Greenplum 实时数据仓库实践——实时数据装载
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Greenplum 实时数据仓库实践——实时数据装载相关的知识,希望对你有一定的参考价值。
目录
上一篇详细讲解了如何用Canal和Kafka,将mysql数据实时全量同步到Greenplum。对照本专题第一篇中图1-1的数据仓库架构,我们已经实现了ETL的实时抽取过程,将数据同步到RDS中。本篇继续介绍如何实现后面的数据装载过程。实现实时数据装载的总体步骤可归纳为:
1. 前期准备
为尽量缩短MySQL复制停止的时间,这步包含所有可在前期完成的工作:
(1)在目标Greenplum中创建所需对象,如专用资源队列、模式、过渡区表、数据仓库的维度表和事实表等。
(2)预装载,如日期维度数据。
(3)配置Canal Adapter的表映射关系,为每个同步表生成一个yml文件。
2. 停止MySQL复制
提供静止数据视图。
3. 全量ETL
(1)执行全量同步,将需要同步的MySQL表数据导入Greenplum的过渡区表中。
(2)在Greenplum中用SQL完成初始装载。
4. 创建rule
全量ETL后,实时ETL前,在Greenplum中创建rule对象,实现自动实时装载逻辑。
5. 重启Canal Server和Canal Adapter
准备从MySQL从库获取binlog,经Kafka中转,将数据变化应用于Greenplum的过渡区表。
(1)停止Canal Server,删除meta.dat和h2.mv.db文件。如果配置了HA,停止集群中的所有Canal Server,并在Zookeeper中删除当前同步数据节点。
(2)停止Canal Adapter。
(3)启动Canal Server。如果配置了HA,启动集群中的所有Canal Server,此时会在Zookeeper中重置增量数据同步位点。
(4)启动Canal Adapter。
6. 启动MySQL复制,自动开始实时ETL。
停止MySQL复制期间的增量变化数据自动同步,并触发rule自动执行实时装载。
我们首先引入一个小而典型的销售订单示例,描述业务场景,说明示例中包含的实体和关系,以及源和目标库表的建立过程、测试数据和日期维度生成等内容。然后使用Greenplum的SQL脚本完成初始数据装载。最后介绍Greenplum的rule对象,并通过创建rule,将数据从RDS自动实时地载入TDS。对创建示例模型过程中用到的Greenplum技术或对象,随时插入相关说明。
6.1 建立数据仓库示例模型
6.1.1 业务场景
1. 操作型数据源
示例的操作型系统是一个销售订单系统,初始时只有产品、客户、销售订单三个表,实体关系图如图6-1所示。
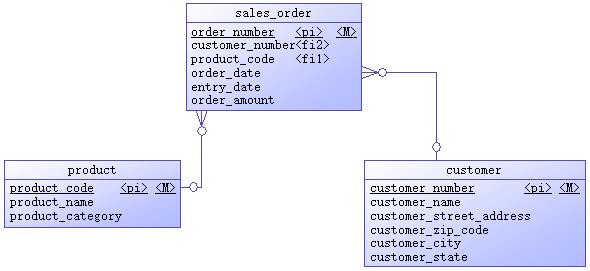
图6-1 数据源实体关系图
这个场景中的表及其属性都很简单。产品表和客户表属于基本信息表,分别存储产品和客户的信息。产品只有产品编号、产品名称、产品分类三个属性,产品编号是主键,唯一标识一个产品。客户有六个属性,除客户编号和客户名称外,还包含省、市、街道、邮编四个客户所在地区属性。客户编号是主键,唯一标识一个客户。在实际应用中,基本信息表通常由其它后台系统维护。销售订单表有六个属性,订单号是主键,唯一标识一条销售订单记录。产品编号和客户编号是两个外键,分别引用产品表和客户表的主键。另外三个属性是订单时间、登记时间和订单金额。订单时间指的是客户下订单的时间,订单金额属性指的是该笔订单需要花费的金额,这些属性的含义很清楚。订单登记时间表示订单录入的时间,大多数情况下它应该等同于订单时间。如果由于某种情况需要重新录入订单,还要同时记录原始订单的时间和重新录入的时间,或者出现某种问题,订单登记时间滞后于下订单的时间(本专题后面事实表技术的“迟到的事实”部分会讨论这种情况),这两个属性值就会不同。
源系统采用关系模型设计,为了减少表的数量,这个系统只做到了2NF。地区信息依赖于邮编,所以这个模型中存在传递依赖。
2. 销售订单数据仓库模型设计
我们使用2.2.1 维度数据模型建模过程介绍的四步建模法设计星型数据仓库模型。
(1)选择业务流程。在本示例中只涉及一个销售订单的业务流程。
(2)声明粒度。ETL实时处理,事实表中存储最细粒度的订单事务记录。
(3)确认维度。显然产品和客户是销售订单的维度。日期维度用于业务集成,并为数据仓库提供重要的历史视角,每个数据仓库中都应该有一个日期维度。订单维度是特意设计的,用于后面说明退化维度技术。我们将在本专题的维度表技术中详细介绍退化维度。
(4)确认事实。销售订单是当前场景中唯一的事实。
示例数据仓库的实体关系图如图6-2所示。
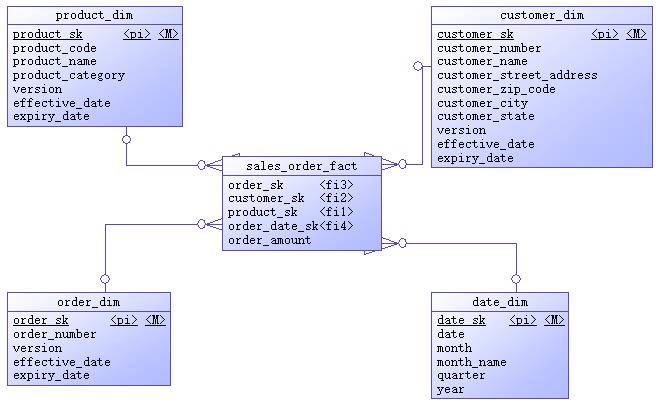
图6-2 数据仓库实体关系图
作为演示示例,上面实体关系图中的实体属性都很简单,看属性名字便知其含义。除了日期维度外,其它三个维度都在源数据的基础上增加了代理键、版本号、生效日期、过期日期四个属性,用来描述维度变化的历史。当维度属性发生变化时,依据不同的策略,或生成一条新的维度记录,或直接修改原记录。日期维度有其特殊性,该维度数据一旦生成就不会改变,所以不需要版本号、生效日期和过期日期。代理键是维度表的主键。事实表引用维度表的代理键作为自己的外键,四个外键构成了事实表的联合主键。订单金额是当前事实表中的唯一度量。
6.1.2 建立数据库表
为了创建一个从头开始的全新环境,避免建立实时数据仓库示例模型过程中出现数据同步出错,建立库表前先停止正在运行的Canal Server(HA两个都停)和Canal Adapter。
# 构成Canal HA的126、127两台都执行
~/canal_113/deployer/bin/stop.sh
# 查询Zookeeper确认
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /otter/canal/destinations/example/cluster
[]
# 停止Canal Adapter,126执行
~/canal_113/adapter/bin/stop.sh1. 在MySQL主库中创建源库对象并生成测试数据
(1)执行下面的SQL语句建立源数据库表。
-- 建立源数据库,126主库上执行
drop database if exists source;
create database source;
use source;
-- 建立客户表
create table customer (
customer_number int not null auto_increment primary key comment '客户编号,主键',
customer_name varchar(50) comment '客户名称',
