正面刚CNN,Transformer居然连犯错都像人类
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正面刚CNN,Transformer居然连犯错都像人类相关的知识,希望对你有一定的参考价值。
梦晨 水木番 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这是你眼里的一只猫:

这是CNN眼里的一只猫:

这是ViT (Vision Transformer)眼里的一只猫:

从去年起,Transformer忙着跨界CV,如ViT在图像分类上准确率已超过CNN,大有取代之势。
这背后的原因是什么?
最近普林斯顿的一项研究认为,Transformer的运作方式更接近人类,连犯错的方式都和人类一样。
研究团队在图像分类的准确率之外,增加了对错误类型的分析。
结果发现,与CNN相比,ViT更擅长判断形状。
此前在ICLR2019上发表的一篇论文提出,用ImageNet训练的CNN模型更倾向于通过纹理分类图像。
如下图中混合了大象皮肤纹理的猫被判断成了大象。

△来自arXiv:1811.12231
虽然说这更可能和ImageNet的数据纹理信息更丰富有关。
但ViT模型,使用相同数据集训练,就倾向于通过形状分类图像,并且表现比CNN更好。
用形状分类物体也是人类的倾向。不信的话,试试回答下图的问题:右面的三个物体中哪个与左边的是同类?

△来自DOI: 10.1016/0749-596X(92)90040-5
这意味着,使用ViT不仅能建立更高效的视觉神经网络,甚至对理解人类视觉的运作方式都有帮助。
这么神奇?
下面来看看CNN与Transformer与人脑的联系分别在哪里。
CNN:从猫身上获得灵感
大脑的不同区域对视觉信息有不同的处理方式,CNN主要模仿的是“腹侧流 (Ventral Stream)”在物体识别、分类上的运作方式。
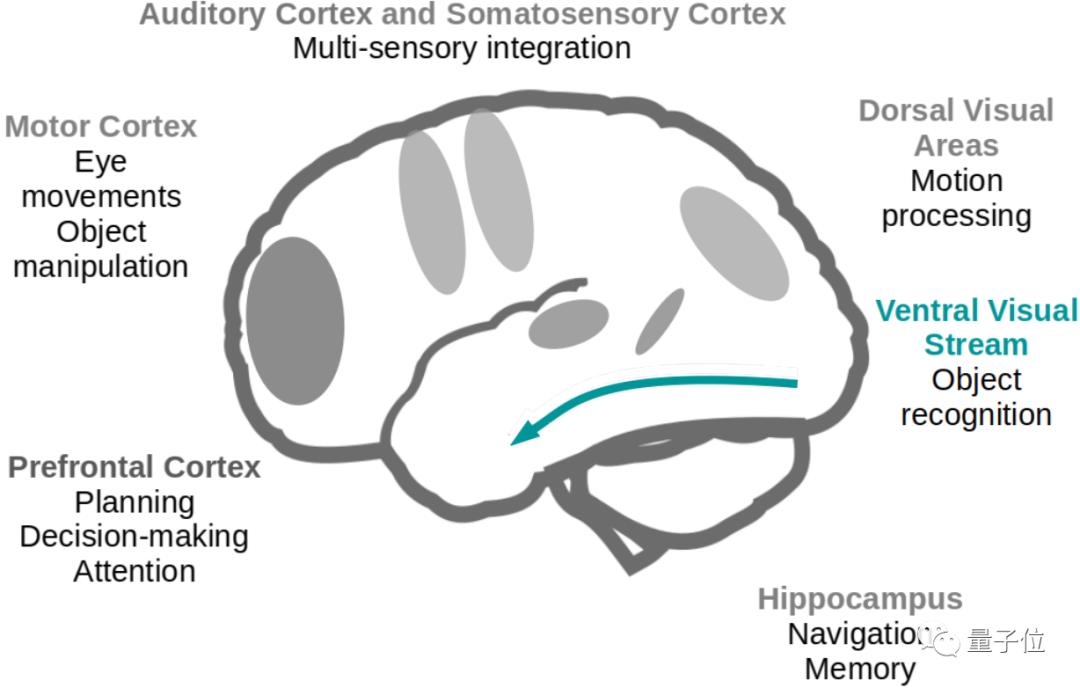
1981年获得诺贝尔生理和医学奖,由神经科学家Hubel和Wiesel发现猫的视觉皮层中有简单细胞和复杂细胞两种。
每个简单细胞对一个特定角度的长条物体反应最强烈,而复杂细胞接受许多个简单细胞传出的信号,就能做到将不同角度的长条物体识别成同一个。
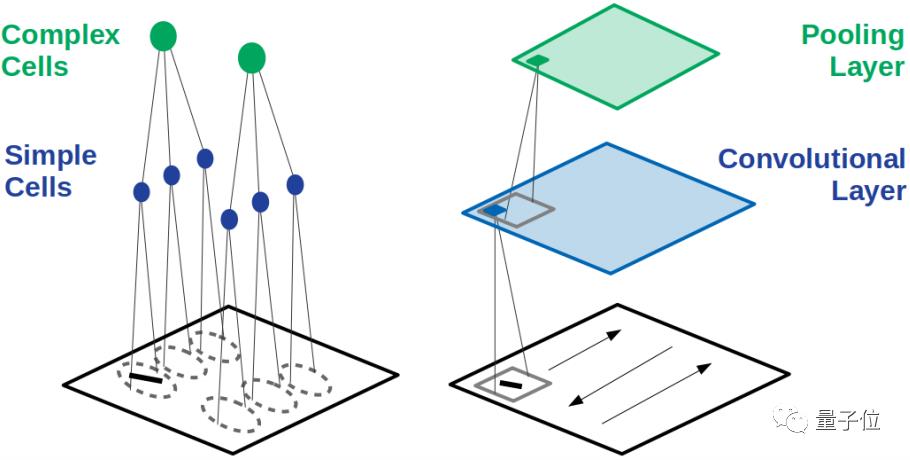
在CNN中,这两种细胞的工作被分配给了卷积层和池化层。
卷积层中的神经元像简单细胞一样,仅和上一层的部分区域相连接,学习局部特征。

