python数据结构之排序
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据结构之排序相关的知识,希望对你有一定的参考价值。
💘上次学习了搜索的算法后,给我印象最深的当然就是hash搜索,学习完搜索之后最为重要的就是排序算法了,对以往内容感兴趣的同学可以查看以下内容👇:
- python数据类型: python数据结构之数据类型.
- python的输入输出: python数据结构之输入输出、控制和异常.
- python数据结构之面向对象: python数据结构之面向对象.
- python数据结构之算法分析: python数据结构之算法分析.
- python数据结构之栈、队列和双端队列: python数据结构之栈、队列和双端队列.
- python数据结构之递归: python数据结构之递归.
- python数据结构之搜索: python数据结构之搜索.
👊接下来的内容将介绍几种经典的排序算法,并用python实现,并结合算法的特点对这几种算法进行分析。
1.排序的概念
排序是指将集合中的元素按某种顺序排列的过程。比如,一个单词列表可以按字母表或长度排序;一个城市列表可以按人口、面积或邮编排序。
排序算法有很多,对它们的分析也已经很透彻了。这说明,排序是计算机科学中的一个重要的研究领域。给大量元素排序可能消耗大量的计算资源。与搜索算法类似,排序算法的效率与待处理元素的数目相关。对于小型集合,采用复杂的排序算法可能得不偿失;对于大型集合,需要尽可能充分地利用各种改善措施。
1.1 冒泡排序
冒泡排序:多次遍历列表。它比较相邻的元素,将不合顺序的交换。每一轮遍历都将下一个最大值放到正确的位置上。本质上,每个元素通过“冒泡”找到自己所属的位置。这就是冒泡的由来吧。
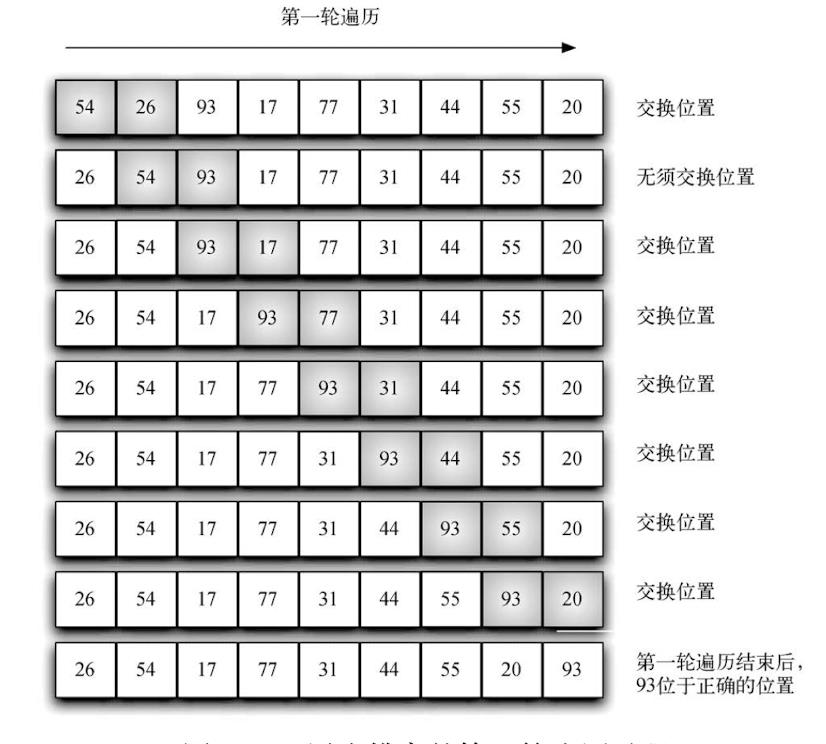
在第一轮过程中总共会有n个元算,需要进行n-1次比较,在第二轮比较的过程中,还剩 n–1 个元素需要排列,也就是说要比较 n–2 对。既然每一轮都将下一个最大的元素放到正确位置上,那么需要遍历的轮数就是 n–1。 完成 n–1 轮后,最小的元素必然在正确位置上,因此不必再做处理。