customer_street_address varchar(50) comment '客户住址',
customer_zip_code int comment '邮编',
customer_city varchar(30) comment '所在城市',
customer_state varchar(2) comment '所在省份'
);
-- 建立产品表
create table product (
product_code int not null auto_increment primary key comment '产品编码,主键',
product_name varchar(30) comment '产品名称',
product_category varchar(30) comment '产品类型'
);
-- 建立销售订单表
create table sales_order (
order_number bigint not null auto_increment primary key comment '订单号,主键',
customer_number int comment '客户编号',
product_code int comment '产品编码',
order_date datetime comment '订单时间',
entry_date datetime comment '登记时间',
order_amount decimal(10 , 2 ) comment '销售金额',
foreign key (customer_number)
references customer (customer_number)
on delete cascade on update cascade,
foreign key (product_code)
references product (product_code)
on delete cascade on update cascade
);(2)执行下面的SQL语句生成源库测试数据
use source;
-- 生成客户表测试数据
insert into customer
(customer_name,customer_street_address,customer_zip_code,
customer_city,customer_state)
values
('really large customers', '7500 louise dr.',17050, 'mechanicsburg','pa'),
('small stores', '2500 woodland st.',17055, 'pittsburgh','pa'),
('medium retailers','1111 ritter rd.',17055,'pittsburgh','pa'),
('good companies','9500 scott st.',17050,'mechanicsburg','pa'),
('wonderful shops','3333 rossmoyne rd.',17050,'mechanicsburg','pa'),
('loyal clients','7070 ritter rd.',17055,'pittsburgh','pa'),
('distinguished partners','9999 scott st.',17050,'mechanicsburg','pa');
-- 生成产品表测试数据
insert into product (product_name,product_category)
values
('hard disk drive', 'storage'),
('floppy drive', 'storage'),
('lcd panel', 'monitor');
-- 生成100条销售订单表测试数据
drop procedure if exists generate_sales_order_data;
delimiter //
create procedure generate_sales_order_data()
begin
drop table if exists temp_sales_order_data;
create table temp_sales_order_data as select * from sales_order where 1=0;
set @start_date := unix_timestamp('2021-06-01');
set @end_date := unix_timestamp('2021-10-01');
set @i := 1;
while @i<=100 do
set @customer_number := floor(1 + rand() * 6);
set @product_code := floor(1 + rand() * 2);
set @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
set @amount := floor(1000 + rand() * 9000);
insert into temp_sales_order_data values (@i,@customer_number,@product_code,@order_date,@order_date,@amount);
set @i:=@i+1;
end while;
truncate table sales_order;
insert into sales_order
select null,customer_number,product_code,order_date,entry_date,order_amount from temp_sales_order_data order by order_date;
commit;
end
//
delimiter ;
call generate_sales_order_data();客户表和产品表的测试数据取自《Dimensional Data Warehousing with MySQL》一书。我们创建一个MySQL存储过程生成100条销售订单测试数据。为了模拟实际订单的情况,订单表中的客户编号、产品编号、订单时间和订单金额都取一个范围内的随机值,订单时间与登记时间相同。因为订单表的主键是自增的,为了保持主键值和订单时间字段的值顺序保持一致,引入了一个名为temp_sales_order_data的表,存储中间临时数据。在后面都是使用此方案生成订单测试数据。
2. 在Greenplum中创建目标库对象
(1)创建资源队列
# 用gpadmin用户连接Greenplum
psql
-- 创建资源队列