而最大池化 (Max Pooling)操作就是模仿复杂细胞,对简单细胞中信号最强的作出反应。

这就是CNN从动物视觉中学到的第一个重要特性“局部连接”。
在卷积层和池化层中使用局部连接,仅在最后输出结果前加入全连接层,使CNN获得了“平移不变性”。
也就是把图像稍微挪动位置,也可以识别成相同的特征。

另外,与全连接的神经网络相比,局部连接的方式还大大减少了需要的参数量,降低训练成本。
为了进一步节省资源、提高效率,CNN在此基础上发展出另一个特性“权重共享”。
隐藏层中的每个神经元都使用相同的过滤器,也就是卷积核。
就像这样:

△来自freecodecamp
卷积核中的相同的参数使用在每一次卷积操作中,进一步降低了需要的参数量。
不过,与生物视神经的不同之处也随之出现了。
ViT: 拥有多个注意力中心
让我们再来看看人眼的注意力机制。
人是不能同时看清视野左右两端边缘上的物体的。
当你把目光聚焦到一边时,另一边只能模糊的感觉到有无物体存在,看不清具体的形状或颜色。
不信的话现在就可以试一试。
这是因为感光细胞在视网膜上的分布并是不均匀的。
人眼的感光细胞分为视杆细胞(Rods)和视锥细胞(Cones)两种。

视杆细胞主要负责感知光的亮度,不能很好地分辨细节。
而在光亮度足够时能分辨颜色和形状的视锥细胞,集中分布在视网膜中心处。
只有在目光聚焦的位置上可以看清细节,所以我们观察时要不停地转动眼球,将目光聚焦在视野上的不同位置,这就产生了注意力机制。

不过比人眼更先进的是,神经网络可以拥有多个注意力,被称为多头注意力(Multi-Head Attention)机制。
一句话是一个序列
在NLP任务中,Transformer将文本作为一个序列来处理。
有了注意力机制,就可以在长序列中注意到每个词与其他词间的关系,实现上下文关联的机器翻译。

