深度学习图像分类网络:GoogLeNet(V1-V4)模型搭建解读(附代码实现)
Posted 码农男孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习图像分类网络:GoogLeNet(V1-V4)模型搭建解读(附代码实现)相关的知识,希望对你有一定的参考价值。


GoogLeNetV1-V4的模型结构都不是很简洁,参数设置上也没有什么规律可循,都是他们从大量实验中证明得到的。整体架构但是不难理解,都是重复的模块进行堆叠,所以理解了每一块的作用,整体来看就很简单。希望大家保持头脑清醒,否则觉得这一块的东西很混乱。V1、V2目前很少使用,V3、V4是使用最多的,本文主要讲解GoogLeNet - V4。正式介绍V4之前,一起回顾GoogLeNet V1-V3。
一、简介
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,GoogLeNet名字致敬了LeNet,因此大写了L。深度学习中有很多有趣的名字,他们在命名时很希望玩梗。在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
二、Inception块介绍
inception模块的基本结果如图1,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
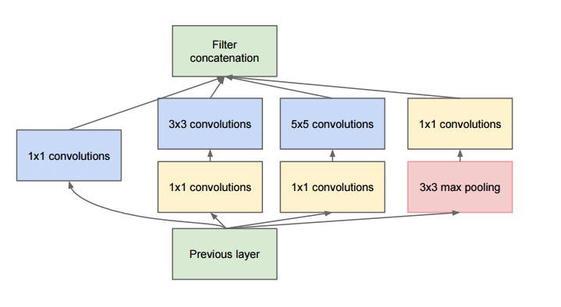
1x1卷积
作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。
这个观点来自于Network in Network,上图中的三个1x1卷积都起到了该作用。
作用2:使用1x1卷积进行降维,降低了计算复杂度。
当某个卷积层输入的特征数较多,对这个输入进行卷积运算将产生巨大的计算量;如果对输入先进行降维,减少特征数后再做卷积计算量就会显著减少。
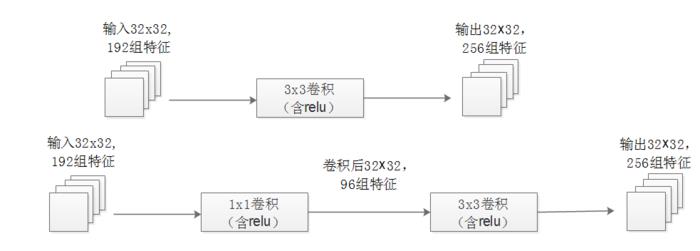
上图展示的是优化前后两种方案的乘法次数比较,同样是输入一组有192个特征、32x32大小,输出256组特征的数据,第一行中第一张图直接用3x3卷积实现,需要192x256x3x3x32x32=452984832次乘法;第二行中第二张图先用1x1的卷积降到96个特征,再用3x3卷积恢复出256组特征,需要192x96x1x1x32x32+96x256x3x3x32x32=245366784次乘法,使用1x1卷积降维的方法节省了一半的计算量。
有人会问,用1x1卷积降到96个特征后特征数不就减少了么,会影响最后训练的效果么?
答案是否定的,只要最后输出的特征数不变(256组),中间的降维类似于压缩的效果,并不影响最终训练的结果。
多个尺寸上进行卷积再聚合
从inception模块结构示意图中,我们可以看到对输入做了4个分支,分别用不同尺寸的filter进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构有什么好处呢?Szegedy从多个角度进行了解释:
解释1:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
解释2:利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
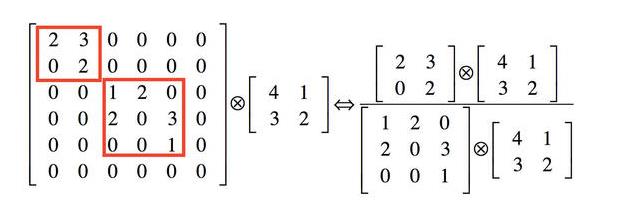
举个例子下图中左侧是个稀疏矩阵(很多元素都为0,不均匀分布在矩阵中),和一个2x2的矩阵进行卷积,需要对稀疏矩阵中的每一个元素进行计算;如果像下图中右图那样把稀疏矩阵分解成2个子密集矩阵,再和2x2矩阵进行卷积,稀疏矩阵中0较多的区域就可以不用计算,计算量就大大降低。这个原理应用到inception上就是要在特征维度上进行分解!