create resource queue rsq_dwtest with
(active_statements=20,memory_limit='8000MB',priority=high,cost_overcommit=true,min_cost=0,max_cost=-1);
-- 修改dwtest用户使用的资源队列
alter role dwtest resource queue rsq_dwtest;
-- 查看用户资源队列
select rolname, rsqname from pg_roles, pg_resqueue
where pg_roles.rolresqueue=pg_resqueue.oid;资源组和资源队列是Greenplum用于管理资源的两种对象,缺省使用资源队列。所有用户都必须分配到资源队列,如果创建用户时没有指定,该用户将会被分配到缺省的资源队列pg_default。
建议为不同类型的工作负载创建独立的资源队列。例如,可以为高级用户、WEB用户、报表管理等创建不同的资源队列。可以根据相关工作的负载压力设置合适的资源队列限制。
active_statements控制最大活动语句数量,设置为20,意味着分配到rsq_dwtest资源队列的所有用户,在同一时刻最多只能有20个语句处于执行状态。超过的语句将处于等待状态,直到前面正在执行的语句有完成的。
memory_limit控制该队列可以使用的内存总量。所有资源队列总的memory_limit建议设置为一个Primary可以获得的物理内存总数的90%以下。本环境中单台机器128GB内存,配置有6个Primary,每个Primary可以获得的物理内存为21GB。如果存在多个资源队列,它们的memory_limit总和不应超过21GB * 0.9 = 19GB。
当与active_statements结合使用时,缺省为每个语句分配的内存为:memory_limit / active_statements。如果某个Primary超出内存限制,相关语句会被取消而导致失败。所以如何更合理地配置内存参数,以真实生产环境的统计结果为依据进行调整最为稳妥。
priority控制CPU使用优先级,缺省为medium。在并发争抢CPU时,高优先级资源队列中的语句将可以获得更多的CPU资源。要使资源队列的优先级设置在执行语句中强制生效,必须确保gp_resqueue_priority参数已经设置为on。
min_cost和max_cost分别限制被执行语句可消耗的最小、最大成本。Cost是查询优化器评估出来的总预计成本,意味着对磁盘的操作数量,以一个浮点数表示。例如,1.0相当于获取一个磁盘页(disk page)。本例中的rsq_dwtest设置为不限制执行成本。
若一个资源队列配置了Cost阈值,则可以设置允许cost_overcommit。在系统没有其他语句执行时,超过资源队列Cost阈值的语句可以被执行。而当有其他语句在执行时,Cost阈值仍被强制评估和限制。如果cost_overcommit被设置为FALSE,超过Cost阈值的语句将永远被拒绝。
(2)在dw库中建立模式
# 用dwtest用户连接Greenplum
psql -U dwtest -h mdw -d dw
-- 创建rds模式
create schema rds;
-- 创建tds模式
create schema tds;
-- 查看模式
\\dn
-- 修改数据库的模式查找路径
alter database dw set search_path to rds, tds, public, pg_catalog, tpcc_test;
-- 重新连接dw数据库
\\c dw
-- 显示模式查找路径
show search_path;每个Greenplum会话在任一时刻只能连接一个数据库。ETL处理期间,需要将rds与tds中的表关联查询,因此将rds和tds对象存放在单独的数据库中显然是不合适的。这里在dw数据库中创建两个rds和tds模式,rds存储原始数据,作为源数据到数据仓库的过渡,tds存储转化后的多维数据仓库。在对应模式中建表,可使数据的逻辑组织更清晰。
(3)创建rds模式中的数据库对象
-- 设置模式查找路径
set search_path to rds;
-- 建立客户原始数据表
create table customer
(
customer_number int primary key,
customer_name varchar(30),
customer_street_address varchar(30),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2)
);
comment on table customer is '客户原始数据表';
comment on column customer.customer_number is '客户编号';
comment on column customer.customer_name is '客户姓名';
comment on column customer.customer_street_address is '客户地址';
comment on column customer.customer_zip_code is '客户邮编';
comment on column customer.customer_city is '客户所在城市';
comment on column customer.customer_state is '客户所在省份';
-- 建立产品原始数据表
create table product
(
product_code int primary key,
product_name varchar(30),
product_category varchar(30)
);
comment on table product is '产品原始数据表';
comment on column product.product_code is '产品编码';
comment on column product.product_name is '产品名称';
comment on column product.product_category is '产品类型';
-- 建立销售订单原始数据表
create table sales_order
(
order_number bigint,
customer_number int,
product_code int,
order_date timestamp,
entry_date timestamp,
order_amount decimal(10 , 2 ),
primary key (order_number, entry_date)
