Greenplum 实时数据仓库实践——Greenplum与数据仓库
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Greenplum 实时数据仓库实践——Greenplum与数据仓库相关的知识,希望对你有一定的参考价值。
目录
3.4.1 Greenplum还是SQL-on-Hadoop
Greenplum是一个分布式大规模并行处理数据库,在大多数情况下适合做大数据的存储引擎、计算引擎和分析引擎,尤其适合构建数据仓库。本篇重点介绍Greenplum的系统架构和主要功能。我们先从历史演进和所采用的MPP框架对Greenplum做一个概要说明,然后描述其顶层架构,之后详细介绍存储模式、事务支持、并行查询与数据装载、容错与故障转移、数据库统计、过程化语言扩展等方面的功能特性,正是它们支撑Greenplum成为一款理想的分析型数据库产品。本篇最后简单对比Greenplum与另一个流行的大数据处理框架Hadoop,进而阐述可以选择前者的理由。
希望读者通过阅读本篇的内容,对Greenplum的概念有一个基本的认识,最重要的是理解为什么要使用它建立数据仓库。
3.1 Greenplum简介
Greenplum是一个大规模并行SQL分析引擎,针对的是分析型应用。与其它关系型数据库类似,接收SQL,返回结果集。
3.1.1 历史与现状
Greenplum最早出现在2002年,比大名鼎鼎的Hadoop(约2004年前后面世)还要早一些。当时正值互联网行业经过近10年的由慢到快的发展,累积了大量数据。传统主机的向上扩展(Scale-up)模式在海量数据面前遇到了瓶颈,除造价昂贵外,在技术上也难于满足数据计算的性能需求。这种情况下急需一种新的计算方式处理数据,于是分布式存储和分布式计算理论被提出来,Google公司著名的GFS和MapReduce也从此引起业界的关注,可以支持向外扩展(Scale-out)的分布式并行数据计算技术登场了。Greenplum正是在这一背景下产生,它借助于分布式计算思想,在流行的开源数据库PostgreSQL之上开发,实现了基于数据库的分布式数据存储和并行计算。
Greenplum的名字据说源自创始人家门口的一棵青梅。初创公司召集了十几位业界大咖花了一年多的时间完成最初的版本设计和开发,用软件实现了在开放X86平台上的分布式并行计算,不依赖于任何专有硬件,达到的性能却远远超过传统高昂的专有系统。2006年,当时的Sun微系统公司与Greenplum开始联手打造即时数据仓库。2010年EMC收购了Greenplum,2012年EMC、VMWare和Greenplum又联手建新公司Pivotal,之后由Pivotal公司商业运营。
Greenplum于2015年10月开源,社区具有很高的知名度和热度,至今依然保持着几周发版的更新速度。在2020年Pivotal被兄弟公司VMWare收购,由VMWare继续运营商业产品,形成了商业VMware Tanzu Greenplum和开源Greenplum两条产品线。商业产品提供了比开源产品更多的功能,如与EMC DD Boost、Symantec NetBackup的整合,QuickLZ压缩算法,替代过时gpcheck的gpsupport实用程序等。
3.1.2 MPP——一切皆并行
Greenplum采用无共享(Shared-Nothing)的大规模并行处理架构(Massively Parallel Processing ,MPP),将实际的数据存储设备分成一个个段服务器上的小存储单元,每个单元都有一个连接本地磁盘的专用独立的、高带宽通道。段服务器可以通过完全并行的方式处理每个查询,同时使用所有磁盘连接,并按照查询计划的要求在各段间实现高效数据流动。Greenplum基于这种架构可以帮助客户创建数据仓库(Greenplum从开始设计的时候就被定义成数据仓库),充分利用低成本的商用服务器、存储和联网设备,通过经济的方式进行PB级数据运算,并且在处理OLAP、BI和数据挖掘等任务时性能远超通用数据库系统。
并行工作方式贯穿了Greenplum功能设计的方方面面:外部表数据装载是并行的,查询计划执行是并行的,索引的建立和使用是并行的,统计信息收集是并行的,表关联(包括其中的重分布或广播及关联计算)是并行的,排序和分组聚合都是并行的,备份恢复也是并行的,甚而数据库启停和元数据检查等维护工具也按照并行方式来设计。得益于这种无所不在的并行,Greenplum在数据装载和数据计算中表现出强悍的性能。
Greenplum建立在无共享架构上,让每一颗CPU和每一块磁盘I/O都运转起来,无共享架构将这种并行处理发挥到极致。试想一台内置16块SAS盘的X86服务器,磁盘扫描性能约在2000MB/s左右,20台这样的服务器构成的集群I/O性能是40GB/s,这样超大的I/O吞吐量是传统存储难以达到的。另外,Greenplum还是建立在PostgreSQL数据库实例级别上并行计算,可在一次SQL请求中利用到每个节点上多个CPU核的计算能力,对X86的CPU超线程有很好的支持,提供更好的请求响应速度。
