CNN和Transformer相结合的模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN和Transformer相结合的模型相关的知识,希望对你有一定的参考价值。
参考技术A ©作者 | 小欣CNN广泛应用于计算机视觉的各种任务中,比如分类,检测,分割,CNN通过共享卷积核提取特征,减少网络参数数量,提高模型效率,另一方面CNN具有平移不变性,即无论特征被移动到图像的哪个位置,网络都能检测到这些特征。
尽管CNN存在很多优势,但是其感受野通常很小,不利于捕获全局特征。
视觉Transformer由于能够捕获一张图片的全局信息,因此在许多视觉任务中超越许多CNN结构。
ViT是第一个替代CNN,使用纯Transformer的结构,输入一张224×224×3的图片,ViT将其分成14×14=196个非重叠的patches,每个patch的大小是16×16×3,然后将这些patch输入到堆叠的多个transformer编码器中。
CNN的成功依赖于其两个固有的归纳偏置,即平移不变性和局部相关性,而视觉Transformer结构通常缺少这种特性,导致通常需要大量数据才能超越CNN的表现,CNN在小数据集上的表现通常比纯Transformer结构要好。
CNN感受野有限导致很难捕获全局信息,而Transformer可以捕获长距离依赖关系,因此ViT出现之后有许多工作尝试将CNN和Transformer结合,使得网络结构能够继承CNN和Transformer的优点,并且最大程度保留全局和局部特征。
Transformer是一种基于注意力的编码器-解码器结构,最初应用于自然语言处理领域,一些研究最近尝试将Transformer应用到计算机视觉领域。
在Transformer应用到视觉之前,卷积神经网络是主要研究内容。受到自注意力在NLP领域的影响,一些基于CNN的结构尝试通过加入自注意力层捕获长距离依赖关系,也有另外一些工作直接尝试用自注意力模块替代卷积,但是纯注意力模块结构仍然没有最先进的CNN结构表现好。
Transformer中有两个主要部分,多头自注意力层和全连接层,最近,Cordonnier et al.在研究中表明卷积可以通过使用多头自注意力层达到同样的效果。
Transformer 理论上比CNN能得到更好的模型表现,但是因为计算全局注意力导致巨大的计算损失,特别是在浅层网络中,特征图越大,计算复杂度越高,因此一些方法提出将Transformer插入到CNN主干网络中,或者使用一个Transformer模块替代某一个卷积模块。
BoTNet.[1] 通过使用Multi-Head Self-Attention(MHSA)替代ResNet Bottleneck中的3×3卷积,其他没有任何改变,形成新的网络结构,称为Bottleneck Transformer,相比于ResNet等网络提高了在分类,目标检测等任务中的表现,在ImageNet分类任务中达到84.7%的准确率,并且比EfficientNet快1.64倍。
BoTNet中使用的MHSA和Transformer中的MHSA有一定的区别,首先,BoTNet中使用Batch Normalization,而Transformer中使用Layer Normalization,其次,Transformer中使用一个在全连接层中使用一个非线性激活,BoT(Bottleneck Transformer)模块中使用三个非线性激活,最后Transformer中的MHSA模块包含一个输出映射,而BoT中的MHSA没有。
CNN有局部性和平移不变性,局部性关注特征图中相邻的点,平移不变性就是对于不同区域使用相同的匹配规则,虽然CNN的归纳偏差使得网络在少量数据上表现较好,但是这也限制了在充分数据上的表现,因此有一些工作尝试将CNN的归纳偏差引入Transformer加速网络收敛。
DeiT.[2] 为了减小ViT对于大量数据的依赖,Touvron et al.提出了Data-efficient image Transformer(Deit),提高网络在小量数据上的表现,通过使用数据增强和正则化技术,与此同时还引入了蒸馏策略,即使用一个教师网络去指导学生网络,通常来说使用CNN要比Transformer作为教师模型效果要好,CNN模型可以将其归纳偏置引入到Transformer。
作者使用两种蒸馏方式,一种是硬蒸馏,一种是软蒸馏 ,软蒸馏通过计算学生模型和教师模型分别经过softmax之后的KL散度,硬蒸馏通过使用教师模型的预测作为真实标签。
DeiT中引入了一个新的distillation token,和class token的作用类似,和其他token之间通过自注意力交互,作者发现class token和distillation token会收敛于不同的向量,余弦距离为0.06,说明这两个token希望得到相似但不相同的目标,为了证明distillation token的有效性是由于知识蒸馏的作用,通过对比实验将distillation token换成class token,就是使用两个class token,最终效果不如加入distillation token。