) distributed by (order_number)
partition by range (entry_date)
( start (date '2021-06-01') inclusive
end (date '2022-04-01') exclusive
every (interval '1 month') );
comment on table sales_order is '销售订单原始数据表';
comment on column sales_order.order_number is '订单号';
comment on column sales_order.customer_number is '客户编号';
comment on column sales_order.product_code is '产品编码';
comment on column sales_order.order_date is '订单时间';
comment on column sales_order.entry_date is '登记时间';
comment on column sales_order.order_amount is '销售金额';rds模式中表数据来自MySQL表,并且是原样装载,不需要任何转换,因此其表结构与MySQL中的表一致。表存储采用缺省的行存堆模式,关于Greenplum表存储模式的选择参见3.3.1 存储模式。当表定义了主键,同时没有指定分布键时,Greenplum使用主键作为分布键,customer、product两表采用此方式。就Greenplum来讲,获得性能最重要的因素是实现数据均匀分布。因此分布键的选择至关重要,它直接影响数据倾斜情况,进而影响处理倾斜,最终影响查询执行速度。选择分布键应以大型任务计算不倾斜为最高目标。下面是Greenplum给出的分布策略最佳实践。
- 对任何表,明确指定分布键,或者使用随机分布,而不是 依赖缺省行为。
- 只有有可能,应该只使用单列作为分布键。如果单列无法实现均匀分布,最多使用两列的分布键。再多的分布列通常不会产生更均匀的分布,并且在散列过程中需要额外的时间。
- 如果两列分布键无法实现数据的均匀分布,使用随机分布。在大多数情况下,多列分布键需要motion操作来连接表,因此它们与随机分布相比没有优势。
- 分布键列数据应包含唯一值或非常高的基数(不同值个数与总行数的比值)。
- 如果不是为了特定的目的设计,尽量不要选用where查询条件中频繁出现的列作为分布键。
- 应该尽量避免使用日期或时间列作为分布键,因为一般不会使用这种列来与其他表列进行关联查询。
- 不要用分区字段作分布键。
- 为改善大表关联性能,应该考虑将大表之间的关联列作为分布键,关联列还必须是相同数据类型。如果关联列数据没有分布在同一段中,则其中一个表所需的行要动态重新分布到其他段。当连接的行位于同一段上时,大部分处理可以在段实例中完成。这些连接称为本地连接。本地连接最小化数据移动,每个网段独立于其他网段运行,网段之间没有网络流量或通信。
- 要定期检查数据分布倾斜和处理倾斜情况。本专题后面的Greenplum运维与监控部分会提供更多关于检查数据倾斜和处理倾斜的信息。
rds存储原始业务数据副本,sales_order表包含全部订单,数据量大。为了便于大表维护,sales_order采取范围分区表设计,每月数据一分区,以登记时间作为分区键。虽然sales_order.order_number列值本身是唯一的,但与MySQL的分区表类似,Greenplum的分区表也要求主键中包含分区键列,否则会报错:
ERROR: PRIMARY KEY constraint must contain all columns in the partition key
HINT: Include column "entry_date" in the PRIMARY KEY constraint or create a part-wise UNIQUE index after creating the table instead.这个限制与分区表的实现有关。Greenplum中的分区表,每个分区物理上都是一个与普通表无异的表,psql的\\d命令将会列出所有分区子表名,可以直接访问这些分区子表。系统数据字典表中存储分区定义,逻辑上将分区组织在一起共同构成一个分区表,对外提供透明访问。与Oracle不同,MySQL和Greenplum的分区表没有全局索引的概念,唯一索引只能保证每个分区内的唯一性。由分区表的定义所决定,分区键的值在分区间互斥,因此将分区键列加入主键中,就可以实现全局唯一性。而且,如果既指定了主键,又指定了分布键,则分布键应该是主键的子集:
HINT: When there is both a PRIMARY KEY and a DISTRIBUTED BY clause, the DISTRIBUTED BY clause must be a subset of the PRIMARY KEY.也正是由于这种分区表的实现方式,当使用多级分区时,很容易产生大量分区子表,会带来极大的性能问题和系统表压力。应该尽可能避免创建多级分区表。
(4)创建tds模式中的数据库对象
-- 设置模式查找路径
set search_path to tds;
-- 建立客户维度表
create table customer_dim (
customer_sk bigserial,
customer_number int,
customer_name varchar(50),
customer_street_address varchar(50),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2),
version int,
effective_dt timestamp,
expiry_dt timestamp,
primary key (customer_sk, customer_number)
) distributed by (customer_number);
-- 建立产品维度表
create table product_dim (
product_sk bigserial,
product_code int,
product_name varchar(30),
product_category varchar(30),
version int,
effective_dt timestamp,
expiry_dt timestamp,
primary key (product_sk, product_code)
) distributed by (product_code);
-- 建立订单维度表
create table order_dim (
order_sk bigserial,