传统的卷积层的输入数据只和一种尺度(比如3x3)的卷积核进行卷积,输出固定维度(比如256个特征)的数据,所有256个输出特征基本上是均匀分布在3x3尺度范围上,这可以理解成输出了一个稀疏分布的特征集;而inception模块在多个尺度上提取特征(比如1x1,3x3,5x5),输出的256个特征就不再是均匀分布,而是相关性强的特征聚集在一起(比如1x1的的96个特征聚集在一起,3x3的96个特征聚集在一起,5x5的64个特征聚集在一起),这可以理解成多个密集分布的子特征集。这样的特征集中因为相关性较强的特征聚集在了一起,不相关的非关键特征就被弱化,同样是输出256个特征,inception方法输出的特征“冗余”的信息较少。用这样的“纯”的特征集层层传递最后作为反向计算的输入,自然收敛的速度更快。
解释3:Hebbin赫布原理。
Hebbin原理是神经科学上的一个理论,解释了在学习的过程中脑中的神经元所发生的变化,用一句话概括就是fire togethter, wire together。赫布认为“两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋”。比如狗看到肉会流口水,反复刺激后,脑中识别肉的神经元会和掌管唾液分泌的神经元会相互促进,“缠绕”在一起,以后再看到肉就会更快流出口水。用在inception结构中就是要把相关性强的特征汇聚到一起。这有点类似上面的解释2,把1x1,3x3,5x5的特征分开。因为训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用。
在inception模块中有一个分支使用了max pooling,作者认为pooling也能起到提取特征的作用,所以也加入模块中。注意这个pooling的stride=1,pooling后没有减少数据的尺寸。
三、V1-V3回顾
1. GoogLeNet-V1 (Inception-V1):
借鉴NIN广泛应用1*1卷积,借鉴多尺度Gabor滤波器提出多尺度卷积的Inception结 构,开启多尺度卷积,1*1卷积时代
上面已经详细介绍,不再赘述。
2. GoogLeNet-V2
- 1. 用两个3*3卷积代替5*5卷积,可以降低参数量。
- 2. 提出BN算法,针对ICS(Internal Covariate Shift,内部协变量偏移)问题,提出Batch Normalization,加快整个深度学习的发展,让标准化层成为深度神经网络的标配
3. GoogLeNet-V3(Inception-V2 and Inception-V3)
大量实验,总结模型设计准则,提出卷积分解、高效特征图分辨率、标签平滑技巧,开始了针对性模块的设计思路,也导致Inception系列越走越窄。
在Inception V2的基础上,将一个二维卷积拆分成两个较小卷积,例如将7*7卷积拆成1*7卷积和7*1卷积,这样做的好处是降低参数量。Inception V2结构图如下所示
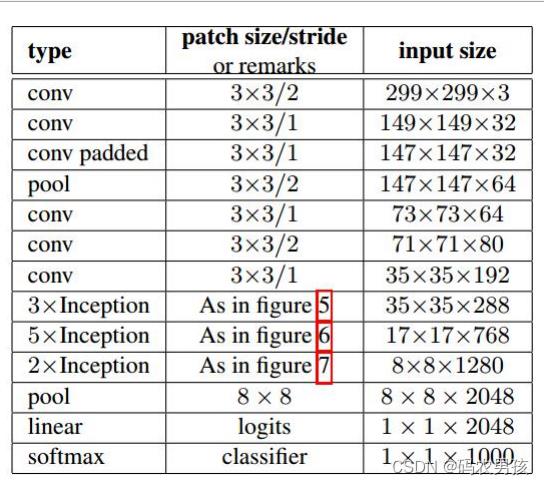
4.GoogLeNet-V4
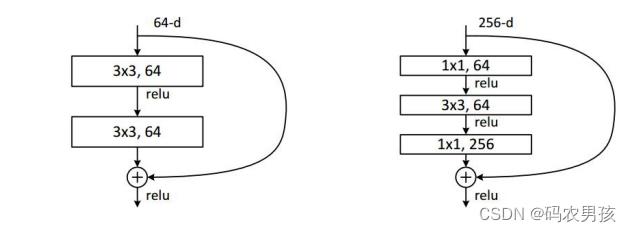
从Inception-v3上看到Inception系列有些“走投无路” , 于是引入当时最火最热的Residual connection思想进行改进。借鉴了ResNet,引入了残差学习,残差结构示意图:
四、GoogLeNet-V4
4.1 简介
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
(Inception-v4, Inception-ResNet,残差连接 对模型训练的影响)
4.2 论文摘要核心总结
- 研究背景1:近年,深度卷积神经网络给图像识别带来巨大提升,例如Inception块
- 研究背景2:最近,残差连接的使用使卷积神经网络得到了巨大提升,如ResNet, 自称ResNet与Inception-v3的精度差不多(dddd)
- 提出问题:是否可以将Inception 与 残差连接结合起来,提高卷积神经网络呢?