对比卷积神经网络和Transformer在Imagenet上的分类表现:
ConViT.[3] 通过引入gated positional self-attention(GPSA)层模仿卷积层带来的局部性,将GPSA替代一部分 self-attention层,然后每一个注意力头通过调整可学习的门控参数来调整对于位置信息和上下文信息的关注程度。GPSA层的输出可以表示为:
其中,
是一个可学习的向量去模仿卷积,
是一个固定的相对位置编码,
是一个可学习门控参数去调整对上下文和位置信息的关注程度。
Cordonnier et al.[4] 在论文中证明多头自注意机制可通过调整头的数量和可学习的位置编码来近似达到卷积层的效果。
对比ConViT和DeiT在Imagenet-1k上的表现,以及不同大小训练集对结果的影响
CeiT.[5] 改变了patch到token的方式,先将图片通过卷积和最大池化再切分成patch,最开始对图片使用卷积操作可以捕获图片的低级特征,即I2
并且使用了Layer-wise class token Attention(LCA)去结合多层特征,提出了Locally-Enhanced Feed-Forward Netword(LeFF),将最开始的全连接层(Feed-forward network)替换成了LeFF层,MSA(Multi-head self-attention)层保持不变,用于捕获全局信息,LeFF层用于捕获局部信息,最终的效果要比DeiT好。
Early Conv.[6] Xiao et al.通过使用多个步长为2的3×3卷积核替代ViT中最初的stem(步长为16的16×16卷积),使得网络在ImageNet-1k上取得1-2%的提高,并且稳定性和泛化能力在下游任务中都有所提高,对于学习率的选择和优化器的选择没有那么敏感,并且收敛速度也更快。
这篇文章表面在ViT模型中使用一个小的卷积核相比于最初的ViT使得模型有更好的泛化能力。
CoAtNet.[7] Dai et al. 提出a Convolution and Attention NetWord(CoAtNet),通过引入深度卷积到注意力模块中,深度卷积中一个卷积核负责一个通道,一个通道只被一个卷积核计算,相比于正常卷积,其参数和运算成本相对比较低,在浅层网络中堆叠卷积层,比较了不同的堆叠方式,比如C-C-C-T,C-T-T-T,C-C-C-T,其中C代表卷积模块,T代表Transformer模块。
通过综合考虑模型泛化能力,迁移能力,模型在训练集上的表现,最后使用C-C-T-T 这种堆叠方式。在没有额外训练数据的情况下,CoAtNet达到了86%的准确率,在ImageNet-21K上预训练时,达到了88.56%的准确率。
参考文献
[1] A. Srinivas, T.-Y. Lin, N. Parmar, J. Shlens, P. Abbeel, and A. Vaswani, “Bottleneck transformers for visual recognition.” in Proc. CVPR, 2021.
[2] H. Touvron, M. Cord, D. Matthijs, F. Massa, A. Sablayrolles, and H. Jegou, “Training data-effificient image transformers & distillation through attention,” in Proc. ICLR, 2021.
[3] S. d’Ascoli, H. Touvron, M. Leavitt, A. Morcos, G. Biroli, and L. Sa gun, “Convit: Improving vision transformers with soft convolutional inductive biases,” in Proc. ICLR, 2021.
[4] Cordonnier, J.-B., Loukas, A., and Jaggi, M. On the relationship between self-attention and convolutional layers. arXiv preprint arXiv:1911.03584, 2019.
[5] K. Yuan, S. Guo, Z. Liu, A. Zhou, F. Yu, and W. Wu, “Incorporating convolution designs into visual transformers,” in Proc. ICCV, 2021.