python实现
def bubbleSort(test):
for i in range(len(test),0,-1):
for j in range(0,i-1):
if test[j]>test[j+1]:
tmp=test[j]
test[j]=test[j+1]
test[j+1]=tmp
return test
冒泡排序通常被认为是效率最低的排序算法,因为在确定最终的位置前必须交换元素。“多余”的交换操作代价很大。不过,由于冒泡排序要遍历列表中未排序的部分,因此它具有其他排序算法没有的用途。特别是,如果在一轮遍历中没有发生元素交换,就可以确定列表已经有序。 可以修改冒泡排序函数,使其在遇到这种情况时提前终止。对于只需要遍历几次的列表,冒泡排序可能有优势,因为它能判断出有序列表并终止排序过程。
改进的冒泡排序
def bubbleSort2(test):
succe=True#判断是否以及排序完成
leng=len(test)
while leng>1 and succe:
succe=False
for j in range(0,leng-1):
if test[j]>test[j+1]:
succe=True#如果排序成功succe这个变量就是False,直接跳出
tmp=test[j]
test[j]=test[j+1]
test[j+1]=tmp
leng=leng-1
return test
1.2 选择排序
选择排序:在冒泡排序的基础上做了改进,每次遍历列表时只做一次交换。要实现这一点,选择排序在每次遍历时寻找最大值,并在遍历完之后将它放到正确位置上。和冒泡排序一样,第一次遍历后,最大的元素就位;第二次遍历后,第二大的元素就位,依此类推。若给 n 个元素排序需要遍历 n–1 轮,这是因为最后一个元素要到 n–1 轮遍历后才就位。

python实现
def selectSort(test):
for i in range(len(test)-1,0,-1):#这里控制着比较次数