- 本文成果1:从实验经验得出,残差连接很大程度的加速了Inception的训练;提出了新的网络模型结构——streamlined architectures
- 本文成果2:对于很宽的residual Inception网络,提出激活值缩放策略,以使网络训练稳定
- 本文成果3:模型融合在ILSVRC上获得3.08%的top-5 error
4.3 Inception-V4
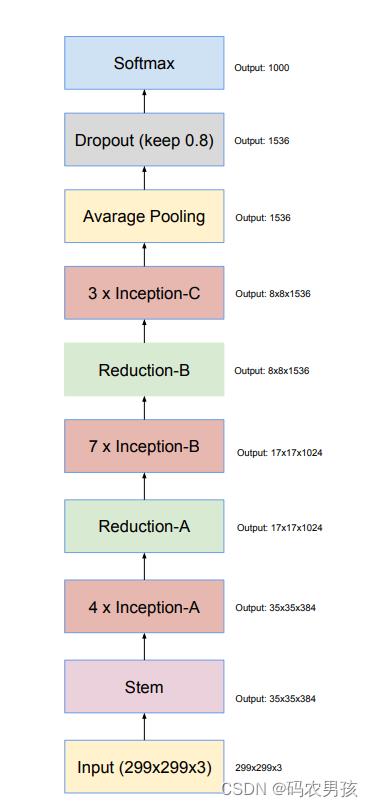
Inception-v4可分为六大模块分别是: Stem、Inception-A、B、C、Reduction-A、B
每个模块都有针对性的设计,模型总共76层。Googlenet的结构总体很复杂但是不难,都是重复的模块堆积起来的,希望大家在看的时候,保持头脑情绪,要不然会觉得这个模型非常杂乱。大家加油!!我们接下来依次来看这六大模块。
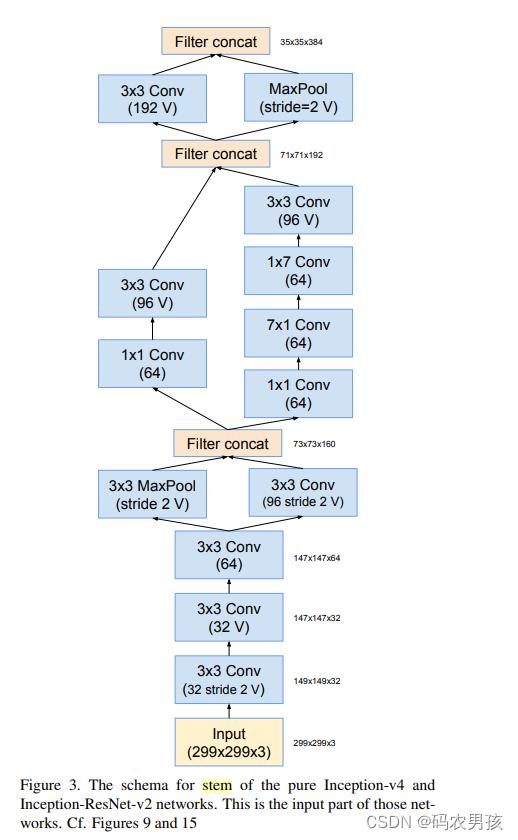
V4模块一:Stem模块
Stem(9层):3个3*3卷积堆叠;高效特征图下降策略;非对称分解卷积

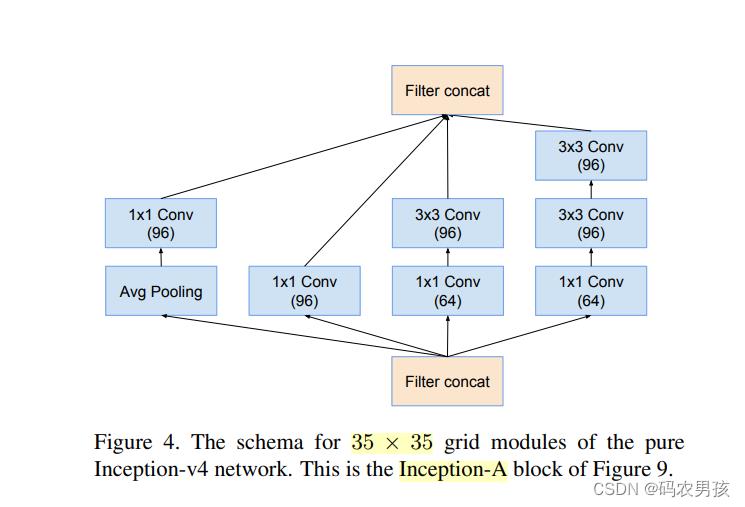
V4模块二:Inception - A模块
Inception-A(3层):标准的Inception module
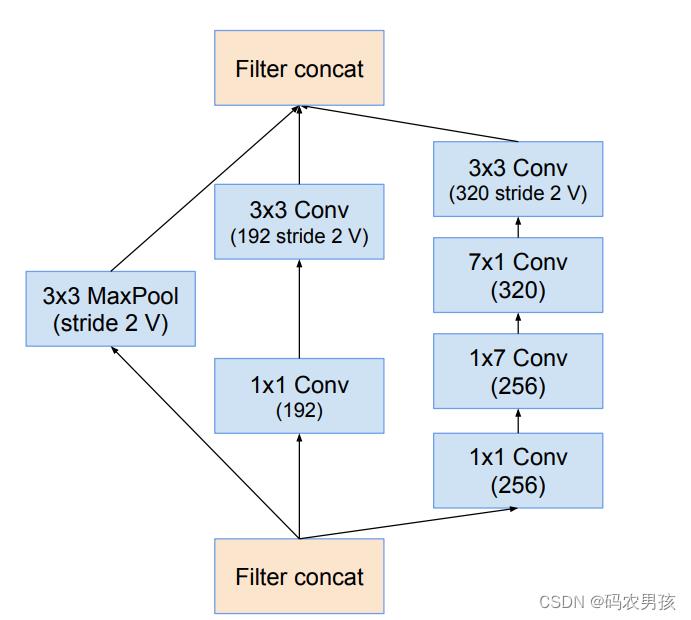
V4模块三:Reduction - A模块
Reduction-A(3层):采用3个分支,其中卷积核的参数 K, l, m, n分别为192, 224,256,38
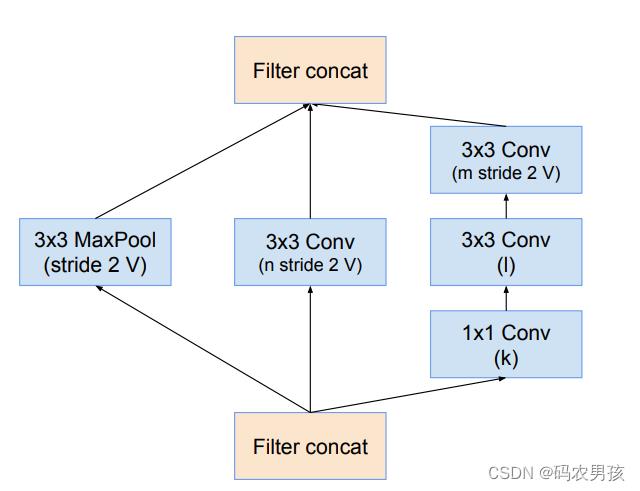
V4模块四:Inception - B模块
Inception-B(5层) :非对称卷积操作部分,参考 Inception-v3
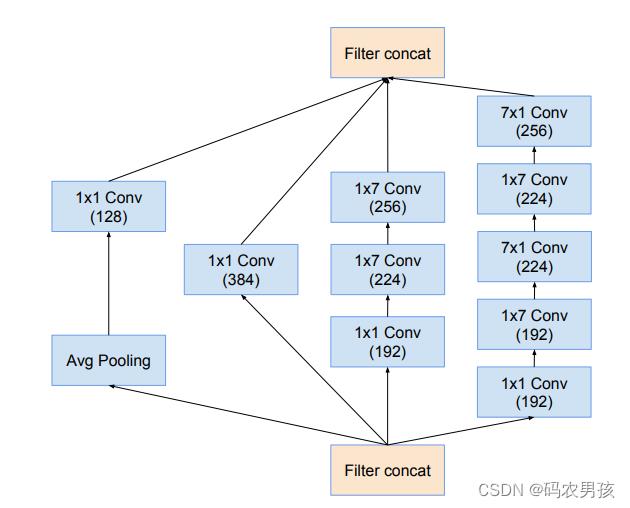
V4模块五:Reduction - B模块
Reduction-B(4层) :非对称卷积操作部分,参考 Inception-v3
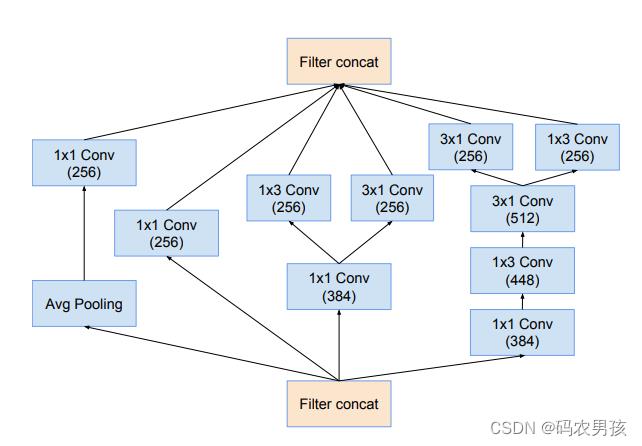
V4模块六:Inception - C模块
Inception-C(4层)
所以Inception-v4总共9+3*4+5*7+4*3+3+4+1 = 76层
4.4 Inception - ResNet
Inception-ResNet V1 、V2 将ResNet中的residual connection思想加到Inception中。
根据Stem和卷积核数量的不同,设计出了Inception-ResNet-V1和V2 ,六大模块分别是: Stem、Inception-ResNetA、B、C、Reduction-A、B。结构图如下图所示:
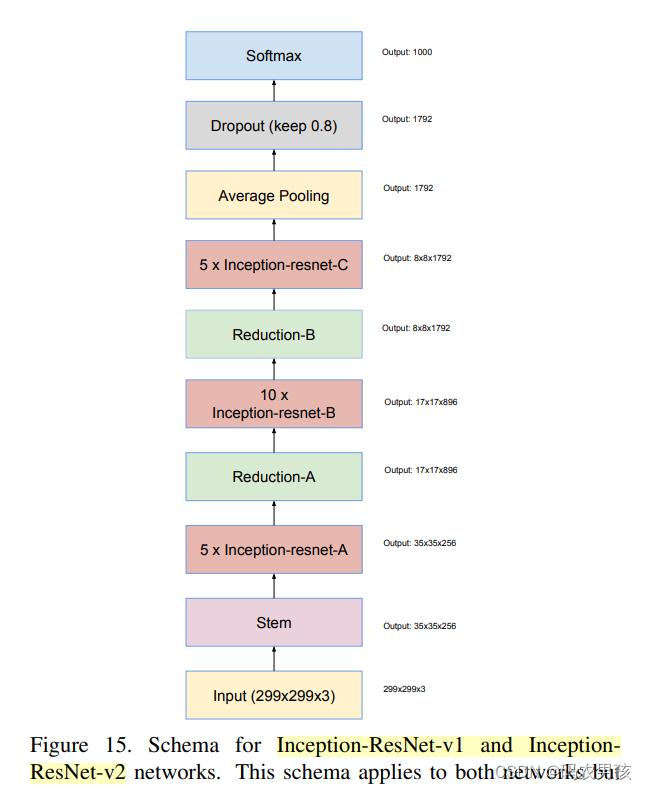
① V1 、V2中Stem模块对比
V1无分支(7层); V2与Inception-V4相同(9层)

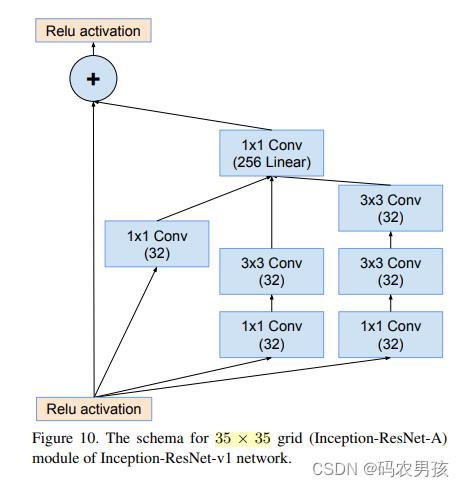
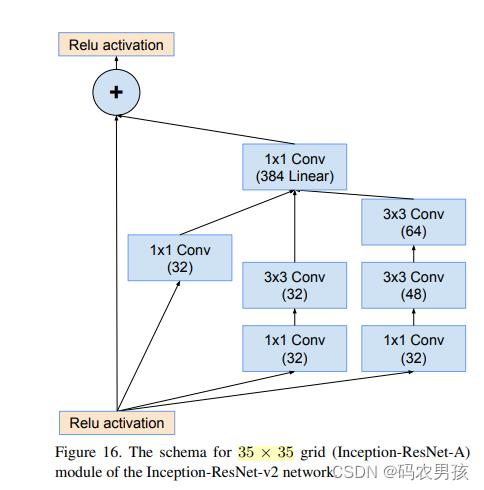
② V1 、V2中Inception - ResNet A模块对比
Inception-ResNet-A模块(4层): 均处理35*35大小的特征图
V1卷积核数量少 ;V2卷积核数量多
③ V1 、V2中RuductionA模块对比
Reduction-A模块(3层): 将35*35大小的特征图降低至17*17
Inception-V4和两个Inception-ResNet都一样,参考V4的ReductionA模块介绍
④ V1 、V2中 Inception - ResNet B模块对比
Inception-ResNet-B模块(4层): 处理17*17大小的特征图 V1卷积核数量少 V2卷积核数量多
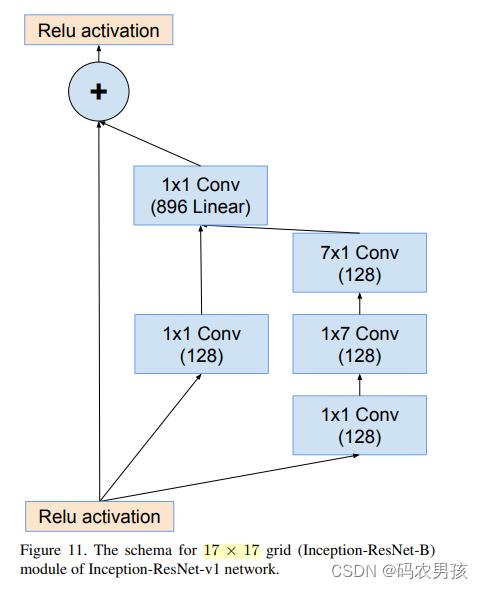
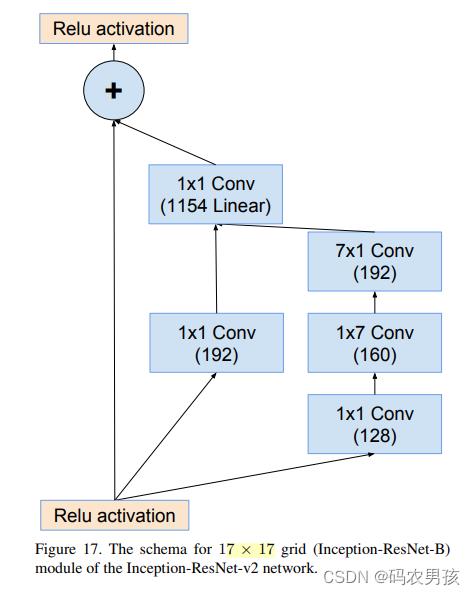
⑤ V1 、V2中Ruduction B模块对比
Reduction-B模块(3层): 将17*17大小的特征图降低至7*7
左图为V1 右图为V2,文中描述为 the wider Inception-ResNet-V1
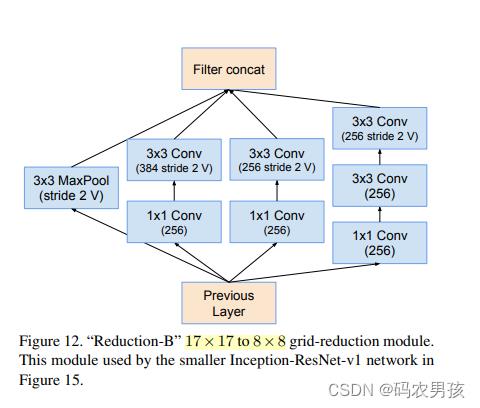
 ⑥ V1 、V2中 Inception - ResNet C模块对比
⑥ V1 、V2中 Inception - ResNet C模块对比
Inception-ResNet-C模块(4层): 处理8*8大小的特征图
V1卷积核数量少 V2卷积核数量多
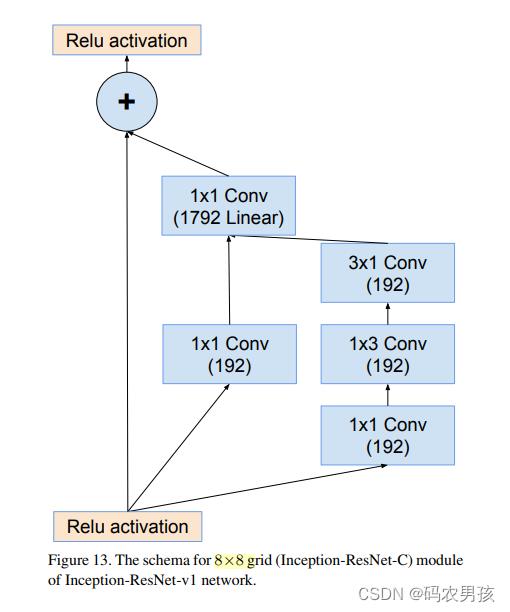
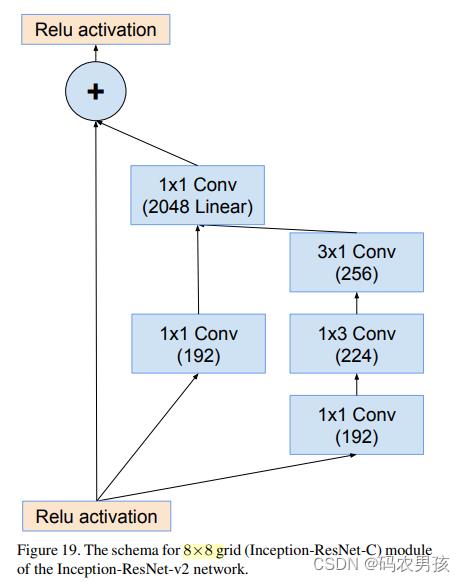
总结
Inception-ResNet-V1共 7+5*4+3+10*4+3+5*4+1=94层