3.2 Greenplum系统架构
Greenplum是一个纯软件的MPP数据库服务器,其体系结构专门用于管理大规模分析型数据仓库或商业智能工作负载。
技术上讲,MPP(也称为无共享体系结构)是指具有多个节点的系统,每个节点都有自己的内存、操作系统和磁盘,它们协作执行一项操作。Greenplum使用这种高性能系统架构分配PB级别的数据,并行使用系统的所有资源来处理查询。
Greenplum 6版本基于PostgreSQL 9.4开源数据库,本质上是若干面向磁盘的PostgreSQL数据库实例,共同作为一个内聚的数据库管理系统(database management system,DBMS)。大多数情况下,在SQL支持、功能、配置选项和最终用户功能方面与PostgreSQL非常相似。用户操作Greenplum数据库就像与常规PostgreSQL交互一样。
Greenplum与PostgreSQL的主要区别为:
- 除了支持Postgres优化器外,还有自己的GPORCA优化器。
- Greenplum数据库可以使用Append-Optimized存储格式。
- Greenplum支持列存储,即逻辑上组织为表的数据,物理上以面向列的格式存储的行和列。列存储只能与Append-Optimized表一起使用。
Greenplum对PostgreSQL的内部结构进行了修改或补充,以支持数据库的并行结构。例如,系统目录、优化器、查询执行器和事务管理器组件做过修改和增强,能够在所有并行PostgreSQL数据库实例上同时运行查询。Greenplum依赖Interconnect内部互连在网络层支持不同PostgreSQL实例之间的通信,使得系统作为一个逻辑数据库运行。
较之标准PostgreSQL,Greenplum还增加了并行数据装载(外部表)、资源管理、查询优化和存储增强功能。反之Greenplum开发的许多功能和优化也进入了PostgreSQL社区,促进了PostgreSQL的发展。例如,表分区是Greenplum首先开发的一个特性,现在已成为标准PostgreSQL的一部分。
Greenplum顶层系统架构如图3-1所示。Master是Greenplum数据库系统的入口,是客户端连接并提交SQL语句的数据库实例。Master将其工作与系统中其它叫做Segment的数据库实例进行协调,这些数据库实例负责实际存储和处理用户数据。
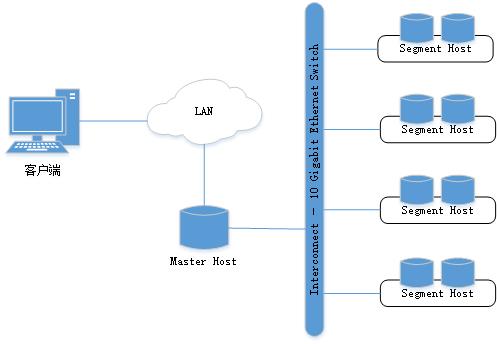
图3-1。Greenplum顶层系统架构
3.2.1 Master
Master是Greenplum的系统入口,它接收客户端连接和SQL查询,并将工作分配给Segment实例。最终用户通过Master与Greenplum数据库交互,就像与典型PostgreSQL数据库交互一样。用户使用诸如psql之类的客户端程序或JDBC、ODBC或libpq(PostgreSQL C API)之类的应用程序编程接口(application programming interface,API)连接到数据库。
Master数据库实例中存储全局系统目录(global system catalog)。全局系统目录是一组系统表,其中包含关于Greenplum本身的元数据。Master实例中不包含任何用户数据,用户数据仅驻留在Segment实例中。Master验证客户端连接,处理传入的SQL命令,在Segment之间分配工作负载,协调每个Segment返回的结果,并将最终结果显示给客户端程序。
Greenplum数据库使用写前日志(Write-Ahead Logging,WAL)进行主/备用Master镜像。在基于WAL的日志记录中,所有修改都会在应用之前写入日志,以确保任何进程内操作的数据完整性。
3.2.2 Segment
Greenplum的Segment实例是独立的PostgreSQL数据库,每个数据库存储一部分数据并执行一部分查询处理。当用户通过Master连接到数据库并发出查询时,将在每个Segment数据库中创建进程以处理该查询的工作。有关查询过程的更多信息,参见3.3.3小节。
用户定义的表及其索引分布在所有可用的Segment中,每个Segment都包含互斥的部分数据(复制表除外,这种表会在每个Segment实例上存储一份完整的数据拷贝)。提供服务的数据库服务器进程在相应的Segment实例下运行。
Segment在称为段主机的服务器上运行。段主机通常运行2到8个Segment实例,具体数量取决于CPU核、内存、磁盘、网卡和工作负载。所有段主机的配置应该相同,以避免木桶效应。从Greenplum获得最佳性能的关键是将数据和负载均匀分布到多个能力相同的Segment上,以便所有Segment同时处理任务并同时完成其工作。
3.2.3 Interconnect
