Greenplum 实时数据仓库实践(10)——集成机器学习库MADlib
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Greenplum 实时数据仓库实践(10)——集成机器学习库MADlib相关的知识,希望对你有一定的参考价值。
目录
MADlib是一个基于SQL的数据库内置的开源机器学习库,具有良好的并行度和可扩展性,有高度的预测精准度。MADlib最初由Pivotal公司与伯克利大学合作开发,提供了多种数据转换、数据探索、概率统计、数据挖掘和机器学习方法,使用它能够简易地对结构化数据进行分析和学习,以满足各行各业的应用需求。用户可以非常方便地将MADlib加载到数据库中,从而扩展数据库的分析功能。2015年7月MADlib成为Apache软件基金会的孵化器项目,经过两年的发展,于2017年8月毕业成为Apache顶级项目。最新的MADlib 1.18.0可以与PostgreSQL、Greenplum和HAWQ等数据库系统无缝集成。Greenplum MADlib扩展提供了在Greenplum数据库中进行机器学习和深度学习工作的能力。
本篇首先介绍MADlib的一些基本概念及其有别于其他机器学习工具包的特点。为了更好地使用MADlib,我们将简要说明它的设计思想、工作原理、执行流程和基础架构,还将罗列MADlib支持的模型和主要功能模块,然后说明MADlib软件包的安装与卸载。之后用矩阵分解函数实现推荐算法的示例,说明MADlib的具体用法。最后介绍MADlib的交叉验证模型评估功能。
10.1 MADlib基本概念
10.1.1 MADlib是什么
无论是经典的SAS、SPSS还是时下流行的MATLAB、R、Python,所有这些机器学习或数据挖掘软件都是自成系统的,具体来说就是具有一套完整的程序语言及其集成开发环境,提供了丰富的数学和统计分析函数,具备良好的人机交互界面,支持从数据准备、数据探索、数据预处理到开发和实现模型算法、数据可视化,再到最终结果的验证与模型部署及应用的全过程。它们都是面向程序员的系统或语言,重点在于由程序员自己利用系统提供的基本计算方法或函数,通过编程的方式实现应用需求。
MADlib具有与上述工具完全不同的设计理念,它不是面向程序员,而是面向数据库开发人员或DBA。如果要用一句话说明什么是MADlib,那就是“SQL中的大数据机器学习库”。通常SQL查询能发现数据最明显的模式和趋势,但要想获取数据中最为有用的信息,需要的其实是完全不同的一套技术,一套牢固扎根于数学和应用数学的技能(机器学习或深度学习),而具备这种技术的人才似乎只存在于学术界中。如果能将SQL的简单易用与数据挖掘的复杂算法结合起来,充分结合两者的优势和特点,对于广大传统数据库应用技术人员来说,就可将他们长期积累的数据库操作技能复用到机器学习领域,使转型更加轻松。现在,鱼和熊掌兼得的机会来了,DBA只要使用MADlib,就能用SQL查询实现简单的机器学习。
对用户而言,MADlib提供了可在SQL查询语句中调用的函数,即可以用select function()的方式来调用该库。这就意味着,所有的数据调用和计算都在数据库内完成而不需要数据的导入导出。MADlib不仅包括基本的线性代数运算和统计函数,还提供了常用的、现成的学习模型函数。用户不需要深入了解算法的程序实现细节,只要搞清楚各函数中相关参数的含义、提供正确的入参并能够理解和解释函数的输出结果即可。这种使用方式无疑会极大地提高开发效率,节约开发成本。在MADlib的世界里,一切皆函数,就是这么简单。
然而,任何事物都具有两面性,虽然MADlib提供了使用方便性、降低了学习和使用门槛,但是相对于其他机器学习系统而言,其灵活性与功能完备性显然是短板。首先,模型已经被封装在SQL函数中,性能优劣完全依赖于函数本身,基本没有留给用户进行性能调整的空间。其次,函数只能在SQL中调用,而SQL依赖于数据库系统。也就是说单独的MADlib函数库是毫无意义的,必须与PostgreSQL、Greenplum和HAWQ等数据库系统结合使用。最后,既然MADlib是SQL中的机器学习库,就注定它不关心数据可视化,本身不带数据的图形化表示功能。由此可见,MADlib作为工具,并不是传统意义上的机器学习系统软件,而只是一套可在SQL中调用的函数库,其出发点是让数据库技术人员用SQL快速完成简单的机器学习工作,比较适合做一些简单的、特征相对明显的机器学习。
即便如此,MADlib的易用性已经足以引起我们的兴趣。在了解了MADlib是什么及其优缺点后,用户就能根据自己的实际情况和需求有针对性地选择和使用MADlib来实现特定业务目标。
10.1.2 MADlib的设计思想
驱动MADlib架构的关键设计思想体现在以下方面:
- 操作数据库内的本地数据,避免在多个运行时环境之间不必要地移动数据。
- 充分利用数据库引擎功能,但将机器学习逻辑从数据库特定的实现细节中分离出来。
- 利用MPP无共享技术提供的并行性和可扩展性,如Greenplum或HAWQ数据库系统。
- 开放实施,保持与Apache社区的积极联系和持续的学术研究。
操作本地数据的思想与Hadoop是一致的。为了使全局的带宽消耗和I/O延迟降到尽可能小,在选择数据时,MADlib总是选择距离读请求最近的存储节点。如果在读请求所在节点的同一个主机上有需要的数据副本,那么MADlib会尽量选择它来满足读请求。如果数据库集群跨越多个数据中心,那么存储在本地数据中心的副本会优先于远程副本被选择。
MADlib库表现为数据库内置的函数。当函数在SQL语句中执行时,可以充分利用数据库引擎提供的功能。例如,在Greenplum中执行MADlib函数时,每个Segment在执行查询的时候会启动一个查询执行器,从而使Greenplum能够更好地利用所有可用资源。MADlib利用Greenplum或HAWQ数据库系统使用的MPP(Massively Parallel Processing,大规模并行处理)架构,使用户能够获益于经过锤炼的基于MPP的分析功能及其查询性能,兼顾了低延时与高扩展。
10.1.3 MADlib的工作原理