[6] T. Xiao, M. Singh, E. Mintun, T. Darrell, P. Dollar, and R. B. Girshick, “Early convolutions help transformers see better,” ArXiv, vol. abs/2106.14881, 2021.
[7] Z. Dai, H. Liu, Q. V. Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,” arXiv preprint arXiv:2106.04803, 2021.
私信我领取 目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等 干货学习资源。
国科大提出CNN和Transformer基网模型,Conformer准确率84.1%!
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
Transformer和CNN在处理视觉表征方面都有着各自的优势以及一些不可避免的问题。因此,国科大、鹏城实验室和华为研究人员首次将二者进行了融合并提出全新的Conformer模型,其可以在不显著增加计算量的前提下显著提升了基网表征能力。论文已被ICCV 2021接收。
卷积运算善于提取局部特征,却不具备提取全局表征的能力。
为了感受图像全局信息,CNN必须依靠堆叠卷积层,采用池化操作来扩大感受野。
Visual Transformer的提出则打破了CNN在视觉表征方面的垄断。
得益于自注意力机制,Visual Transformer (ViT、Deit)具备了全局、动态感受野的能力,在图像识别任务上取得了更好的结果。
但是受限于的计算复杂度,Transformer需要减小输入分辨率、增大下采样步长,这造成切分patch阶段损失图像细节信息。
因此,中国科学院大学联合鹏城实验室和华为提出了Conformer基网模型,将Transformer与CNN进行了融合。
Conformer模型可以在不显著增加计算量的前提下显著提升了基网表征能力。目前,论文已被ICCV 2021接收。

论文地址:https://arxiv.org/abs/2105.03889
项目地址:https://github.com/pengzhiliang/Conformer
此外,Conformer中含有并行的CNN分支和Transformer分支,通过特征耦合模块融合局部与全局特征,目的在于不损失图像细节的同时捕捉图像全局信息。

特征图可视化
对一张背景相对复杂的图片的特征进行可视化,以此来说明Conformer捕捉局部和全局信息的能力:
浅层Transformer(DeiT)特征图(c列)相比于ResNet(a列)丢失很多细节信息,而Conformer的Transformer分支特征图(d列)更好保留了局部特征;
从深层的特征图来看,DeiT特征图(g列)相比于ResNet(e列)会保留全局的特征信息,但是噪声会更大一点;
得益于Transformer分支提供的全局特征,Conformer的CNN分支特征图(f列)会保留更加完整的特征(相比于e列);
Transformer分支特征图(h列)相比于DeiT(g列)则是保留了更多细节信息,且抑制了噪声。
网络结构