Inception-ResNet-V2共 9+5*4+3+10*4+3+5*4+1=96层
4.5 激活值缩放 Activation Scaling
为了让模型训练稳定,在残差模块中对残差进行数 值大小的缩放,通常乘以0.1至0.3之间的一个数。但是这个操作并不是必须的。
4.6 结构代码实现
Inception - v4
# 基础卷积
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
#%%
# 1/6 Stem:
# Stem
class Mixed_3a(nn.Module):
def __init__(self):
super(Mixed_3a, self).__init__()
self.maxpool = nn.MaxPool2d(3, stride=2)
self.conv = BasicConv2d(64, 96, kernel_size=3, stride=2)
def forward(self, x):
x0 = self.maxpool(x)
x1 = self.conv(x)
out = torch.cat((x0, x1), 1)
return out
# Stem
class Mixed_4a(nn.Module):
def __init__(self):
super(Mixed_4a, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1)
)
self.branch1 = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1),
BasicConv2d(64, 64, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(64, 64, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(64, 96, kernel_size=(3,3), stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
return out
# Stem
class Mixed_5a(nn.Module):
def __init__(self):
super(Mixed_5a, self).__init__()
self.conv = BasicConv2d(192, 192, kernel_size=3, stride=2)
self.maxpool = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.conv(x)
x1 = self.maxpool(x)
out = torch.cat((x0, x1), 1)
return out
#%%
# 2/6 Inception-A
class Inception_A(nn.Module):
def __init__(self):
super(Inception_A, self).__init__()
self.branch0 = BasicConv2d(384, 96, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(384, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(384, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(384, 96, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
#%%
# 3/6 Reduction-A
class Reduction_A(nn.Module):
def __init__(self):
super(Reduction_A, self).__init__()
self.branch0 = BasicConv2d(384, 384, kernel_size=3, stride=2)
self.branch1 = nn.Sequential(
BasicConv2d(384, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=3, stride=1, padding=1),
BasicConv2d(224, 256, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
#%%
# 4/6 Inception-B
class Inception_B(nn.Module):
def __init__(self):
super(Inception_B, self).__init__()
self.branch0 = BasicConv2d(1024, 384, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(224, 256, kernel_size=(7,1), stride=1, padding=(3,0))