现以Greenplum上的MADlib为例解释它的工作原理。当一个客户端查询向Greenplum发出请求时,Master节点会对查询进行处理,根据查询成本、资源队列定义、数据局部化和当前系统中的资源使用情况,为查询规划资源分配。之后查询被分发到Segment节点所在的物理主机并行处理,可能是节点子集或整个集群。每个Segment节点监控查询对资源的实时使用情况,避免异常资源占用。查询处理完成后,最后的结果再通过Master返回客户端。
可以将MADlib作为扩展安装在Greenplum数据库系统中,通过定义UDA和UDF建立In-Database Functions,在结构化和非结构化数据上并行实现数学、统计、图形、机器学习和深度学习算法。当我们使用SQL调用MADlib时,MADlib会首先进行输入的有效性判断和数据的预处理,将处理后的查询传给Greenplum,之后所有的计算即等同于普通的查询处理请求在Greenplum内执行。图1-1显示了Greenplum MADlib数据分析架构。
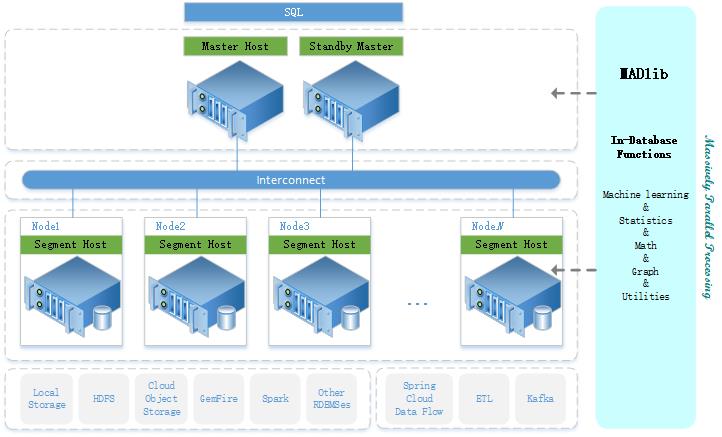
图1-1 Greenplum MADlib数据分析架构
MADlib基于SQL的算法在单个Greenplum数据库引擎中运行,无需在数据库和其他工具之间传输数据。MADlib不是一个单独的守护进程,也不是在数据库之外运行的独立软件,它是数据库的一个扩展模块,并且对Greenplum本身的架构没有任何更改,这非常易于DBA部署和管理。
10.1.4 MADlib的执行流程
图10-2为整个MADlib函数调用过程的执行流程。在客户端,我们可以使用Jupyter、Zeppelin、psql等工具连接数据库并调用MADlib Function。MADlib预处理后根据具体算法生成多个查询传入数据库服务器,之后数据库服务器执行查询并返回数据流,一般是一个或多个存放结果的表。

图10-2 MADlib执行流程
10.1.5 MADlib架构
MADlib架构如图1-3所示。
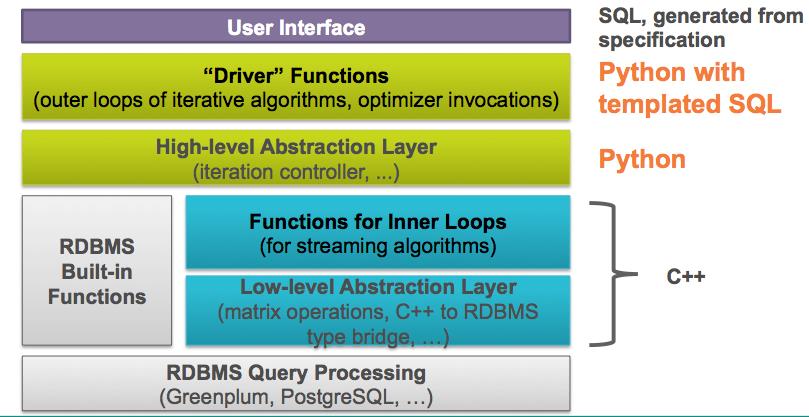
图10-3 MADlib架构
处于架构最上面一层的是用户接口。如前所述,用户只需通过在SQL查询语句中调用MADlib提供的函数来完成机器学习工作。当然这里的SQL语法要与特定数据库管理系统相匹配。最底层则是Greenplum、PostgreSQL、HAWQ等数据库管理系统,最终由它们处理查询请求。中间四层是构成MADlib的组件。从图1-3中可以看到,MADlib系统架构自上而下由四个主要组件构成。
- Python调用SQL模板实现的驱动函数:驱动函数是用户输入的主入口点,调用优化器执行迭代算法的外层循环。
- Python实现的高级抽象层:高级抽象层负责算法的流程控制。与驱动函数一起实现输入参数验证、SQL语句执行、结果评估,并可能在循环中自动执行更多的SQL语句直至达到某些收敛标准。
- C++实现的核心函数:这部分函数是由C++编写的核心函数,在内层循环中实现特定机器学习算法。出于性能考虑,这些函数使用C++而不是Python编写。
- C++实现的低级数据库抽象层:这些函数提供一个编程接口,对所有的PostgreSQL数据库内核实现细节进行抽象。它们提供了一种机制,使得MADlib能够支持不同的后端平台,从而使用户将关注点集中在内部功能而不是平台集成上。
10.2 MADlib的功能
10.2.1 MADlib支持的模型类型
MADlib支持以下常用机器学习模型类型,其中大部分模型都包含训练和预测两组函数。
1. 回归
如果所需的输出具有连续性,我们通常使用回归方法建立模型,预测输出值。例如,如果有真实的描述房地产属性的数据,我们就可以建立一个模型,预测基于房屋已知特征的售价。因为输出反应了连续的数值而不是分类,所以该场景是一个回归问题。
2. 分类
如果所需的输出实质上是分类的,就可以使用分类方法建立模型,预测新数据会属于哪一类。分类的目标是能够将输入记录标记为正确的类别。例如,假设有描述人口统计的数据,以及个人申请贷款和贷款违约历史数据,那么我们就能建立一个模型,描述新的人口统计数据集合贷款违约的可能性。此场景下输出的分类为“违约”和“正常”两类。
3. 关联规则
关联规则有时又叫作购物篮分析或频繁项集挖掘。相对于随机发生,确定哪些事项更经常一起发生,指出事项之间的潜在关系。例如,在一个网店应用中,关联规则挖掘可用于确定哪些商品倾向于被一起售出,然后将这些商品输入到客户推荐引擎中,提供促销机会,就像著名的啤酒与尿布的故事。
4. 聚类
识别数据分组,一组中的数据项比其他组的数据项更相似。例如,在客户细分分析中,目标是识别客户行为相似特征组,以便针对不同特征的客户设计各种营销活动,以达到市场目的。如果提前了解客户细分情况,这将是一个受控的分类任务。当我们让数据识别自身分组时,这就是一个聚类任务。
5. 主题建模
主题建模与聚类相似,也是确定彼此相似的数据组。这里的相似通常特指在文本领域中具有相同主题的文档。注意,MADlib的当前实现并不支持中文分词。
6. 描述性统计
描述性统计不提供模型,因此不被认为是一种机器学习方法,但是描述性统计有助于向分析人员提供信息以了解基础数据,为数据提供有价值的解释,可能会影响数据模型的选择。例如,计算数据集中每个变量内的数据分布有助于分析理解哪些变量应被视为分类变量、哪些变量是连续性变量以及值的分布情况。描述性统计通常是数据探索的组成部分。
7. 模型验证
不了解一个模型的准确性就开始使用它,很容易导致糟糕的结果,所以理解模型存在的问题,并用测试数据评估模型的精度尤为重要。需要将训练数据和测试数据分离,频繁进行数据分析,验证统计模型的有效性,评估模型不过分拟合训练数据。N-fold交叉验证方法经常被用于模型验证。
10.2.2 MADlib的主要功能模块
MADlib的主要功能模块如图10-4所示。
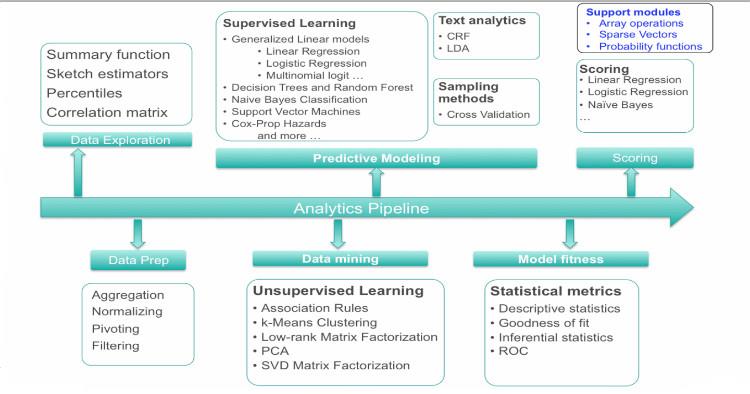
图10.4 MADlib主要功能模块
下面基于MADlib 1.10版本预览MADlib提供的具体模型算法或功能。
1. Data Types and Transformations(数据类型与转换)
(1)Arraysand Matrices(数组与矩阵)