Interconnect内部互连是Greenplum数据库体系结构中的核心组件,互连指的是Segment在网络间的进程间通信。Interconnect使用标准以太网交换数据,出于性能原因,建议使用万兆网或更快的系统。
默认情况下,Interconnect使用带有流量控制的用户数据报协议(User Datagram Protocol with flow control,UDPIFC)进行通信,通过网络发送消息。Greenplum软件执行超出UDP提供的数据包验证,这意味着可靠性相当于传输控制协议(Transmission Control Protocol,TCP),性能和可扩展性超过TCP。如果将Interconnect改为TCP,Greenplum数据库的可伸缩性限制为1000个Segment实例,UDPIFC作为Interconnect的默认协议不受此限制。
Interconnect实现了对同一个集群中多个PostgreSQL实例的高效协同和并行计算,承载了并行查询计划生产和派遣分发(Query Dispatch,QD)、协调节点上查询执行器(Query Executor,QE)的并行工作,负责数据分布、Pipeline计算、镜像复制、健康探测等等诸多任务。
3.3 Greenplum功能特性
Greenplum绝不仅仅只是“PostgreSQL + Interconnect并行调度 + 分布式事务”这么简单,它还提供了许多高级数据分析管理功能和企业级管理模块。本节介绍其中几个重要的特色功能。
3.3.1 存储模式
Greenplum提供了几种灵活的存储模式,创建表时可以选择如何存储其数据。建表时通过定义本小节介绍的存储选项,为工作负载选择最佳存储模式。为了简化建表时定义存储模式,可以通过gp_default_storage_options参数设置缺省的存储选项。
1. Heap存储
Greenplum默认使用与PostgreSQL相同的堆(Heap)存储模型。堆表适用于OLTP类型的工作负载,在这种工作负载中,数据通常在最初装载后进行修改。update和delete操作需要存储行级别的版本控制信息以确保数据库事务处理的可靠性。堆存储适合小表,例如维度表,这些表通常在初始装载后更新。
行存对表是缺省的存储模式,建表时不需要额外语法:
-- 建表
create table foo (a int, b text) distributed by (a);
-- 查看表信息
\\d foo
Table "public.foo"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
b | text |
Distributed by: (a)Greenplum在6版本中引入了全局死锁检测的新概念,以降低update和delete的锁级别。6以前的版本中,update和delete操作使用表级排它锁,也就是说,在6之前的版本,一张表上同时只能有一个update或者delete语句被执行,其它的update或delete语句需要等待前面的语句执行完成之后才获得所需要的锁。
从6版本开始,打开全局死锁检后,堆存储表update和delete操作的锁将降低为行级排它锁。允许并发更新。全局死锁检测确定是否存在死锁,并通过取消一个或多个与最年轻事务相关联的后端进程来消除死锁。全局死锁检测由gp_enable_global_deadlock_detector参数控制,缺省为off:
$ gpconfig -s gp_enable_global_deadlock_detector
Values on all segments are consistent
GUC : gp_enable_global_deadlock_detector
Master value: off
Segment value: off
$ gpconfig -c gp_enable_global_deadlock_detector -v on
$ gpstop -arf
$ gpconfig -s gp_enable_global_deadlock_detector
Values on all segments are consistent
GUC : gp_enable_global_deadlock_detector
Master value: on
Segment value: on另外,如果要进行高并发insert、update、delete操作,建议关闭log_statement参数(缺省为all),因为过多的日志输出也会影响这种操作的性能。
2. Append-Optimized存储