)
self.branch2 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 192, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(192, 224, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(224, 224, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(224, 256, kernel_size=(1,7), stride=1, padding=(0,3))
)
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(1024, 128, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
#%%
# 5/6 Reduction-B
class Reduction_B(nn.Module):
def __init__(self):
super(Reduction_B, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 192, kernel_size=3, stride=2)
)
self.branch1 = nn.Sequential(
BasicConv2d(1024, 256, kernel_size=1, stride=1),
BasicConv2d(256, 256, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(256, 320, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(320, 320, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
#%%
# 6/6 Inception-C
class Inception_C(nn.Module):
def __init__(self):
super(Inception_C, self).__init__()
self.branch0 = BasicConv2d(1536, 256, kernel_size=1, stride=1)
self.branch1_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
self.branch1_1a = BasicConv2d(384, 256, kernel_size=(1,3), stride=1, padding=(0,1))
self.branch1_1b = BasicConv2d(384, 256, kernel_size=(3,1), stride=1, padding=(1,0))
self.branch2_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
self.branch2_1 = BasicConv2d(384, 448, kernel_size=(3,1), stride=1, padding=(1,0))
self.branch2_2 = BasicConv2d(448, 512, kernel_size=(1,3), stride=1, padding=(0,1))
self.branch2_3a = BasicConv2d(512, 256, kernel_size=(1,3), stride=1, padding=(0,1))
self.branch2_3b = BasicConv2d(512, 256, kernel_size=(3,1), stride=1, padding=(1,0))
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(1536, 256, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1_0 = self.branch1_0(x)
x1_1a = self.branch1_1a(x1_0)
x1_1b = self.branch1_1b(x1_0)
x1 = torch.cat((x1_1a, x1_1b), 1)
x2_0 = self.branch2_0(x)
x2_1 = self.branch2_1(x2_0)
x2_2 = self.branch2_2(x2_1)
x2_3a = self.branch2_3a(x2_2)
x2_3b = self.branch2_3b(x2_2)
x2 = torch.cat((x2_3a, x2_3b), 1)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