. ArrayOperations(数组运算)
. MatrixOperations(矩阵运算)
. MatrixFactorization(矩阵分解)
. Low-rankMatrix Factorization(低阶矩阵分解)
. SingularValue Decomposition(SVD,奇异值分解)
. Normsand Distance functions(范数和距离函数)
. SparseVectors(稀疏向量)
(2)DimensionalityReduction(降维)
. PrincipalComponent Analysis(PCA主成分分析)
. PrincipalComponent Projection(PCP主成分投影)
(3)Pivot(透视表)
(4)EncodingCategorical Variables(分类变量编码)
(5)Stemming(词干提取)
2. Graph(图)
(1)SingleSource Shortest Path(单源最短路径)
3. Model Evaluation(模型评估)
(1)CrossValidation(交叉验证)
(2)PredictionMetrics(指标预测)
4. Statistics(统计)
(1)DescriptiveStatistics(描述性统计)
. Pearson’s Correlation(皮尔森相关系数)
. Summary(摘要汇总)
(2)InferentialStatistics(推断性统计)
. HypothesisTests(假设检验)
(3)ProbabilityFunctions(概率函数)
5. Supervised Learning(监督学习)
(1)ConditionalRandom Field(条件随机场)
(2)RegressionModels(回归模型)
. ClusteredVariance(聚类方差)
. Cox-ProportionalHazards Regression(Cox比率风险回归)
. ElasticNet Regularization(弹性网络回归)
. GeneralizedLinear Models(广义线性回归)
. LinearRegression(线性回归)
. LogisticRegression(逻辑回归)
. MarginalEffects(边际效应)
. MultinomialRegression(多分类逻辑回归)
. OrdinalRegression(有序回归)
. RobustVariance(鲁棒方差)
(3)SupportVector Machines(支持向量机)
(4)TreeMethods(树方法)
. DecisionTree(决策树)
. RandomForest(随机森林)
6. Time Series Analysis(时间序列分析)
(1)ARIMA(自回归积分滑动平均)
7. UnsupervisedLearning(无监督学习)
(1)AssociationRules(关联规则)
. AprioriAlgorithm(Apriori算法)
(2)Clustering(聚类)
. k-MeansClustering(k-Means)
(3)TopicModelling(主题模型)
. LatentDirichlet Allocation(LDA)
8. Utility Functions(应用函数)
(1)DeveloperDatabase Functions(开发者数据库函数)
(2)LinearSolvers(线性求解器)
. DenseLinear Systems(稠密线性系统)
. SparseLinear Systems(稀疏线性系统)
(3)PathFunctions(路径函数)
(4)PMMLExport(PMML导出)
(5)Sessionize(会话化)
(6)TextAnalysis(文本分析)
. TermFrequency(词频)
从Apache Madlib 1.16版开始,Greenplum数据库支持使用Keras和TensorFlow进行深度学习。可以在MADlib帮助页查看所支持的库和配置说明,以及使用Tensorflow后端查看Keras API的用户文档。注意RHEL 6不支持MADlib深度学习。MADlib支持带有TensorFlow后端的Keras,可以带有或不带图形处理单元(Graphics Processing Unit,GPU)。GPU可以显著加快深层神经网络的训练,因此它们通常用于企业级工作负载。
10.3 MADlib的安装与卸载
10.3.1 确定安装平台
MADlib 可以安装在PostgreSQL、Greenplum和HAWQ中。在不同的数据库系统,安装过程不尽相同。这里以在Greenplum 6.18中安装MADlib 1.18为例,演示MADlib的安装与卸载过程。机器学习需要数据库系统提供有效的存储、索引和查询处理支持。源于高性能并行计算的技术在处理海量数据集方面常常是重要的。分布式技术也能帮助处理海量数据,并且当数据不能集中到一起处理时更是至关重要。
比照以上机器学习对数据库系统提出的要求,我们不妨简单考量一下Greenplum。合理使用哈希或随机分布存储策略具有较好的数据本地化特性,优化器在制定查询计划时,内部实现已然利用了索引的思想。Greenplum基于成本的查询优化框架来增强其性能,所采用的MPP架构使用户能够获益于优异的查询性能,兼顾了低延时与高扩展。由此看来,在Greenplum上运行MADlib是实现大数据机器学习比较合理的选择。
在大多数传统数据库中,索引可以极大缩短数据访问时间,但在诸如Greenplum这样的分布式数据库中,应该更加谨慎地使用索引。Greenplum数据库执行非常快速的顺序扫描,索引使用随机搜索模式来定位磁盘上的记录。Greenplum数据分布在各个数据段中,因此每个数据段扫描整个数据的一小部分以获得结果。使用表分区,要扫描的总数据可能更小。由于分析型查询工作负载通常会返回非常大的数据集,因此使用索引效率可能并不高。在创建索引时需要考虑以下几点通用原则。
- 索引可以提高查询返回单个记录或非常小的数据集(如OLTP)的工作场景的性能。