order_number bigint,
version int,
effective_dt timestamp,
expiry_dt timestamp,
primary key (order_sk, order_number)
) distributed by (order_number);
-- 建立日期维度表
create table date_dim (
date_sk serial primary key,
date date,
month smallint,
month_name varchar(9),
quarter smallint,
year smallint );
-- 建立销售订单事实表
create table sales_order_fact (
order_sk bigint,
customer_sk bigint,
product_sk bigint,
order_date_sk int,
year_month int,
order_amount decimal(10 , 2 ),
primary key (order_sk, customer_sk, product_sk, order_date_sk, year_month)
) distributed by (order_sk)
partition by range (year_month)
( partition p202106 start (202106) inclusive ,
partition p202107 start (202107) inclusive ,
partition p202108 start (202108) inclusive ,
partition p202109 start (202109) inclusive ,
partition p202110 start (202110) inclusive ,
partition p202111 start (202111) inclusive ,
partition p202112 start (202112) inclusive ,
partition p202201 start (202201) inclusive ,
partition p202202 start (202202) inclusive ,
partition p202203 start (202203) inclusive
end (202204) exclusive ); 与rds一样,tds中的表也使用缺省按行的堆存储模式。tds中多建了一个日期维度表。数据仓库可以追踪历史数据,因此每个数据仓库都应该有一个与日期时间相关的维度表。为了捕获和表示数据变化,除日期维度表外,其他维度表比源表多了代理键、版本号、版本生效时间和版本过期时间四个字段。日期维度一次性生成数据后就不会改变,因此除了日期本身相关属性,只增加了一列代理键。事实表由维度表的代理键和度量属性构成,初始只有一个销售订单金额的度量值。用户可以声明外键和将此信息保存在系统表中,但Greenplum并不强制执行外键约束。
由于事实表数据量大,采取范围分区表设计。事实表中冗余了一列年月,作为分区键。之所以用年月做范围分区,是考虑到数据分析时经常使用年月分组进行查询和统计,这样可以有效利用分区消除提高查询性能。与rds.sales_order不同,这里显式定义了分区。
装载customer_dim、product_dim、order_dim三个维度表的数据时,明显需要关联rds中对应表的主键,分别是customer_number、product_code和order_number。依据分布键最佳实践,选择单列,并将表间的关联列作为分布键。事实表sales_order_fact的数据装载需要关联多个维度表,其中order_dim是最大的维度表。遵循最佳实践,为实现本地关联,我们本应选择order_number列作为sales_order_fact的分布键,但该表中没有order_number列,它是通过order_sk与order_dim维度表关联。这里选择order_sk作为分布键虽不合理却是故意为之,在本专题后面说明退化维度时,我们将修正该问题。
6.1.3 生成日期维度数据
日期维度是数据仓库中的一个特殊角色。日期维度包含时间概念,而时间是最重要的。因为数据仓库的主要功能之一就是存储和追溯历史数据,所以每个数据仓库里的数据都有一个时间特征。本例中创建一个Greenplum的函数,一次性预装载日期数据。
-- 生成日期维度表数据的函数
create or replace function fn_populate_date (start_dt date, end_dt date)
returns void as $$
declare
v_date date:= start_dt;
v_datediff int:= end_dt - start_dt;
begin
for i in 0 .. v_datediff loop
insert into date_dim(date, month, month_name, quarter, year)
values(v_date, extract(month from v_date), to_char(v_date,'mon'), extract(quarter from v_date), extract(year from v_date));
v_date := v_date + 1;
end loop;
analyze date_dim;
end; $$
language plpgsql;
-- 执行函数生成日期维度数据
select fn_populate_date(date '2020-01-01', date '2022-12-31');
-- 查询生成的日期
select min(date_sk) min_sk, min(date) min_date, max(date_sk) max_sk, max(date) max_date, count(*) c
from date_dim;6.2 初始装载
在数据仓库可以使用前,需要装载历史数据。这些历史数据是导入进数据仓库的第一个数据集合。首次装载被称为初始装载,一般是一次性工作。由最终用户来决定有多少历史数据进入数据仓库。例如,数据仓库使用的开始时间是2021年12月1日,而用户希望装载两年的历史数据,那么应该初始装载2019年12月1日到2021年11月30日之间的源数据。在装载事实表前,必须先装载所有的维度表。因为事实表需要引用维度的代理键。这不仅针对初始装载,也针对定期装载。本节说明执行初始装载的步骤,包括标识源数据、维度历史的处理、开发和验证初始装载过程。
6.2.1 数据源映射