Conformer是一个并行双体网结构,其中CNN分支采用了ResNet结构,Transformer分支则是采用了ViT结构。
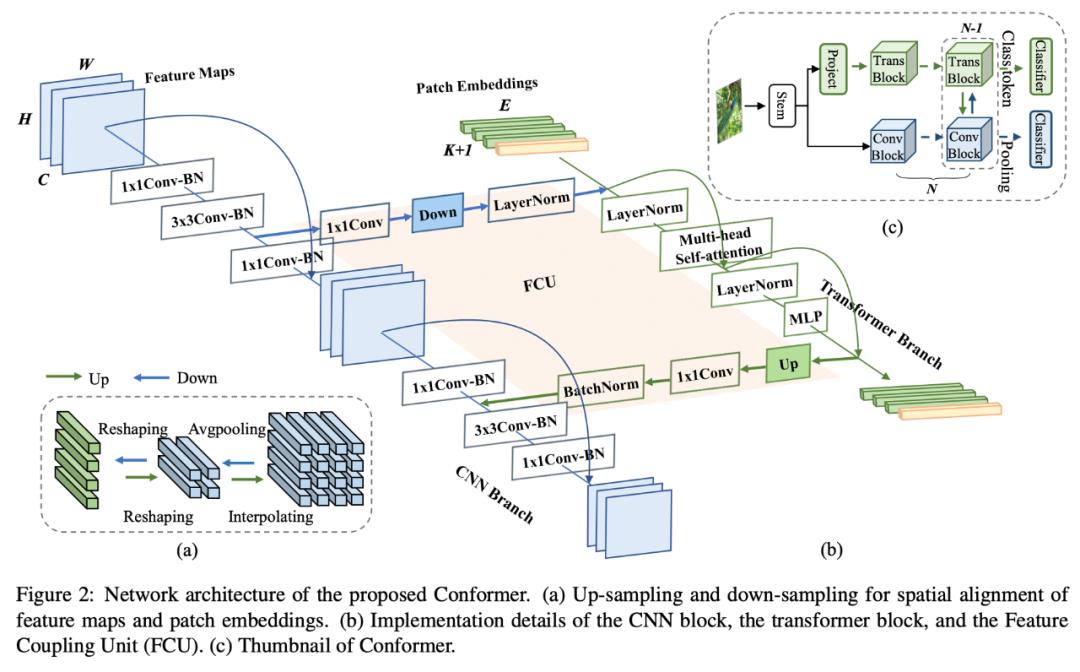
网络结构图
(c)展示了Conformer的缩略图:一个标准的ResNet stem结构,两条并行分支,两个分类器。
(b)展示了每个block中Trans和Conv的连接关系:以2个bottleneck为例,经过第一个bottleneck 3x3卷积后的局部特征经过特征耦合模块(FCU)传给Transformer block。
Transformer block将此局部特征与前一个Trans block的全局特征相加通过当前的trans block,运算结束后再将结果通过FCU模块反传给Conv block。
Conv block的最后一个bottleneck将其与经过1x1卷积后的局部特征相加,一起输入3x3卷积。
之所以将Transformer block夹在两个3x3卷积之间的原因有两个:
bottleneck中3x3卷积的channel比较少,使得FCU的fc层参数不会很大;
3x3卷积具有很强的位置先验信息,保证去掉位置编码后的性能。
实验结果
Conformer网络在ImageNet上做了分类实验,并做为预训练模型在MSCOCO上做了目标检测和实例分割实验。
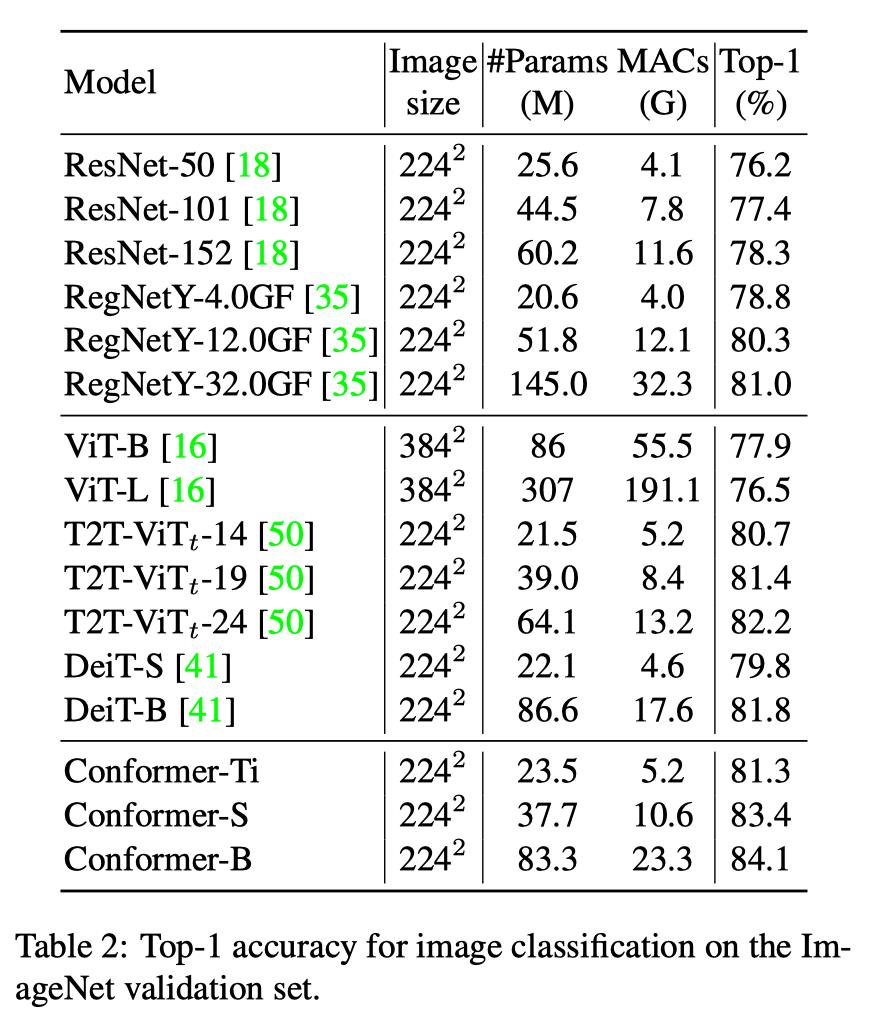
分类准确率对比
参数量为37.7M,计算量为10.6GFlops的Conformer-S超过了参数量为86.6M,计算量为17.6GFlops的DeiT-B 约1.6%的准确率。
当Conformer-S增大参数量到83.3M,准确率则是达到84.1%。