Append-Optimized存储表(后简称AO表)适合于数据仓库环境中非规范化的事实表。事实表通常分批加载,并通过只读查询进行访问,是系统中最大的表。将大型事实表采用AO存储可消除维护行级更新的多版本控制存储开销,每行可节省约20字节,这使得存储页面结构更精简、更易于优化。而且AO表一般还会选择压缩选项,可以大大节省存储空间。AO存储模型针对批量数据装载进行了优化,不建议使用单行insert语句。 通过create table的with子句定义存储选项,缺省不指定with子句时,创建的是行存堆表(如果设置了gp_default_storage_options参数,存储模式与该参数的设置一致)。下面是一个创建不带压缩选项的AO表的例子:
-- 建表
create table bar (a int, b text) with (appendoptimized=true) distributed by (a);
-- 查看表信息
\\d bar
Append-Only Table "public.bar"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
b | text |
Compression Type: None
Compression Level: 0
Block Size: 32768
Checksum: t
Distributed by: (a)appendoptimized是以前appendonly的别称,在系统表中仍然存储appendonly关键字,显示存储信息时也将显示appendonly。在可重复读或串行化隔离级事务中,不允许对AO表进行update或delete。cluster、declare ... for update不适用于AO表。
3. 选择行存或列存
Greenplum支持在create table时选择行存或列存,或者在分区表中为不同分区做不同选择,具体情况需要根据业务场景进行确切评估。建议绝大部分情况下选择行存,因为现在的列存技术容易导致文件数严重膨胀,后果更为严重。
从一般角度说,行存具有更广泛的适用性,列存对于一些特定的业务场景可以节省大量I/O资源以提升性能,也可以提供更好的压缩效果。在考虑行存还是列存时可参考如下几点:
- 数据更新:如果一张表在数据装载后有频繁的更新操作,则选择行存堆表。列存表必须是AO表,所以没有别的选择。
- insert频率:如果有频繁的insert操作,那么就选择行存表。列存表不擅长频繁地insert操作,因为列存表在物理存储上每一个字段都对应一个文件,频繁地insert操作将需要每次都写很多个文件。
- 查询涉及的列数:如果在select列表或where条件中经常涉及很多字段,选择行存表。列存表对于大数据量的单字段聚合查询表现更好,如:
select sum(salary) ...
select avg(salary) where salary > 10000或者在where条件中使用单独字段进行条件过滤且返回相对少量的记录数,如:
select salary, dept ... where state='ca'- 表中列数:当需要同时查询许多列,或者当表的行大小相对较小时,行存效率更高。对于列很多,但只查询很少列时,列存表提供更好的查询性能。
- 压缩:列存表将具有相同的数据类型列数据连续存储在一起,因此对于相同的数据和压缩选项,往往列存的压缩效果更好,而行存无法具备这种优势。当然,越好的压缩效果意味着越困难的随机访问,因为数据读取都需要解压缩。不过6版本引入的ZSTD压缩算法具有非常优秀的压缩/解压缩效率。
在create table时使用with子句指定表的存储模式,缺省使用行存堆表。列存表必须是AO表。下面语句创建一个不带压缩的列存表:
-- 建表
create table bar (a int, b text) with (appendoptimized=true, orientation=column) distributed by (a);
-- 查看表信息
\\d bar
Append-Only Columnar Table "public.bar"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
b | text |
Checksum: t
Distributed by: (a)4. 使用压缩(必须是AO表)
AO表的压缩可以作用于整个表,也可以压缩特定列,可以对不同的列应用不同的压缩算法。表3-1总结了可用的压缩算法。
| 行或列 | 可用压缩类型 | 支持的压缩算法 |
|---|---|---|
| 行 | 表级 | ZLIB, ZSTD, and QUICKLZ(开源版本不可用) |
| 列 | 列级或表级 | RLE_TYPE, ZLIB, ZSTD, and QUICKLZ(开源版本不可用) |
表3-1 AO表压缩算法
选择AO表的压缩类型和级别时,需要考虑以下因素:
- CPU性能:Segment主机需要有足够的CPU资源进行压缩和解压缩。
- 压缩比/磁盘大小:最小化磁盘大小是一个因素,但也要考虑压缩和扫描数据所需的时间和CPU资源。我们需要找到有效压缩数据的最佳设置,而不会导致过长的压缩时间或较慢的扫描速度。