一张图也是一个序列
谷歌大脑团队进一步提出,图像在分解成小块之后,再配合位置编码,也可以当作一个序列来处理。
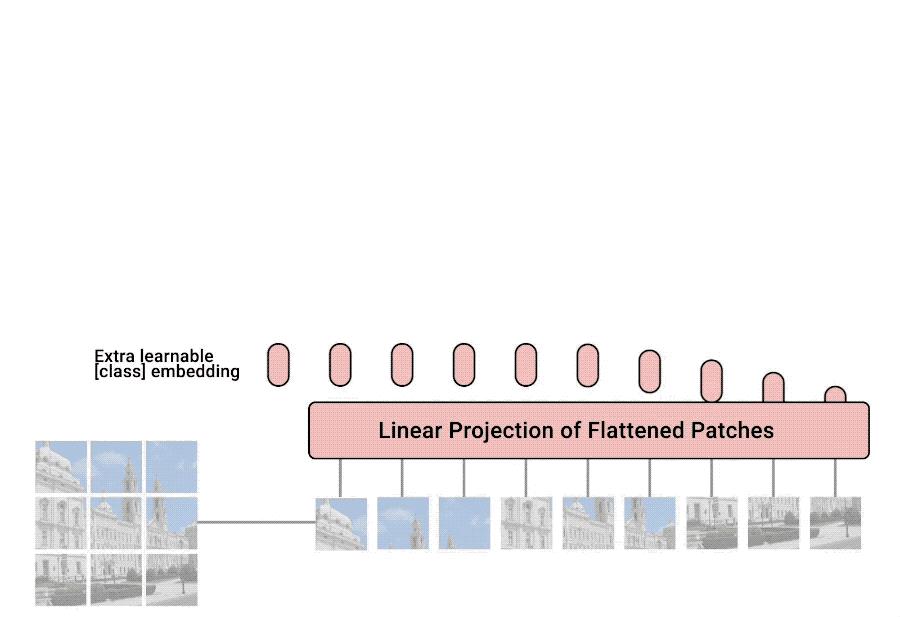
就像在NLP领域Transformer可以有效注意到一个词与上下文的关系一样,在CV领域也可以汇总图像的全局特征进行学习。
用于图像分类的ViT就此诞生,开启了Transformer的跨界刷屏之旅。
犯错的方式都和人一样
在普林斯顿大学对比CNN和ViT的这篇论文中,还建立了错误一致性这个指标来对各个模型进行评判。
从WordNet中选取了16个概念(如飞机、熊、键盘等)来衡量CNN和ViT犯错的类型。
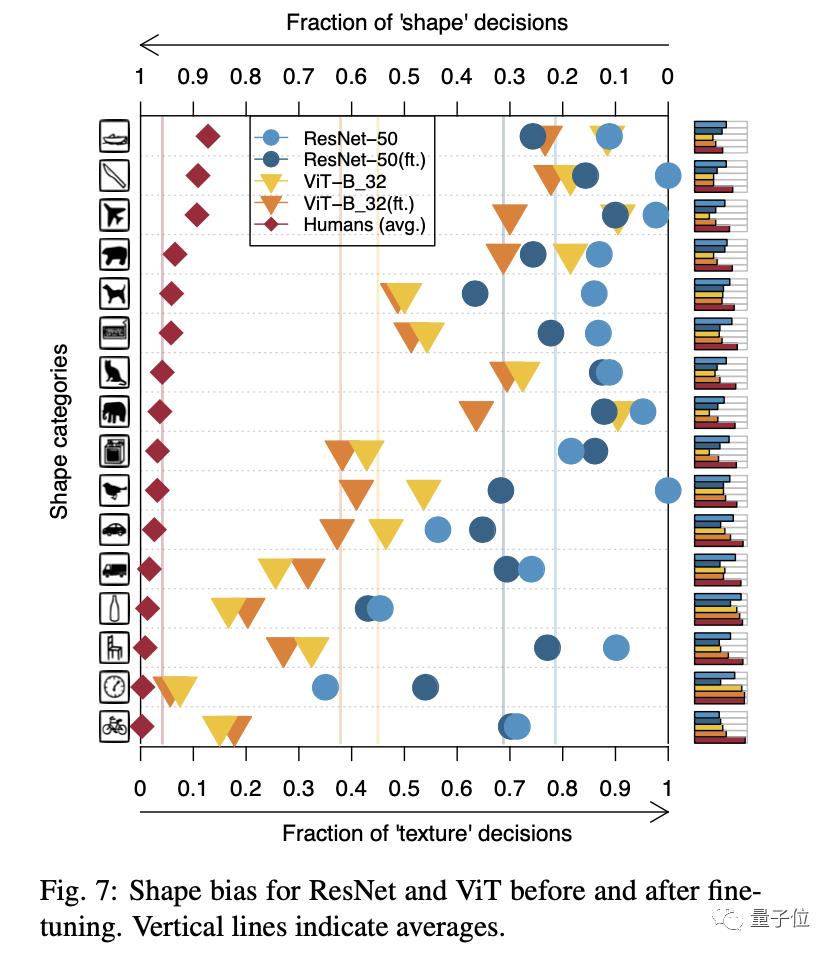
从结果可以看出,ViT和人类一样,更倾向于通过形状判断物体。
未来趋势
ViT问世之初来势汹汹,以至于很多人都在问,注意力机制这是要取代卷积吗?
从最近的趋势看来,Transformer在CV领域的应用,反倒是刺激了二者的结合和统一。
卷积擅长提取细节,要掌握全局信息往往需要堆叠很多个卷积层。
注意力善于把握整体,但又需要大量的数据进行训练。
如果把两者结合起来,是不是能够取长补短?
把注意力引入CNN的有谷歌推出的BoTNet就是简单把ResNet的最后瓶颈块中的3x3卷积替换成全局自注意力,没有别的改变,就在减少开销的情况下提高了性能。