- 对于返回目标行集的查询,索引可以提高压缩AO表的性能。对于压缩数据,索引访问方法意味着只解压缩必要的行。
- 避免在频繁更新的列上使用索引。在经常更新的列上创建索引会增加更新该列时所需的写入次数。
- 创建具有选择性的B树索引。索引选择性是列的不同值数除以表中的行数的比率。例如,如果一个表有1000行,一个列有800个不同的值,则索引的选择性为0.8,这被认为是好的。唯一索引的选择性比始终为1.0,显然这是最好的。Greenplum数据库只允许在分布键列上使用唯一索引。
- 对低选择性列使用位图索引。
- 用于频繁联接的列(例如外键列)上的索引可以通过允许查询优化器使用更多联接方法来提高性能。
- WHERE子句中经常引用的列是索引候选列。
- 避免索引重叠,具有相同前导列的索引是冗余的。
- 对于大量数据加载到表中,考虑删除索引并在加载完成后重新创建它们,这通常比更新索引快。
- 聚簇索引对磁盘上的记录进行物理排序。例如,日期列上的聚集索引,其中数据按日期顺序排列。对特定日期范围的查询会导致从磁盘进行有序提取,从而利用快速顺序访问。
10.3.2 安装MADlib
根据所Greenplum使用的操作系统平台,从https://madlib.apache.org/download.html选择下载MADlib安装包。我们下载的安装文件是apache-madlib-1.18.0-bin-Linux-CentOS7.rpm。需要在Greenplum集群中的所有主机上,使用root用户执行以下命令安装RPM包:
rpm -ivh apache-madlib-1.18.0-bin-Linux-CentOS7.rpm这步将在所有节点(Master和Segment)上创建MADlib的安装目录和文件,默认目录为/usr/local/madlib/。然后在指定数据库中部署MADlib,使用gpadmin用户在Greenplum的Master主机上执行以下命令:
cd /usr/local/madlib/Versions/1.18.0/bin/
./madpack install -c /dm -s madlib -p greenplum该命令在dm数据库中建立madlib schema,-p参数指定平台为Greenplum。命令执行后可以查看在madlib schema中创建的数据库对象。
[gpadmin@vvml-z2-greenplum~]$psql -d dm
Timing is on.
Pager usage is off.
psql (9.4.24)
Type "help" for help.
dm=# set search_path=madlib;
SET
dm=# \\d
List of relations
Schema | Name | Type | Owner | Storage
--------+-------------------------+----------+---------+---------
madlib | migrationhistory | table | gpadmin | heap
madlib | migrationhistory_id_seq | sequence | gpadmin | heap
(2 rows)
dm=# select type,count(*)
dm-# from (select p.proname as name,
dm(# case when p.proisagg then 'agg'
dm(# when p.prorettype
dm(# = 'pg_catalog.trigger'::pg_catalog.regtype
dm(# then 'trigger'
dm(# else 'normal'
dm(# end as type
dm(# from pg_catalog.pg_proc p, pg_catalog.pg_namespace n
dm(# where n.oid = p.pronamespace and n.nspname='madlib') t
dm-# group by rollup (type);
type | count
--------+-------
| 1719
agg | 143
normal | 1576
(3 rows)从查询结果可以看到,MADlib部署应用程序madpack首先创建数据库模式madlib,然后在该模式中创建数据库对象,包括一个表、一个序列、1576个普通函数、143个聚合函数。所有机器学习的模型、算法、操作和功能都是通过调用这些函数实际执行的。
最后使用gpadmin用户在Greenplum的Master主机上执行下面的命令验证安装:
/usr/local/madlib/Versions/1.18.0/bin/madpack install-check -c /dm -s madlib -p greenplum该命令通过执行28个模块的60个案例验证所有模块都能正常工作。命令输出如下,如果看到所有案例都已经正常执行,就说明MADlib安装成功。
[gpadmin@vvml-z2-greenplum~]$cd /usr/local/madlib/Versions/1.18.0/bin/
[gpadmin@vvml-z2-greenplum/usr/local/madlib/Versions/1.18.0/bin]$./madpack install-check -c /dm -s madlib -p greenplum
madpack.py: INFO : Detected Greenplum DB version 6.18.0.
TEST CASE RESULT|Module: array_ops|array_ops.ic.sql_in|PASS|Time: 330 milliseconds
TEST CASE RESULT|Module: bayes|bayes.ic.sql_in|PASS|Time: 1167 milliseconds
TEST CASE RESULT|Module: crf|crf_test_small.ic.sql_in|PASS|Time: 970 milliseconds
...