- 压缩速度:QuickLZ压缩通常使用较少的CPU资源,比zlib压缩速度快,但压缩率低。zlib压缩率高,但压缩速度慢。例如,在压缩级别1(compresslevel=1)下,QuickLZ和zlib具有相当的压缩率,尽管速度不同。与QuickLZ相比,使用压缩级别为6的zlib可以显著提高压缩率,但压缩速度较低。Zstandard compression则可以提供良好的压缩率或速度。
- 解压缩/扫描速度。压缩AO表的性能不仅取决于压缩选项,还与硬件、查询优化设置等因素有关。应该进行比较测试以确定合适的压缩选项。
不要在使用压缩的文件系统上创建压缩AO表,这样做只会来带额外的CPU开销。下面语句创建压缩级别为5的zlib压缩的AO表:
-- 建表
create table foo (a int, b text) with (appendoptimized=true, compresstype=zlib, compresslevel=5);
-- 查看表信息
\\d foo
Append-Only Table "public.foo"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
b | text |
Compression Type: zlib
Compression Level: 5
Block Size: 32768
Checksum: t
Distributed by: (a)5. 检查AO表的压缩与分布情况
Greenplum提供了内置函数用以检查AO表的压缩率和分布情况。这两个函数可以使用对象ID或表名作为参数,表名可能需要带模式名,如表3-2所示。
| 函数 | 返回类型 | 描述 |
|---|---|---|
| get_ao_distribution(name) get_ao_distribution(oid) | 集合类型(dbid, tuplecount) | 展示AO表的分布情况,每行对应segid和记录数。 |
| get_ao_compression_ratio(name) get_ao_compression_ratio(oid) | float8 | 计算AO表的压缩率。如果该信息未得到,将返回-1。 |
表3-2 压缩AO表元数据函数
压缩率得到的是一个常见的比值类型。例如,返回值3.19或3.19:1表示未压缩表的大小略大于压缩表大小的三倍。表的分布作为一组行返回,指示每个Segment上存储该表的记录数。例如,在一个有着四个Segment的系统上,dbid范围为0-3,函数返回类似下面的结果集:
=# select get_ao_distribution('lineitem_comp');
get_ao_distribution
---------------------
(0,7500721)
(1,7501365)
(2,7499978)
(3,7497731)
(4 rows)3.3.2 事务与并发控制
数据库管理系统中的并发控制机制使并发查询都返回正确的结果,同时确保数据完整性。传统数据库的分布式事务使用两阶段锁协议,防止一个事务修改另一个并发事务读取的数据,并防止任何并发事务读取或写入另一个事务更新的数据,即读写相互阻塞。协调事务所需的锁会增加数据库争用,因而降低总体事务吞吐量。
Greenplum沿用PostgreSQL多版本并发控制(Multiversion Concurrency Control,MVCC)模型来管理堆表的并发分布式事务。使用MVCC,每个查询都会取得一个查询启动时的数据库快照。查询在运行时无法看到其它并发事务所做的更改。这可以确保查询所看到的是数据库一致性视图。读取行的查询永远不会阻塞写入行的事务,写入行的查询不会被读取行的事务阻塞。与传统的使用锁来协调读写数据事务之间的访问相比,MVCC允许更大的并发性。AO表使用的并发控制模型与这里讨论的MVCC模型不同,它们适用于“一次写入,多次读取”的应用程序,这类应用从不或很少执行行级更新。
1. 快照
快照是在语句或事务开始时可见的一个行集,可确保查询在执行期间具有一致且有效的数据视图。一个新事务开始时被分配一个唯一的事务ID(XID),它是一个递增的32位整数。未包含在事务中的SQL语句被视为单语句事务,BEGIN和COMMIT被隐式添加,效果类似于某些数据库系统(如mysql)中的自动提交。Greenplum仅将XID值分配给涉及DDL或DML操作的事务,这些事务通常是唯一需要XID的事务。
当事务插入一行时,XID与该行一起保存在xmin系统列中。当事务删除一行时,XID保存在xmax 系统列中。更新一行被视为先删除再插入,因此XID保存到已删除行的xmax和新插入行的xmin。xmin和xmax列以及事务完成状态所确定的一系列事务,其中的行版本对当前事务是可见的。一个事务可以看到小于xmin的所有事务的执行结果(保证已提交),但不能看到任何大于或等于xmax的事务结果(未提交)。