#%% md
# 2. Inception-V4定义
#%%
# InceptionV4 类
class InceptionV4(nn.Module):
def __init__(self, num_classes=1001):
super(InceptionV4, self).__init__()
# Special attributs
self.input_space = None
self.input_size = (299, 299, 3)
self.mean = None
self.std = None
# Modules
self.features = nn.Sequential(
# 1/6: Stem
BasicConv2d(3, 32, kernel_size=3, stride=2), # marked with V
BasicConv2d(32, 32, kernel_size=3, stride=1), # marked with V
BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1), # not marked with V
Mixed_3a(),
Mixed_4a(),
Mixed_5a(),
# 2/6 Inception-A
Inception_A(),
Inception_A(),
Inception_A(),
Inception_A(),
# 3/6 Reduction-A
Reduction_A(), # Mixed_6a
# 4/6 Inception-B
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
# 5/6 Reduction-B
Reduction_B(), # Mixed_7a
# 6/6 Inception-C
Inception_C(),
Inception_C(),
Inception_C()
)
self.last_linear = nn.Linear(1536, num_classes)
def logits(self, features):
#Allows image of any size to be processed
adaptiveAvgPoolWidth = features.shape[2] # 这两行代码实现特征图池化到1*1大小
x = F.avg_pool2d(features, kernel_size=adaptiveAvgPoolWidth) # 这两行代码实现特征图池化到1*1大小
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
#%%
# 创建 Inception v4 的函数
def inceptionv4(num_classes=1001, pretrained='imagenet'):
if pretrained:
settings = pretrained_settings['inceptionv4'][pretrained]
assert num_classes == settings['num_classes'], \\
"num_classes should be , but is ".format(settings['num_classes'], num_classes)
# both 'imagenet'&'imagenet+background' are loaded from same parameters
model = InceptionV4(num_classes=1001)
model.load_state_dict(model_zoo.load_url(settings['url']))
if pretrained == 'imagenet':
new_last_linear = nn.Linear(1536, 1000)
new_last_linear.weight.data = model.last_linear.weight.data[1:]
new_last_linear.bias.data = model.last_linear.bias.data[1:]
model.last_linear = new_last_linear
model.input_space = settings['input_space']
model.input_size = settings['input_size']
model.input_range = settings['input_range']
model.mean = settings['mean']
model.std = settings['std']
else:
model = InceptionV4(num_classes=num_classes)
return model
Inception-ResNet
# 基础卷积
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
#%%