TEST CASE RESULT|Module: pca|pca_project.ic.sql_in|PASS|Time: 2021 milliseconds
TEST CASE RESULT|Module: validation|cross_validation.ic.sql_in|PASS|Time: 850 milliseconds
[gpadmin@vvml-z2-greenplum/usr/local/madlib/Versions/1.18.0/bin]$10.3.3 卸载MADlib
卸载过程就是删除madlib模式,可以使用madpack程序或SQL命令完成。
- 使用madpack部署应用程序删除模式。
/usr/local/madlib/Versions/1.18.0/bin/madpack uninstall -c /dm-s madlib -p greenplum- 使用SQL命令手工删除模式。
\\c dm;
drop schema madlib cascade;如果模型验证过程中途出错,那么数据库中可能包含测试的模式(模式名称前缀都是madlib_installcheck_)或测试用户,只能手工执行SQL命令删除。
-- 删除可能存在的遗留测试模式,例如:
drop schema madlib_installcheck_kmeanscascade;
-- 删除可能存在的遗留测试用户,例如:
drop user if existsmadlib_1100_installcheck; 10.4 MADlib示例——使用矩阵分解实现用户推荐
本节说明如何用MADlib的矩阵分解函数实现推荐算法。矩阵分解(Matrix Factorization)简单说就是将原始矩阵拆解为数个矩阵的乘积。在一些大型矩阵计算中,其计算量大,化简繁杂,使得计算非常复杂。如果运用矩阵分解,将大型矩阵分解成简单矩阵的乘积形式,就可大大降低计算的难度以及计算量。这就是矩阵分解的主要目的。而且矩阵的秩的问题、奇异性问题、特征值问题、行列式问题等都可以通过矩阵分解后清晰地反映出来。另一方面,对于那些大型的数值计算问题,矩阵的分解方式以及分解过程也可以作为计算的理论依据。MADlib提供了低秩矩阵分解和奇异值分解两种矩阵分解方法。
10.4.1 低秩矩阵分解
1. 背景知识
矩阵中的最大不相关向量的个数叫作矩阵的秩,可通俗理解为数据有秩序的程度。秩可以度量相关性,而向量的相关性实际上又带有矩阵的结构信息。如果矩阵之间各行的相关性很强,就表示这个矩阵实际可以投影到更低维度的线性子空间,也就是用几个特征就可以完全表达了,它就是低秩的。所以我们可以总结的一点是:如果矩阵表达的是结构性信息,例如图像、用户推荐表等,那么这个矩阵各行之间存在着一定的相关性,这个矩阵一般就是低秩的。
如果A是一个m行n列的数值矩阵、rank(A)是A的秩,并且rank(A)远小于m和n,就称A是低秩矩阵。低秩矩阵每行或每列都可以用其他的行或列线性表示,可见它包含大量的冗余信息。利用这种冗余信息,可以对缺失数据进行恢复,也可以对数据进行特征提取。
MADlib的lmf模块可用两个低秩矩阵的乘积逼近一个稀疏矩阵,逼近的目标就是让预测矩阵和原来矩阵之间的均方根误差(Root Mean Squared Error,RMSE)最小,从而实现所谓“潜在因子模型”。lmf模块提供的低秩矩阵分解函数就是为任意稀疏矩阵A找到两个矩阵U和V,使得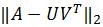 的值最小化,其中
的值最小化,其中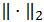 代表Frobenius范数。换句话说,只要求得U和V,就可以用它们的乘积来近似模拟A。因此低秩矩阵分解有时也叫UV分解。假设A是一个m×n的矩阵,则U和V分别是m×r和n×r的矩阵,并且1≤r≤min(m,n)。
代表Frobenius范数。换句话说,只要求得U和V,就可以用它们的乘积来近似模拟A。因此低秩矩阵分解有时也叫UV分解。假设A是一个m×n的矩阵,则U和V分别是m×r和n×r的矩阵,并且1≤r≤min(m,n)。
2. MADlib低秩矩阵分解函数
MADlib的lmf_igd_run函数能够实现低秩矩阵分解功能。
(1)lmf_igd_run函数语法
lmf_igd_run( rel_output,
rel_source,
col_row,
col_column,
col_value,
row_dim,
column_dim,
max_rank,
stepsize,
scale_factor,
num_iterations,
tolerance )(2)参数说明
lmf_igd_run函数参数说明如表10-1所示。
| 参数名称 | 数据类型 | 描述 |
| rel_output | TEXT | 输出表名。输出的矩阵U和V以二维数组类型存储。 RESULT AS ( matrix_u DOUBLE PRECISION[], matrix_v DOUBLE PRECISION[], rmse DOUBLE PRECISION) 行i对应的向量是matrix_u[i:i][1:r],列j对应的向量是matrix_v[j:j][1:r] |
| rel_source | TEXT | 输入表名。输入矩阵的格式如下: TABLE|VIEW input_table ( row INTEGER, col INTEGER, value DOUBLE PRECISION) 输入包含一个描述矩阵的表,数据被指定为(row、column、value)。输入矩阵的行列值大于等于1,并且不能有NULL值 |
| col_row | TEXT | 包含行号的列名 |
| col_column | TEXT | 包含列号的列名 |
| col_value | FLOAT8 | (row, col)位置对应的值 |
| row_dim(可选) | INTEGER | 指示矩阵中的行数,默认为:“SELECT max(col_row) FROM rel_source” |
| column_dim(可选) | INTEGER | 指示矩阵中的列数,默认为:“SELECT max(col_col) FROM rel_source” |
| max_rank | INTEGER | 期望逼近的秩数 |
| stepsize(可选) | FLOAT8 | 默认值为0.01。超参数,决定梯度下降法的步长 |
| scale_factor(可选) | FLOAT8 | 默认值为0.1。超参数,决定初始缩放因子 |
| num_iterations(可选) | INTEGER | 默认值为10。不考虑收敛情况下的最大迭代次数 |
| tolerance(可选) | FLOAT8 | 默认值为0.0001,收敛误差,小于该误差时停止迭代 |
表10-1 lmf_igd_run函数参数说明