对于多语句事务,还必须标识事务中插入行或删除行的命令,以便可以看到当前事务中前面语句所做的更改。cmin系统列标识事务中的插入命令,cmax系统列标识事务中的删除命令。命令标识仅在事务期间起作用,因此在事务开始时将该值将重新从0开始累加。cmin和cmax用于判断同一个事务内的其它命令导致的行版本变更是否可见。
XID是数据库实例的一个属性。每个Segment实例都有自己的XID序列,无法与其它Segment的XID进行比较。主机使用集群范围的会话ID号(称为gp_session_ID)与Segment协调分布式事务,Segment维护分布式事务ID与其本地XID的映射。Master使用两阶段提交协议在所有Segment之间协调分布式事务。如果事务在任何一个Segment上执行失败,它将在所有Segment上回滚。
可以通过select语句查看任意行的xmin、xmax、cmin和cmax系统列:
select xmin, xmax, cmin, cmax, * from tablename;在Master上执行的查询返回的XID是分布式事务ID。如果在单个Segment实例中运行该查询,那么xmin和xmax值将是该Segment的本地事务ID。
Greenplum将复制表(replicated table)的所有行分布到每个Segment,因此每一行在每个Segment上都是重复的。每个Segment实例维护自己的xmin、xmax、cmin和cmax以及gp_segment_id和ctid系统列值。Greenplum不允许用户查询从Master访问复制表的这些系统列(将会得到一个字段不存在的错误信息),因为它们没有明确的单一值。
2. 事务ID回卷
如前所述,MVCC模型使用事务ID(XID)来确定在查询或事务开始时哪些行可见。XID是一个32位的整数,因此理论上Greenplum最大可以运行大约42亿个事务,之后XID将回卷重置。Greenplum对XID使用模2的32次方的计算方式,这允许事务ID循环使用。对于任何给定的XID,过去的XID大约有20亿,未来的XID大约有20亿。这里有个问题,当一行的版本持续存在了大约20亿个事务后,再循环使用时,该行的XID又从头开始计数,使它突然看似为一个新行。为了防止这种情况,Greenplum有一种称为Frozen XID的特殊XID,它比任何常规XID都要老。某一行的xmin必须要在20亿次事务内替换为Frozen XID,这也是VACUUM命令执行的功能之一。
每隔20亿个事务对数据库进行至少一次清理,就可以防止XID回卷。Greenplum数据库监视事务ID,并且在需要一次VACUUM操作时发出警告。当事务ID大部分不再可用,且在事务ID发生回卷之前,将发出警告:
WARNING: database "database_name" must be vacuumed within number_of_transactions transactions发出警告时就需要一次VACUUM操作。如果没有执行所需的VACUUM操作,Greenplum在事务ID发生回卷前且达到一个限度时,会停止创建新事务以避免可能的数据丢失,并发出以下错误:
FATAL: database is not accepting commands to avoid wraparound data loss in database "database_name"有关从此错误中恢复的过程,参阅Routine System Maintenance Tasks | Greenplum Docs。
服务器配置参数xid_warn_limit和 xid_stop_limit控制何时显示这些警告和错误。xid_warn_limit参数指定在xid_stop_limit之前多少个事务ID时发出警告。xid_stop_limit参数指定在回卷发生之前多少个事务ID时发出错误并且不再允许创建新事务。
3. 事务隔离模式
SQL标准描述了数据库事务并发运行时可能出现的三种现象:
- 脏读:一个事务可以从另一个并发事务中读取未提交的数据。
- 不可重复读:一个事务两次读取同一行得到不同的结果,因为另一个并发事务在这个事务开始后提交了更改。
- 幻读:在同一事务中执行两次查询可以返回两组不同的行,因为另一个并发事务添加了行。
SQL标准定义了数据库系统可以支持的四个事务隔离级别,以及每个级别下并发执行事务时所允许的现象,如表3-3所示。
| 隔离级 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommitted | 可能 | 可能 | 可能 |
| Read Committed | 不可能 | 可能 | 可能 |
| Repeatable Read | 不可能 | 不可能 | 可能 |
| Serializable | 不可能 | 不可能 | 不可能 |
表3-3 SQL事务隔离模式