# 标准Inception module
class Mixed_5b(nn.Module):
def __init__(self):
super(Mixed_5b, self).__init__()
# branch0: 1*1
self.branch0 = BasicConv2d(192, 96, kernel_size=1, stride=1)
# branch1: 1*1, 5*5
self.branch1 = nn.Sequential(
BasicConv2d(192, 48, kernel_size=1, stride=1),
BasicConv2d(48, 64, kernel_size=5, stride=1, padding=2)
)
# branch2: 1*1, 3*3, 3*3
self.branch2 = nn.Sequential(
BasicConv2d(192, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
# branch3: avgPool, 1*1
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(192, 64, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1) # 96+64+96+64 = 320
return out
#%%
# Inception-Resnet-A figure 16.
class Block35(nn.Module):
def __init__(self, scale=1.0):
super(Block35, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(320, 32, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 48, kernel_size=3, stride=1, padding=1),
BasicConv2d(48, 64, kernel_size=3, stride=1, padding=1)
)
self.conv2d = nn.Conv2d(128, 320, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
#%%
# Reduction-A figure7.
class Mixed_6a(nn.Module):
def __init__(self):
super(Mixed_6a, self).__init__()
self.branch0 = BasicConv2d(320, 384, kernel_size=3, stride=2)
self.branch1 = nn.Sequential(
BasicConv2d(320, 256, kernel_size=1, stride=1),
BasicConv2d(256, 256, kernel_size=3, stride=1, padding=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
#%%
# Inception-resnet-B figure17.
class Block17(nn.Module):
def __init__(self, scale=1.0):
super(Block17, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(1088, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 128, kernel_size=1, stride=1),
BasicConv2d(128, 160, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(160, 192, kernel_size=(7, 1), stride=1, padding=(3, 0))
)
self.conv2d = nn.Conv2d(384, 1088, kernel_size=1, stride=1) # 论文为1154,此处为1088,这个参数必须与输入的一样
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
#%%
# Reduction-B figure 18.
class Mixed_7a(nn.Module):
def __init__(self):
super(Mixed_7a, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=2)
)
self.branch2 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=1, padding=1),
BasicConv2d(288, 320, kernel_size=3, stride=2)
)