设计开发初始装载步骤前需要识别数据仓库的每个事实表和每个维度表用到的并且是可用的源数据,还要了解数据源的特性,例如文件类型、记录结构和可访问性等。表6-1显示的是销售订单示例数据仓库需要的源数据的关键信息,包括源数据表、对应的数据仓库目标表等属性。这类表格通常称作数据源对应图,因为它反应了每个从源数据到目标数据的对应关系。生成这个表格的过程叫做逻辑数据映射。在本示例中,客户和产品的源数据直接与其数据仓库里的目标表,customer_dim和product_dim表相对应,而销售订单事务表是多个数据仓库表的数据源。
| 源数据 | 源数据类型 | 文件名/表名 | 数据仓库中的目标表 |
| 客户 | MySQL表 | customer | customer_dim |
| 产品 | MySQL表 | product | product_dim |
| 销售订单 | MySQL表 | sales_order | order_dim、sales_order_fact |
表6-1 销售订单数据源映射
6.2.2 确定SCD处理方法
标识出了数据源,现在要考虑维度历史的处理。大多数维度值是随着时间改变的,如客户改变了姓名,产品的名称或分类变化等。当一个维度改变,比如当一个产品有了新的分类时,有必要记录维度的历史变化信息。在这种情况下,product_dim表里必须既存储产品老的分类,也存储产品当前的分类。并且,老的销售订单里的产品引用老的分类。渐变维(Slow Changing Dimensions,SCD)即是一种在多维数据仓库中实现维度历史的技术。有三种不同的SCD技术:SCD 类型1(SCD1),SCD类型2(SCD2),SCD类型3(SCD3):
- SCD1 - 通过更新维度记录直接覆盖已存在的值,它不维护记录的历史。SCD1一般用于修改错误的数据。
- SCD2 - 在源数据发生变化时,给维度记录建立一个新的“版本”记录,从而维护维度历史。SCD2不删除、修改已存在的数据。使用SCD2处理数据变更历史的表有时也被形象地称为“拉链表”,顾名思义,所谓拉链就是记录一条数据从产生开始到当前状态的所有变化信息,像拉链一样串联起每条记录的整个生命周期。
- SCD3 – 通常用作保持维度记录的几个版本。它通过给某个数据单元增加多个列来维护历史。例如,为了记录客户地址的变化,customer_dim维度表有一个customer_address列和一个previous_customer_address列,分别记录当前和上一个版本的地址。SCD3可以有效维护有限的历史,而不像SCD2那样保存全部历史。SCD3很少使用。它只适用于数据的存储空间不足并且用户接受有限维度历史的情况。
同一个维度表中的不同字段可以有不同的变化处理方式。在本示例中,客户维度历史的客户名称使用SCD1,客户地址使用SCD2,产品维度的两个属性,产品名称和产品类型都使用SCD2保存历史变化数据。SQL实现上,对于SCD1一般就直接UPDATE更新属性,而SCD2则要新增记录。
6.2.3 实现代理键
多维数据仓库中的维度表和事实表一般都需要有一个代理键,作为这些表的主键,代理键一般由单列的自增数字序列构成。Greenplum中的bigserial(或serial)数据类型在功能上与MySQL的auto_increment类似,常用于定义自增列。但它的实现方法却与Oracle的sequence类似,当创建bigserial字段的表时,Greenplum会自动创建一个自增的sequence对象,bigserial字段自动引用sequence实现自增。
Greenplum数据库中的序列,实质上是一种特殊的单行记录的表,用以生成自增长的数字,可用于为表的记录生成自增长的标识。Greenplum提供了创建、修改、删除序列的命令,还提供了两个内置函数:nextval()用于获取序列的下一个值;setval()重新设置序列的初始值。
PostgreSQL的currval()和lastval()函数在Greenplum中是不支持的,但可以通过直接查询序列表来获取。例如:
dw=> select last_value, start_value from date_dim_date_sk_seq;
last_value | start_value
------------+-------------
1096 | 1
(1 row)序列对象包括几个属性,如名称、步长(每次增长的量)、最小值、最大值、缓存大小等。还有一个布尔属性 is_called,其含义是nextval()先返回值还是序列的值先增长。例如序列当前值为100,如果is_called为TRUE,则下一次调用nextval()时返回的是101,如果is_called为FALSE,则下一次调用nextval()时返回的是100。
6.2.4 执行初始装载
初始数据装载需要执行两步主要操作,一是将MySQL表的数据装载到RDS模式的表中,二是向TDS模式中的表装载数据。
1. 装载RDS模式的表
使用上一篇介绍的全量数据同步方法实现。
-- 127从库停复制
stop slave;
# 从从库导出数据
cd ~
mkdir -p source_bak
mysqldump -u root -p123456 -S /data/mysql.sock -t -T ~/source_bak source customer product sales_order --fields-terminated-by='|' --single-transaction
# 将导出数据文件拷贝到Greenplum的master主机
scp ~/source_bak/*.txt gpadmin@114.112.77.198:/data/source_bak/
# 用gpadmin用户连接数据库
psql -d dw
-- 设置搜索路径为rds
set search_path to rds;
-- 装载前清空表,实现幂等操作
truncate table customer;
truncate table product;
truncate table sales_order;
-- 将外部数据装载到原始数据表
copy rds.customer from '/data/source_bak/customer.txt' with delimiter '|';
copy rds.product from '/data/source_bak/product.txt' with delimiter '|';
copy rds.sales_order from '/data/source_bak/sales_order.txt' with delimiter '|';
-- 装载数据后,执行查询前,先分析表以提高查询性能
analyze rds.customer;
analyze rds.product;
analyze rds.sales_order; 2. 装载TDS模式的表