Greenplum缺省的事务隔离级为read committed,由default_transaction_isolation参数指定。Greenplum的read uncommitted和read committed隔离模式的行为类似于SQL标准的read committed模式,serializable和repeatable read隔离模式的行为类似于SQL标准的repeatable read模式,只是还防止了幻读。
read committed和repeatable read之间的区别在于,前者事务中的每个语句只能看到在语句启动之前提交的行,而后者事务中的语句只能看到在事务启动之前提交的行。
在read committed隔离模式下,如果另一个并发事务自事务开始以来已提交更改,则在事务中检索两次的行中的值可能不同。read committed模式还允许幻读,在同一事务中运行两次查询可以返回两组不同的行。
Greenplum的repeatable read隔离模式可避免不可重复读和幻读。试图修改由另一个并发事务修改的数据的事务将被回滚。如果应用程序不需要repeatable read隔离模式,则最好使用read committed模式以提高并发。
Greenplum不保证并发运行的一组事务产生与串行化顺序执行相同的结果。若指定了serializable隔离级,Greenplum数据库将返回到可重复读。
对于Greenplum的并发事务,应检查并识别可能并发更新相同数据的事务。对识别出来的问题,可以通过使用显式的表锁,或要求冲突的事务更新一个虚行(该虚行表示冲突),来防止该问题发生。SQL语句SET TRANSACTION ISOLATION LEVEL可以设置当前事务的隔离模式。必须要在执行SELECT、INSERT、DELETE、UPDATE或COPY语句前设置:
begin;
set transaction isolation level repeatable read;
...
commit;隔离模式也可以指定为BEGIN语句的一部分:
begin transaction isolation level repeatable read;4. 删除过期行
更新或删除行会在表中保留该行的过期版本,当过期的行不再被任何活动事务引用时,可以删除该行并重新使用它占用的空间。VACUUM命令将过期行使用的空间标记为可重用。
当表中过期的行累积后,必须扩展磁盘文件以容纳新行。由于运行查询所需的磁盘I/O增加,性能会下降,这种情况称为膨胀(bloat),应该通过定期清理表来进行管理。
不带FULL的VACUUM 命令可以与其它查询同时运行。它会标记之前被过期行所占用的空间为空闲,并更新空闲空间映射。当Greenplum之后需要空间分配给新行时,它首先会查询该表的空闲空间映射,寻找有可用空间的页面。如果没有找到这样的页面,会为该文件追加新的页面。
不带FULL的VACUUM不会合并页面或者减小表在磁盘上的尺寸。它回收的空间只是放在空闲空间映射中表示可用。为了防止磁盘文件大小增长,经常运行VACUUM非常重要。运行VACUUM的频率取决于表中更新和删除(插入只会增加新行)的频率。大量更新的表可能每天需要运行几次VACUUM,以确保通过空闲空间映射能找到可用的空闲空间。在一个更新或者删除大量行的事务之后运行VACUUM也非常重要。
VACUUM FULL命令会把表重写为没有过期行,并且将表减小到其最小尺寸。表中的每一页面都会被检查,其中的可见行被移动到前面还没有完全填满的页面中,空页面会被丢弃。该表会被一直锁住直到VACUUM FULL完成。相对于常规的VACUUM命令来说,它是一种非常昂贵的操作,可以用定期的清理来避免或者推迟这种操作。最好是在一个维护期来运行VACUUM FULL。VACUUM FULL的一种替代方案是,用一个CREATE TABLE AS语句重新创建表并且删除掉旧表。
可以运行VACUUM VERBOSE tablename来得到一份Segment上已移除的过期行数量、受影响页面数以及可用空闲空间页面数的报告。查询pg_class系统表可以找出一个表在所有Segment上使用了多少页面。注意应先对该表执行ANALYZE确保得到的是准确的数据。
select relname, relpages, reltuples from pg_class where relname='tablename';另一个有用的工具是gp_toolkit模式中的gp_bloat_diag视图,它通过比较表使用的实际页数与预期页数来鉴别表膨胀。
5. 管理事务ID示例
下面看一个Greenplum官方文档中提供的示例。这个简单的例子说明了MVCC的概念以及它如何使用事务ID管理数据和事务,展示的概念如下:
- 如何使用事务ID管理表上的多个并发事务。
- 如何使用Frozen XID管理事务ID。
- 模计算如何根据事务ID确定事务的顺序。
示例表假设如下:
- 该表是一个包含2列和4行数据的简单表。
- 有效的事务ID(XID)值从0到9,9之后,XID将在0处重新启动。