矩阵分解一般不用数学上直接分解的办法,尽管直接分解出来的精度很高,但是效率实在太低!矩阵分解往往会转化为一个优化问题,通过迭代求局部最优解。但有一个问题是,通常原矩阵的稀疏度很大,分解很容易产生过拟合(overfitting),简单说就是为了迁就一些偏值导致整个模型错误的问题。所以现在的方法是在目标函数中增加一项正则化(regularization)参数来避免过拟合问题。因此,一般的矩阵分解的目标函数(也称损失函数,loss function)为:

前一项是预测后矩阵和原矩阵的误差,这里计算只针对原矩阵中的非空项。后一项就是正则化因子,用来解决过拟合问题。这个优化问题求解的就是分解之后的U、V矩阵的潜在因子向量。madlib.lmf_igd_run函数使用随机梯度下降法(stochastic gradient descent)求解这个优化问题,迭代公式为:
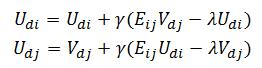
其中,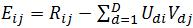 。
。
γ是学习速率,对应stepsize参数;λ是正则化系数,对应scale_factor参数。γ和λ这是两个超参数,对于最终结果影响极大。在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,以提高学习的性能和效果。γ的大小不仅会影响到执行时间,还会影响到结果的收敛性。γ太大的话会导致结果发散,一般都会把γ取得很小,不同的数据集取的值不同,但大概是0.001这个量级。这样的话训练时间会长一些,但结果会比较好。λ的值一般也比较小,大概取0.01这个量级。
迭代开始前,需要对U、V的特征向量赋初值。这个初值很重要,会严重地影响到计算速度。一般的做法是在均值附近产生随机数作为初值。也正是由于这个原因,从数据库层面看,madlib.lmf_igd_run函数是一个非确定函数,也就是说,同样一组输入数据,多次执行函数生成的结果数据是不同的。迭代结束的条件一般是损失函数的值小于某一个阈值(由tolerance参数指定)或者到达指定的最大迭代次数(由num_iterations参数指定)。
3. 低秩矩阵分解函数示例
我们将通过一个简单示例说明如何利用madlib.lmf_igd_run函数实现潜在因子(Latent Factor)推荐算法。该算法的思想是:每个用户(user)都有自己的偏好,比如一个歌曲推荐应用中,用户A喜欢带有“小清新的”“吉他伴奏的”“王菲”等元素,如果一首歌(item)带有这些元素,就将这首歌推荐给该用户,也就是用元素去连接用户和歌曲。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。
(1)潜在因子矩阵
我们希望能找到这样两个矩阵:
- 潜在因子-用户矩阵Q,表示不同的用户对于不同元素的偏好程度,1代表很喜欢,0代表不喜欢,如图10-5所示。
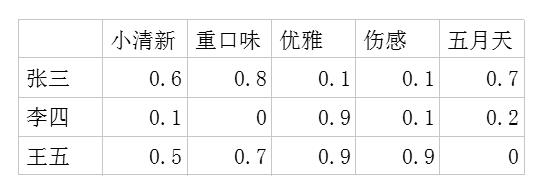
图10-5 潜在因子-用户矩阵
- 潜在因子-音乐矩阵P,表示每首歌曲含有各种元素的成分。比如图10-6中,音乐A是一个偏小清新的音乐,含有“小清新”这个潜在因子的成分是0.9、“重口味”的成分是0.1、“优雅”的成分是0.2等。
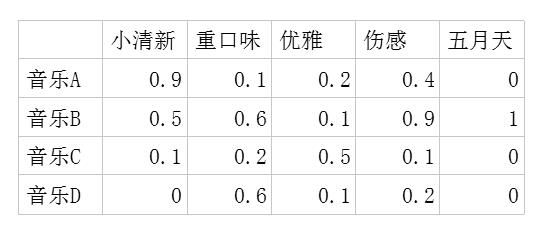
图10-6 潜在因子-音乐矩阵
利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好*音乐A含有小清新的成分+对重口味的偏好*音乐A含有重口味的成分+对优雅的偏好*音乐A含有优雅的成分+……即0.6*0.9+0.8*0.1+0.1*0.2+0.1*0.4+0.7*0=0.68。
对每个用户每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵 ,如图10-7所示。注意,这里的波浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分矩阵。
,如图10-7所示。注意,这里的波浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分矩阵。
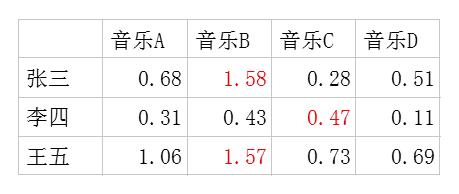
图10-7 估计的评分矩阵
因此我们对张三推荐四首歌中得分最高的B、对李四推荐得分最高的C,对王五推荐B。如果用矩阵表示即为:
(2)如何得到潜在因子
潜在因子是怎么得到的呢?面对大量用户和歌曲,让用户自己给歌曲分类并告诉我们其偏好系数显然是不现实的,事实上我们能获得的只有用户行为数据。假定使用以下量化标准:单曲循环=5,分享=4,收藏=3,主动播放=2,听完=1,跳过=-2,拉黑=-5,则在分析时能获得的实际评分矩阵R(也就是输入矩阵)如图10-8所示。
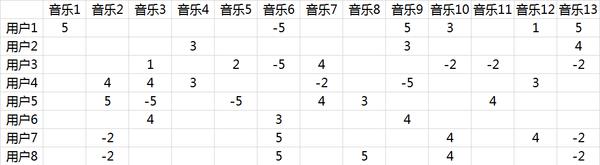
图10-8 实际评分矩阵
推荐系统的目标就是预测出空白对应位置的分值。推荐系统基于这样一个假设:用户对项目的打分越高,表明用户越喜欢。因此,预测出用户对未评分项目的评分后,根据分值大小排序,把分值高的项目推荐给用户。这是一个非常稀疏的矩阵,因为大部分用户只听过全部歌曲中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的就是矩阵的UV分解,如图10-9所示。
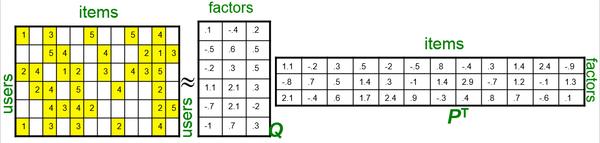
图10-9 矩阵的UV分解
矩阵分解的想法来自于矩阵补全,即依据一个矩阵给定的部分数据把缺失的值补全。一般假设原始矩阵是低秩的,我们可以从给定的值来还原这个矩阵。由于直接求解低秩矩阵从算法以及参数的复杂度来说效率很低,因此常用的方法是直接把原始矩阵分解成两个子矩阵相乘。例如,将图10-9所示的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵和实际的评分矩阵不要相差太多,也就是求解矩阵分解的目标函数:
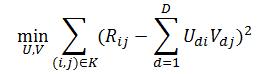
如前所述,实际应用中,往往还要加上2范数的罚项,然后利用梯度下降法就可以求得P和Q两个矩阵的估计值。例如,我们上面给出的那个例子可以分解成两个矩阵,如图10-10所示。
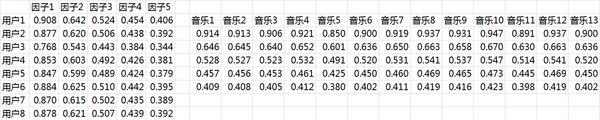
图10-10 分解后得到的UV矩阵
这两个矩阵相乘就可以得到估计的得分矩阵,如图10-11所示。
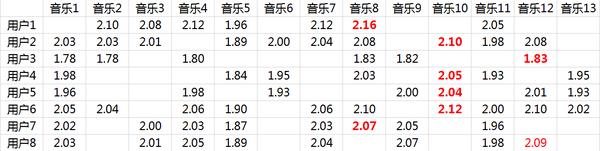
图10-11 预测矩阵
将用户已经听过的音乐剔除后,选择分数最高的音乐推荐给用户即可。这个例子里用户7和用户8有较强的相似性,如图10-12所示。