用dwtest用户连接Greenplum数据库执行以下SQL实现。
# dwtest用户执行
psql -U dwtest -h mdw -d dw
-- 设置搜索路径
set search_path to tds, rds;
-- 装载前清空表,实现幂等操作
truncate table customer_dim;
truncate table product_dim;
truncate table order_dim;
-- 序列初始化
alter sequence customer_dim_customer_sk_seq restart with 1;
alter sequence product_dim_product_sk_seq restart with 1;
alter sequence order_dim_order_sk_seq restart with 1;
-- 装载customer_dim维度表
insert into customer_dim (customer_number,customer_name,customer_street_address,customer_zip_code,customer_city,customer_state,version,effective_dt,expiry_dt)
select customer_number,customer_name,customer_street_address,customer_zip_code,customer_city,customer_state,1,'2021-06-01','2200-01-01'
from customer;
-- 装载product_dim维度表
insert into product_dim (product_code,product_name,product_category,version,effective_dt,expiry_dt)
select product_code,product_name,product_category,1,'2021-06-01','2200-01-01'
from product;
-- 装载order_dim维度表
insert into order_dim (order_number,version,effective_dt,expiry_dt)
select order_number,1,'2021-06-01','2200-01-01'
from sales_order;
-- 装载sales_order_fact事实表
insert into sales_order_fact(order_sk,customer_sk,product_sk,order_date_sk,year_month,order_amount)
select order_sk, customer_sk, product_sk, date_sk, to_char(order_date, 'YYYYMM')::int, order_amount
from rds.sales_order a, order_dim b, customer_dim c, product_dim d, date_dim e
where a.order_number = b.order_number
and a.customer_number = c.customer_number
and a.product_code = d.product_code
and date(a.order_date) = e.date;
-- 分析tds模式的表
analyze customer_dim;
analyze product_dim;
analyze order_dim;
analyze sales_order_fact;装载前清空表,以及重新初始化序列的目的是为了可重复执行初始装载SQL脚本。因为数据已经预生成,初始装载SQL不用处理date_dim维度表。其他维度表数据的初始版本号为1,生效时间与过期时间设置为统一值,生效时间早于最早订单生成时间(最小sales_order.order_date值),过期时间设置为一个足够大的日期值。先装载所有维度表,再装载事实表。装载大量数据后执行分析表操作是一个好习惯,也是Greenplum的推荐做法,有助于查询优化器制定最佳执行计划,提高查询性能。
3. 验证数据
初始装载完成后,可以使用下面的查询验证数据正确性。
select order_number,customer_name,product_name,date,
order_amount amount
from sales_order_fact a, customer_dim b, product_dim c,
order_dim d, date_dim e
where a.customer_sk = b.customer_sk
and a.product_sk = c.product_sk
and a.order_sk = d.order_sk
and a.order_date_sk = e.date_sk
order by order_number; 注意,本例使用序列实现的代理键与业务主键不同序,即便在插入时使用select ... order by也无济于事:
dw=> select order_sk, order_number from order_dim order by order_number limit 5;
order_sk | order_number
----------+--------------
19 | 1
50 | 2
29 | 3
31 | 4
30 | 5
(5 rows)单行insert可以保证顺序递增,例如6.1.3小节的fn_populate_date函数中使用的insert语句。只有当一条insert语句插入多条记录时(如这里使用的insert ... select语句)才有此问题。这对于数据仓库来说并无大碍,想想UUID主键!我们只要切记Greenplum的序列只保证唯一性,不保证顺序性,因此应用逻辑不要依赖代理键的顺序。如果一定要保持初始装载的代理键与业务主键同序,只要写个函数或匿名块,用游标按业务主键顺序遍历源表记录,在循环中逐条insert目标表即可。例如:
do $$declare
r_mycur record;
begin
--在读入游标时最好先对值进行排序,保证循环调用的顺序
for r_mycur in select order_number from sales_order order by order_number
loop
--在游标内循环执行插入
insert into order_dim (order_number,version,effective_dt,expiry_dt)