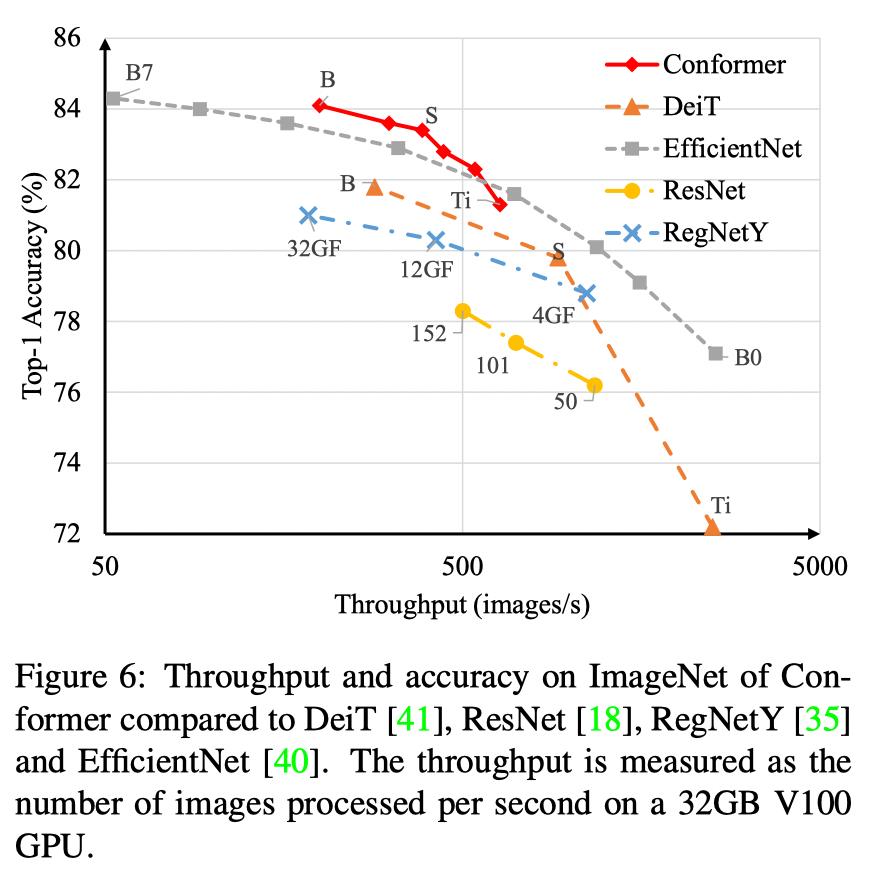
不同基网在分类速度和准确率上的对比
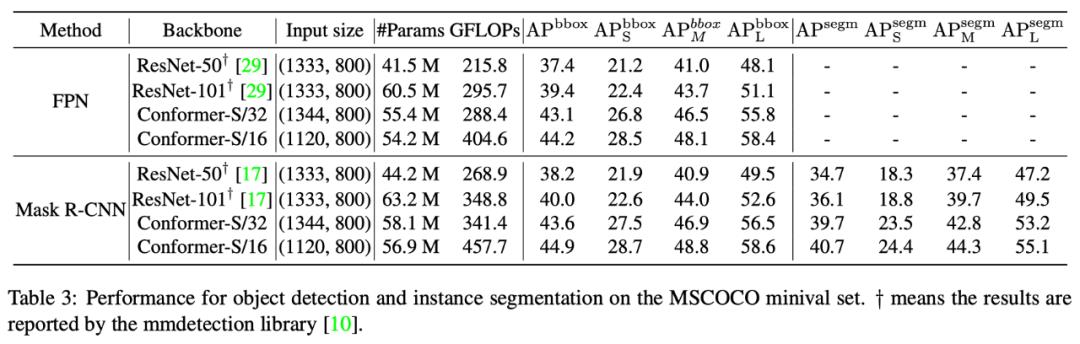
目标检测和实例分割结果的对比
运行帧率为:
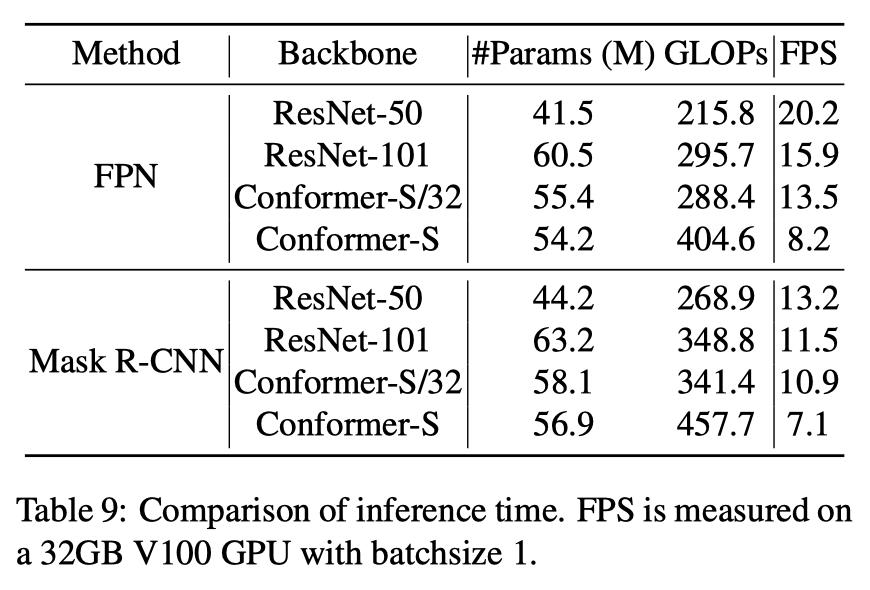
目标检测和实例分割帧率对比
在使用FPN+Faster Mask R-CNN框架时,Conformer-S/32在帧率/参数/计算量可比的情况下,目标检测精度超过Faster RCNN 3.7%,实例分割超过Mask R-CNN 3.6%。
分析总结
Conformer是第一个并行的CNN和Transformer混合网络,通过提出的特征耦合模块FCU在每个阶段的局部特征和全局特征都会进行交互,使得Conformer兼具两者的优势。
在分类上,能够以更小的参数和计算量取得更高的准确率,在目标和实例分割上也能一致地取得大幅度的提升。
目前Conformer只是在ImageNet1K数据集合上训练,其结合更大预训练数据(如ImageNet21K)集合以后将成为一种很有潜力的基网结构。
作者介绍
彭智亮、黄玮,中国科学院大学在读硕士生
顾善植,鹏城实验室工程师
王耀威,鹏城实验室研究员
谢凌曦,华为公司研究员
焦建彬、叶齐祥,中国科学院大学教授
参考资料:
https://arxiv.org/abs/2105.03889
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于CNN和Transformer相结合的模型的主要内容,如果未能解决你的问题,请参考以下文章