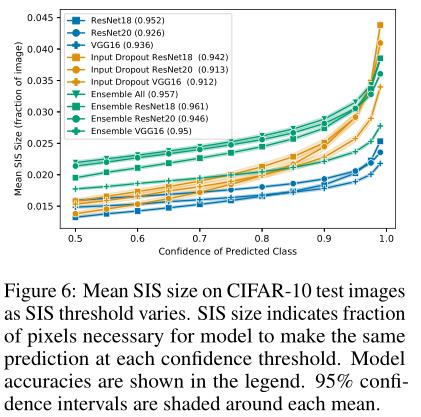
有研究表示,模型集成可以提高分类性能。由于团队发现,像素子集的大小与人类像素子集分类的准确性密切相关,于是,用来衡量集成程度可以缓解过度解释的指标是 SIS 子集大小的增加。
结果显示,集成测试一致地增加了预期的测试准确性,与此同时也增加了 SIS 的大小,因此削弱了过度解释的损害。
当然,文中的方法也可以作为一种验证标准。
例如,如果你有一辆自动驾驶汽车,它使用训练有素的机器学习方法来识别停车标志,你可以通过识别构成停车标志的最小输入子集来测试这种方法。
虽然看起来模型可能是罪魁祸首,但数据集的嫌疑更大。这可能意味着在更受控制的环境中创建数据集。
“存在一个问题,我们如何修改数据集,使模型能够更接近地模仿人类对图像分类的想法,从而有望在自动驾驶和医疗诊断等现实场景中更好地推广和应用,这样一来,模型就不会再产生荒谬的行为,” Carter 表示。

往
期
回
顾
技术
资讯
技术
资讯

分享

点收藏

点点赞

点在看
以上是关于麻省理工研究:深度图像分类器,居然还会过度解读的主要内容,如果未能解决你的问题,请参考以下文章