图10-12 评分相似的用户
从推荐的结果来看,正好推荐的是对方评分较高的音乐,如图10-13所示。

图10-13 对相似用户的推荐
该算法假定我们要恢复的矩阵是低秩的,实际上这种假设是十分合理的,比如一个用户对某歌曲的评分是其他用户对这首歌曲评分的线性组合。所以,通过低秩重构就可以预测用户对其未评价过的音乐的喜好程度,从而对矩阵进行填充。
(3)利用madlib.lmf_igd_run函数实现
① 建立输入表并生成输入数据
-- 创建用户索引表
drop table if exists tbl_idx_user;
create table tbl_idx_user (user_idx bigserial, userid varchar(10));
-- 创建音乐索引表
drop table if exists tbl_idx_music;
create table tbl_idx_music (music_idx bigserial, musicid varchar(10));
-- 创建用户行为表
drop table if exists lmf_data;
create table lmf_data (
row int,
col int,
val float8
);
-- 生成输入表数据
-- 用户表
insert into tbl_idx_user (userid)
values ('u1'),('u2'),('u3'),('u4'),('u5'),('u6'),('u7'),('u8'),('u9'),('u10');
-- 音乐表
insert into tbl_idx_music (musicid)
values ('m1'),('m2'),('m3'),('m4'),('m5'),('m6'),('m7'),('m8'),('m9'),('m10'),('m11'),('m12'),('m13'),('m14'),('m15');
-- 用户行为表
insert into lmf_data values (1, 1, 5), (1, 6, -5), (1, 9, 5), (1, 11, 3), (1, 12, 1), (1, 13, 5);
insert into lmf_data values (2, 4, 3), (2, 9, 3), (2, 13, 4);
insert into lmf_data values (3, 3, 1), (3, 5, 2), (3, 6, -5), (3, 7, 4), (3, 11, -2), (3, 12, -2), (3, 13, -2);
insert into lmf_data values (4, 2, 4), (4, 3, 4), (4, 4, 3), (4, 7, -2), (4, 9, -5), (4, 12, 3);
insert into lmf_data values (6, 2, 5), (6, 3, -5), (6, 5, -5), (6, 7, 4), (6, 8, 3), (6, 11, 4);
insert into lmf_data values (7, 3, 4), (7, 6, 3), (7, 9, 4);
insert into lmf_data values (8, 2, -2), (8, 6, 5), (8, 11, 4), (8, 12, 4), (8, 13, -2);
insert into lmf_data values (9, 2, -2), (9, 6, 5), (9, 8, 5), (9, 11, 4), (9, 13, -2); 说明:
- 从前面的解释可以看到,推荐矩阵的行列下标分别表示用户和歌曲。然而在业务系统中,userid和musicid很可能不是按从1到N的规则顺序生成的,因此通常需要建立矩阵下标值与业务表ID之间的映射关系,这里使用Greenplum的BIGSERIAL自增数据类型对应推荐矩阵的索引下标。
- 在生成原始数据时对图10-8的例子做了适当的修改。用户表中u5和u10用户没有给任何歌曲打分,而音乐表中的m10、m14、m15无评分。我们希望看到的结果是,除了与打分行为相关的用户和歌曲以外,也能为u5、u10推荐歌曲,并可能将m10、m14、m15推荐给用户。
② 调用lmf_igd_run函数分解矩阵
-- 执行低秩矩阵分解
drop table if exists lmf_model;
select madlib.lmf_igd_run('lmf_model','lmf_data','row','col','val',11,16,7,0.1,1,10,1e-9);说明:
- 最大行列数可以大于实际行列数,如这里传入的参数是11和16,而实际的用户数与歌曲数是10和15。
- max_rank参数为最大秩数,要小于min(row_dim, column_dim),否则函数会报错。
- 最大秩数实际可以理解为最大的潜在因子数,也就是例子中的最大量化指标个数。本例中共有7个指标,因此max_rank参数传7。
- stepsize和scale_factor参数对于结果的影响巨大,而且不同的学习数据,参数值也不同。也就是说超参数的值是与输入数据相关的。在本例中,使用默认值时RMSE很大。经过反复测试,对于测试矩阵,stepsize和scale_factor分别为0.1和1时误差相对较小。
函数执行结果的控制台输出如下:
NOTICE: Matrix lmf_data to be factorized: 11 x 16
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CONTEXT: SQL statement "
CREATE TABLE lmf_model (
id SERIAL,
matrix_u DOUBLE PRECISION[],
matrix_v DOUBLE PRECISION[],
rmse DOUBLE PRECISION)"
PL/pgSQL function madlib.lmf_igd_run(character varying,regclass,character varying,character varying,character varying,integer,integer,integer,double precision,double precision,integer,double precision) line 47 at EXECUTE statement
NOTICE:
Finished low-rank matrix factorization using incremental gradient
* table : lmf_data (row, col, val)
Results:
* RMSE = 0.00306079672351231
Output:
* view : SELECT * FROM lmf_model WHERE id = 1