self.branch3 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
#%%
# Inception-C figure 19.
class Block8(nn.Module):
def __init__(self, scale=1.0, noReLU=False):
super(Block8, self).__init__()
self.scale = scale
self.noReLU = noReLU
self.branch0 = BasicConv2d(2080, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(2080, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=(1, 3), stride=1, padding=(0, 1)),
BasicConv2d(224, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
)
self.conv2d = nn.Conv2d(448, 2080, kernel_size=1, stride=1)
if not self.noReLU:
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
if not self.noReLU:
out = self.relu(out)
return out
#%% md
# 2. Inception-ResNet-V2定义
#%%
# Inception ResNet V2 类定义
class InceptionResNetV2(nn.Module):
def __init__(self, num_classes=1001):
super(InceptionResNetV2, self).__init__()
# Special attributs
self.input_space = None
self.input_size = (299, 299, 3)
self.mean = None
self.std = None
# Modules
# 1/6 Stem
self.conv2d_1a = BasicConv2d(3, 32, kernel_size=3, stride=2) # marked with V
self.conv2d_2a = BasicConv2d(32, 32, kernel_size=3, stride=1) # marked with V
self.conv2d_2b = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1) # not marked with V
self.maxpool_3a = nn.MaxPool2d(3, stride=2)
self.conv2d_3b = BasicConv2d(64, 80, kernel_size=1, stride=1)
self.conv2d_4a = BasicConv2d(80, 192, kernel_size=3, stride=1)
self.maxpool_5a = nn.MaxPool2d(3, stride=2)
# 2/6
self.mixed_5b = Mixed_5b() # 额外增加的
self.repeat = nn.Sequential( # Inception-resnet-A * 10, 论文是*5
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17)
)
# 3/6 Reduction-A figure7.
self.mixed_6a = Mixed_6a()
# 4/6 Inception-resnet-B * 20, figure17.
self.repeat_1 = nn.Sequential(
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10)
)
# 5/6 Reduction-B figure 18. 8*8*1792
self.mixed_7a = Mixed_7a()
# 6/6 Inception-C *9 figure 19.
self.repeat_2 = nn.Sequential(
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20)
)
self.block8 = Block8(noReLU=True)
self.conv2d_7b = BasicConv2d(2080, 1536, kernel_size=1, stride=1)
self.avgpool_1a = nn.AvgPool2d(8, count_include_pad=False)
self.last_linear = nn.Linear(1536, num_classes)
def features(self, input):
# 1/6 Stem: figure 14.
x = self.conv2d_1a(input) # 149*149*32
x = self.conv2d_2a(x) # 147*147*32
x = self.conv2d_2b(x) # 149*149*64
x = self.maxpool_3a(x) # 73*73*64
x = self.conv2d_3b(x) # 73*73*80
x = self.conv2d_4a(x) # 71*71*192
x = self.maxpool_5a(x) # 35*35*192
# 2/6 Inception-resnet-A: figure 16.
x = self.mixed_5b(x) # 35*35*320 标准Inception moudle, 额外增加的
x = self.repeat(x) # 35*35*320 论文是35*35*384
# 3/6 Reduction-A figure7.
x = self.mixed_6a(x) # 17*17*1088
# 4/6 Inception-resnet-B figure17.
x = self.repeat_1(x) # 17*17*1088
# 5/6 Reduction-B figure 18.
x = self.mixed_7a(x) # 8*8*2080
# 6/6 Inception-C figure 19.
x = self.repeat_2(x) # 8*8*2080
x = self.block8(x) # 该模块输出前未用Relu,原因未知
# 1*1卷积压缩特征图厚度:2080 --> 1536
x = self.conv2d_7b(x) # 8*8*1536
return x
def logits(self, features):
x = self.avgpool_1a(features) # 1*1*1536
x = x.view(x.size(0), -1) # 1536
x = self.last_linear(x) # 1000
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
#%%
# 创建模型的函数
def inceptionresnetv2(num_classes=1000, pretrained='imagenet'):
r"""InceptionResNetV2 model architecture from the
`"InceptionV4, Inception-ResNet..." <https://arxiv.org/abs/1602.07261>`_ paper.
"""
if pretrained:
settings = pretrained_settings['inceptionresnetv2'][pretrained]
assert num_classes == settings['num_classes'], \\
"num_classes should be , but is ".format(settings['num_classes'], num_classes)
# both 'imagenet'&'imagenet+background' are loaded from same parameters
model = InceptionResNetV2(num_classes=1001)
model.load_state_dict(model_zoo.load_url(settings['url']))
if pretrained == 'imagenet':
new_last_linear = nn.Linear(1536, 1000)
new_last_linear.weight.data = model.last_linear.weight.data[1:]
new_last_linear.bias.data = model.last_linear.bias.data[1:]
model.last_linear = new_last_linear
model.input_space = settings['input_space']
model.input_size = settings['input_size']
model.input_range = settings['input_range']
model.mean = settings['mean']
model.std = settings['std']
else:
model = InceptionResNetV2(num_classes=num_classes)
return model
部分知识来源参考资料:百度百科 GoogLeNet

以上是关于深度学习图像分类网络:GoogLeNet(V1-V4)模型搭建解读(附代码实现)的主要内容,如果未能解决你的问题,请参考以下文章