之后麦吉尔大学和微软又把卷积引入Transformer架构的CvT(Convolutional vision Transformers),去除了Transformer中的位置编码,提升对于高分辨率视觉任务的效果。
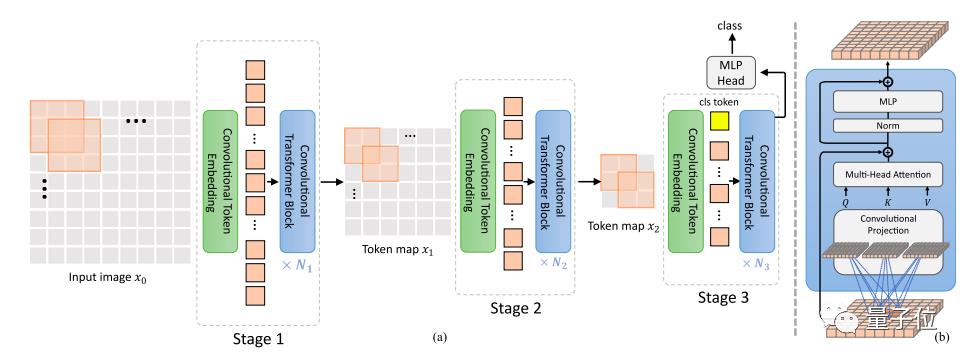
最近,谷歌大脑Quoc Le团队利用简单的相对注意力把两大架构自然地统一起来,提出了混合模型CoAtNet。
看来,强强联合果然不错。
这还没结束,除了卷积与注意力的协作以外,甚至有人从更高的层面开始尝试将二者统一。
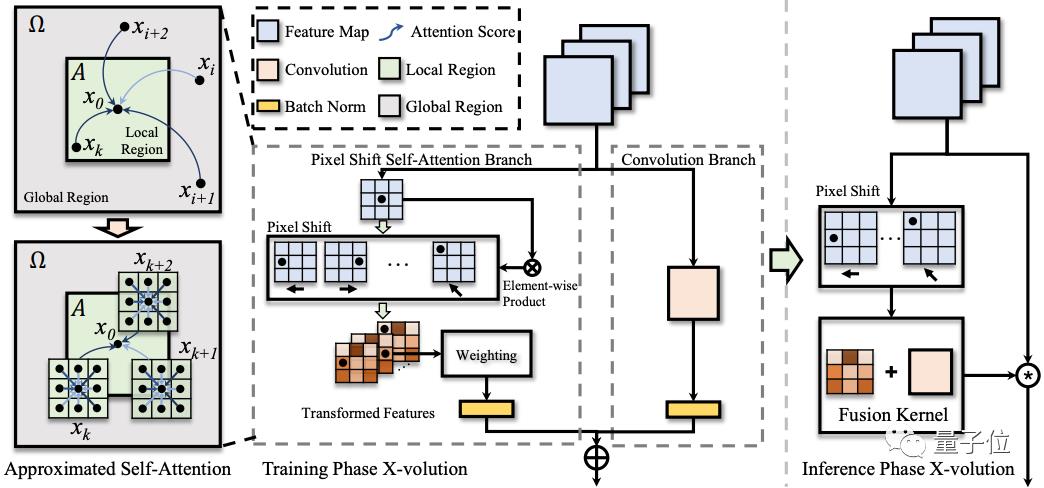
上海交大和华为的研究,用对卷积特征的变换操作达到近似自注意力的效果,提出全新的算子X-Volution,可以在任何现代神经网络结构中使用。
港中文提出更是将CNN、Transformer以及MLP都统一在一起,提出了用于多头上下文聚合的通用结构Container,取得了超越三大架构及混合架构的成绩。

ViT:
https://arxiv.org/abs/2010.11929
ViT比CNN更像人类:
https://arxiv.org/abs/2105.07197
CNN纹理偏差的来源:
https://arxiv.org/abs/1911.09071
BoTNet:
https://arxiv.org/abs/2101.11605
CvT:
https://arxiv.org/abs/2103.15808
CoAtNet:
https://arxiv.org/abs/2106.04803
X-Volution:
https://arxiv.org/abs/2106.02253
Container:
https://arxiv.org/abs/2106.01401
参考链接:
[1]https://arxiv.org/abs/1706.09077
[2]https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
[3]https://arxiv.org/pdf/2101.01169.pdf
[4]https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
以上是关于正面刚CNN,Transformer居然连犯错都像人类的主要内容,如果未能解决你的问题,请参考以下文章