lmf_igd_run
-------------
1
(1 row)可以看到,均方根误差值为0.003。
③ 检查结果
从上一步的输出看到,lmf_igd_run()函数返回的模型ID是1,需要用它作为查询条件。
dm=# select array_dims(matrix_u) as u_dims, array_dims(matrix_v) as v_dims
dm-# from lmf_model
dm-# where id = 1;
u_dims | v_dims
-------------+-------------
[1:11][1:7] | [1:16][1:7]
(1 row)结果表中包含分解成的两个矩阵,U(用户潜在因子)矩阵11行7列,V(音乐潜在因子)矩阵16行7列。
④ 查询结果值
select matrix_u, matrix_v from lmf_model where id = 1;⑤ 矩阵相乘生成推荐矩阵
MADlib的矩阵相乘函数是matrix_mult,支持稠密和稀疏两种矩阵表示。稠密矩阵需要指定矩阵对应的表名、row和val列,稀疏矩阵需要指定矩阵对应的表名、row、col和val列。现在要将lmf_igd_run函数输出的矩阵装载到表中再执行矩阵乘法。这里使用稀疏形式,只要将二维矩阵的行、列、值插入表中即可。
-- 建立用户稀疏矩阵表
drop table if exists mat_a_sparse;
create table mat_a_sparse as
select d1,d2,matrix_u[d1][d2] val from
(select matrix_u,
generate_series(1,array_upper(matrix_u,1)) d1,
generate_series(1,array_upper(matrix_u,2)) d2
from lmf_model) t;
-- 建立音乐稀疏矩阵表
drop table if exists mat_b_sparse;
create table mat_b_sparse as
select d1,d2,matrix_v[d1][d2] val from
(select matrix_v,
generate_series(1,array_upper(matrix_v,1)) d1,
generate_series(1,array_upper(matrix_v,2)) d2
from lmf_model) t;
-- 执行矩阵相乘,‘trans=true’表示在相乘前该矩阵先进行转置
drop table if exists matrix_r;
select madlib.matrix_mult('mat_a_sparse', 'row=d1, col=d2, val=val',
'mat_b_sparse', 'row=d1, col=d2, val=val, trans=true',
'matrix_r');这两个矩阵(11×3与16×3)相乘生成的结果表是稠密形式的11×16矩阵,这就是我们需要的推荐矩阵。为了方便与原始的索引表关联,将结果表转为稀疏表示。
drop table if exists matrix_r_sparse;
select madlib.matrix_sparsify('matrix_r', 'row=d1, val=val','matrix_r_sparse', 'col=d2, val=val');最后与原始的索引表关联,过滤掉用户已经听过的歌曲,选择分数最高的歌曲推荐,查询及结果如下。
dm=# select t2.userid,t3.musicid,t1.val
dm-# from(select d1,d2,val,row_number() over (partition by d1 order by val desc)rn
dm(# from matrix_r_sparse t1
dm(# where not exists (select 1 from lmf_data t2 where t1.d1 = t2.row and t1.d2 = t2.col)) t1,
dm-# tbl_idx_user t2, tbl_idx_music t3
dm-# where t1.rn = 1 and t2.user_idx= t1.d1 and t3.music_idx = t1.d2
dm-# order by t2.user_idx;
userid | musicid | val
--------+---------+------------------
u1 | m15 | 4.03328652517244
u2 | m1 | 4.16214403151415
u3 | m9 | 2.36711722989761
u4 | m6 | 1.76862041255969
u5 | m8 | 3.30908255211719
u6 | m13 | 2.97494828060688
u7 | m8 | 6.88309154103752
u8 | m8 | 4.2685770106513
u9 | m12 | 3.72973048036454
u10 | m2 | 2.60372648966083
(10 rows)这就是为每个用户推荐的歌曲。可以看到,为用户u5和u10分别推荐了歌曲m8和m2,m15推荐给了用户u1。MADlib的低秩矩阵分解函数可以作为推荐类应用的算法实现。从函数调用角度看,madlib.lmf_igd_run函数是一个非确定函数,也就是说,同样一组输入数据,函数生成的结果数据却不同(对于同样的输入数据,每次的推荐可能不一样)。在海量数据的应用中,推荐可能需要计算的是一个“几亿”ד几亿”的大型矩阵,如何保证推荐系统的性能将成为巨大的挑战。
10.4.2 奇异值分解
1. 背景知识
低秩矩阵分解是用两个矩阵的乘积近似还原一个低秩矩阵。MADlib还提供了另一种矩阵分解方法,即奇异值分解。奇异值分解简称SVD(Singular Value Decomposition),可以理解为将一个比较复杂的矩阵用更小更简单的三个子矩阵的相乘来表示,这三个小矩阵描述了原矩阵重要的特性。
要理解奇异值分解,先要知道什么是特征值和特征向量。m×n矩阵M的特征值和特征向量分别是标量值λ和向量u,它们是如下方程的解:
Mu=λu
换言之,特征向量(eigenvector)是被M乘时除量值外并不改变的向量。特征值(eigenvalue)是缩放因子。该方程也可以写成(M-λE)u=0,其中E是单位矩阵。
对于方阵,可以使用特征值和特征向量分解矩阵。假设M是n×n矩阵,具有n个独立
以上是关于Greenplum 实时数据仓库实践(10)——集成机器学习库MADlib的主要内容,如果未能解决你的问题,请参考以下文章
Greenplum 实时数据仓库实践——Greenplum与数据仓库