values (r_mycur.order_number,1,'2021-06-01','2200-01-01');
end loop;
end$$;有得必有失,这种方案的缺点是性能差。上一篇最后我们做过测试,本环境中Greenplum每秒约能执行1500条左右的单行DML,比批处理方式慢得多。
6.3 实时装载
初始装载只在开始数据仓库使用前执行一次,而实时装载一般都是增量的,并且需要捕获并且记录数据的变化历史。本节说明执行实时装载的步骤,包括识别源数据与装载类型、配置增量数据同步、创建Greenplum的rule、启动和测试实时装载过程。
6.3.1 识别数据源与装载类型
实时装载首先要识别数据仓库的每个事实表和每个维度表用到的并且是可用的源数据,然后决定适合装载的抽取模式和维度历史装载类型。表6-2汇总了本示例的这些信息。
| 数据源 | RDS模式 | TDS模式 | 抽取模式 | 维度历史装载类型 |
| customer | customer | customer_dim | 实时增量 | address列上SCD2,name列上SCD1 |
| product | product | product_dim | 实时增量 | 所有属性均为SCD2 |
| sales_order | sales_order | order_dim | 实时增量 | 唯一订单号 |
| sales_order_fact | 实时增量 | N/A | ||
| N/A | N/A | date_dim | N/A | 预装载 |
表6-2 销售订单实时装载类型
在捕获数据变化时,需要使用维度表的当前版本数据与从业务数据库最新抽取来的数据做比较。实现方式是在Greenplum中创建rule对象,用于自动处理数据变化。这种设计可以保留全部数据变化的历史,因为逻辑都在rule内部定义好并自动触发。
事实表需要引用维度表的代理键,而且不一定是引用当前版本的代理键。比如有些迟到的事实,就必须找到事实发生时的维度版本。因此一个维度的所有版本区间应该构成一个连续且互斥时间范围,每个事实数据都能对应维度的唯一版本。实现方式是在利用维度表中的版本生效时间和版本过期时间两列,任何一个版本的有效期是一个“左闭右开”的区间,也就是说该版本包含生效时间,但不包含过期时间。因为ETL粒度为实时,所有数据变化都会被记录。
6.3.2 配置增量数据同步
这一步要做的是将MySQL数据实时同步到rds模式的表中。我们已经按上一篇所述配置好了Kafka、Canal Server和Canal Adapter,现在只需增加Canal Adapter的表映射配置,为每个同步表生成一个yml文件。本例初始需要在/home/mysql/canal_113/adapter/conf/rdb目录下创建三个表的配置文件:
customer.yml
product.yml
sales_order.ymlcustomer.yml文件内容如下:
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: Greenplum
concurrent: true
dbMapping:
database: source
table: customer
targetTable: rds.customer
targetPk:
customer_number: customer_number
# mapAll: true
targetColumns:
customer_number: customer_number
customer_name: customer_name
customer_street_address: customer_street_address
customer_zip_code: customer_zip_code
customer_city: customer_city
customer_state: customer_state
commitBatch: 30000 # 批量提交的大小其他两个表映射配置文件类似。关于各个配置项的含义和作用已经在上篇详细说明,不再赘述。
6.3.3 在Greenplum创建rule
1. 关于rule
Canal可以实时获取、解析、重放MySQL binlog,整个过程自动执行,对用户完全透明。要实现数据的实时装载,同样也需要有个程序能实时捕获数据变化,并自动触发执行ETL逻辑。在数据库中,能做这件事的首先一定是想到触发器。不幸的是,Greenplum在设计时将触发器阉割了,这应该是出于性能的考虑,因为触发器的行级触发算法(for each row)对于海量数据来说绝对是灾难性的。万幸的是,Greenplum从PostgreSQL继承的rule对象能提供类似于触发器的功能,而且是以执行附加的语句为代价(for each statement),相对具有更好的性能和可控制性。触发器能实现的,基本上都可以用rule取而代之。
Greenplum数据库规则系统允许定义对数据库表执行插入、更新或删除时所触发的操作。当在给定表上的执行给定命令时,规则会导致运行附加或替换命令。规则也可用于实现SQL视图,但是自动更新的视图通常会优于显式规则。规则本质上是命令转换机制或命令宏,而不像触发器那样对每个物理行独立操作,认识到这点非常重要。附加或替换发生在原命令开始执行之前。
创建一个rule的语法如下:
CREATE [OR REPLACE] RULE name AS ON event
TO table_name [WHERE condition]
DO [ALSO | INSTEAD] NOTHING | command | (command; command
...) 参数说明:
- name:要创建的规则的名称,同一表上规则的名称必须唯一。同一表和同一事件类型上的多个规则按字母名称顺序应用。
- event:触发事件,可以是select、insert,update,delete之一。
- table_name:应用规则的表或视图的名称。
- condition:任何返回布尔值SQL条件表达式。条件表达式中只能引用new或old,不能引用其他任何表,也不能包含聚合函数。new和old是指table_name表的新值和旧值。insert和update规则中的new有效,以引用正在插入或更新的新行。old在update和delete规则中有效,以引用正在更新或删除的现有行。
- instead:指示用另一个命令替换而不是执行原始命令,instead nothing导致原命令根本不运行。
- also:指示除原始命令外,还应运行某些命令。如果既不指定also也不指定instead,则默认值
以上是关于Greenplum 实时数据仓库实践——实时数据装载的主要内容,如果未能解决你的问题,请参考以下文章
Greenplum 实时数据仓库实践——Greenplum与数据仓库