- Frozen XID为-2(与Greenplum数据库不同)。
- 事务在一行上执行。
- 仅执行插入和更新操作。
- 所有更新的行都保留在磁盘上,不执行删除过期行的操作。
表的初始数据如表3-4所示,xmin的顺序即为行插入的顺序。
| item | amount | xmin | xmax |
|---|---|---|---|
| widget | 100 | 0 | null |
| giblet | 200 | 1 | null |
| sprocket | 300 | 2 | null |
| gizmo | 400 | 3 | null |
表3-4 初始示例表
表3-5显示了对金额列执行如下更新后的表数据。
- xid = 4: update tbl set amount=208 where item = 'widget'
- xid = 5: update tbl set amount=133 where item = 'sprocket'
- xid = 6: update tbl set amount=16 where item = 'widget'
粗体表示当前行,其它是过期行。可以通过xmax为null值条件确定表的当前行(Greenplum使用了稍微不同的方法来确定当前表行)。
| item | amount | xmin | xmax |
|---|---|---|---|
| widget | 100 | 0 | 4 |
| giblet | 200 | 1 | null |
| sprocket | 300 | 2 | 5 |
| gizmo | 400 | 3 | null |
| widget | 208 | 4 | 6 |
| sprocket | 133 | 5 | null |
| widget | 16 | 6 | null |
表3-5 更新示例表
MVCC使用XID值确定表的状态。例如下面两个独立事务同时运行。在UPDATE事务期间,查询返回300,直到UPDATE事务完成。
- UPDATE命令将sprocket数量值更改为133(xmin值5)。
- SELECT命令返回sprocket的值。
对于这个简单的示例,数据库的可用XID值即将用完。当Greenplum即将用完可用的XID值时将执行以下操作:
- 发出警告,指出数据库的XID值即将用完。
- 在分配最后一个XID之前,Greenplum停止接收事务,以防止两个事务分配同一XID值,并发出严重告警。
为了管理存储在磁盘上的事务ID和表数据,Greenplum提供了VACUUM命令。
- VACUUM操作释放XID值,以便通过将xmin值更改为Frozen XID,使表可以有10行以上。
- VACUUM命令更改XID值为obsolete以指示过期行。Greenplum中不带FULL的VACUUM操作会适时删除磁盘上的行,并且对性能和数据可用性影响最小。
表3-6显示在示例表上执行VACUUM操作后的情况,该命令更新了磁盘上的表数据。这里显示执行方式与Greenplum中的VACUUM命令略有不同,但概念相同。
- 对于磁盘上不再是当前的widget行和sprocket行标记为过时。
- 对于当前的giblet和gizmo行,xmin已更改为Frozen XID,这些值仍然是当前表值(行的xmax值为null)。这些表行对所有事务都可见,因为当执行模计算时,xmin值是Frozen XID,比所有其它XID值都小。
VACUUM操作后,XID值0、1、2和3可供使用。
| item | amount | xmin | xmax |
|---|---|---|---|
| widget | 100 | obsolete | obsolete |
| giblet | 200 | -2 | null |
| sprocket | 300 | obsolete | obsolete |
| gizmo | 400 | -2 | null |
| widget | 208 | 4 | 6 |
| sprocket | 133 | 5 | null |
| widget | 16 | 6 | null |
表3-6 VACUUM后的示例表
当更新xmin值为-2的磁盘行时,xmax值会像往常一样替换为事务XID,并且在访问该行的任何并发事务完成后,磁盘上的行将被视为过期,可以从磁盘删除过期行。对于Greenplum数据库,带有FULL选项的VACUUM命令执行更广泛的处理以回收磁盘空间。
表3-7显示了更多更新事务后磁盘上的表数据。XID值已回卷并在0处重新开始,没有进行额外的VACUUM操作。
| item | amount | xmin | xmax |
|---|---|---|---|
| widget | 100 | obsolete | obsolete |
| giblet | 200 | -2 | 1 |
| Greenplum 实时数据仓库实践——实时数据装载 |