left=0
for j in range(0,i+1):#这里的i+1是方便比较所有元素。
if test[left]<=test[j]:
left=j
tmp=test[i]#每次的i都是最后一个元素。
test[i]=test[left]
test[left]=tmp
return test
可以看出,选择排序算法和冒泡排序算法的比较次数相同,所以时间复杂度也是O(n^2)。但是,由于减少了交换次数,因此选择排序算法通常更快.
1.3 插入排序
插入排序:在列表较低的一端维护一个有序的子列表,并逐个将每个新元素“插入”这个子列表中。
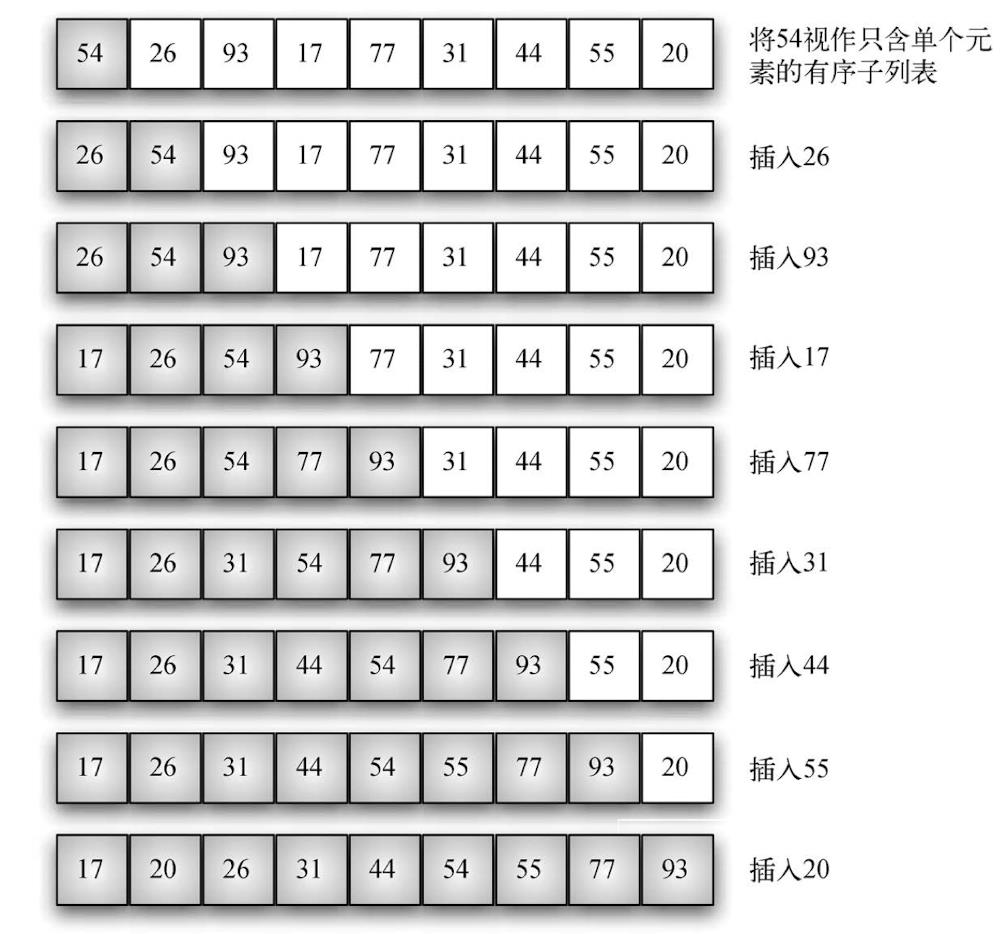
python实现
def insertSort(test):
for i in range(1,len(test)):#选取元素进行比较
data=test[i]
pos=i
while pos>0 and data<test[pos-1]:#比较元素,换位置
test[pos]=test[pos-1]
pos=pos-1
test[pos]=data
return test
在给 n 个元素排序时,插入排序算法需要遍历 n–1 轮。循环从位置 1 开始,直到位置 n–1 结束,这些元素都需要被插入到有序子列表。在最坏情况下,插入排序算法的比较次数是前 n–1 个整数之和,对应的时间复杂度是O(n^2)。在最好情况下(列表已经是有序的),每一轮只需比较一次。
1.4 希尔排序
希尔排序:又称‘递减增量排序’,它对插入排序进行了改进,将列表分成数个子列表,并对每一个子列表应用插入排序。如何切分列表是希尔排序的关键——并不是连续切分,而是使用增量 i(有时称作步长)选取所有间隔为 i 的元素组成子列表。
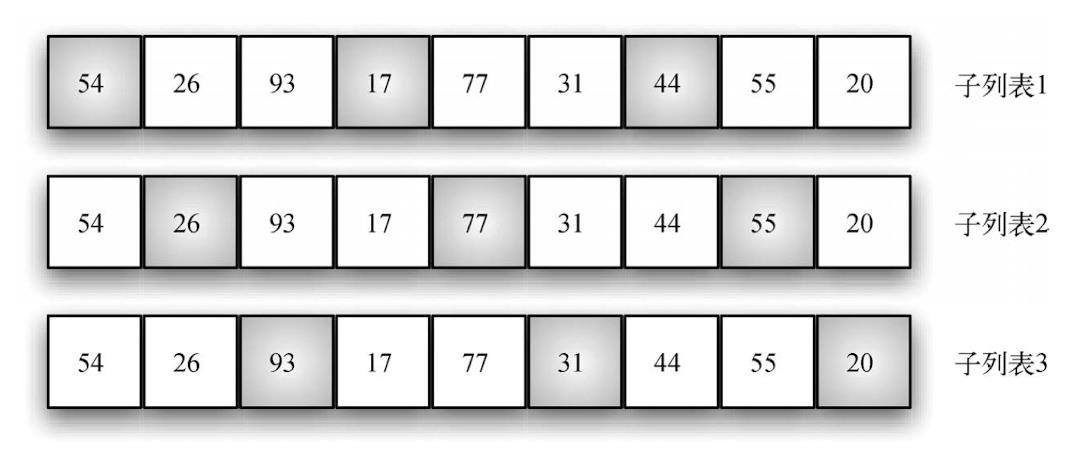
说一下希尔排序的一般步骤:
- 一一般情况下,我们采用n/2作为第一次排序的步长,如:

- 第二次就是n/4的步长作为排序。
- 等到n/2I=1时,结束,这个时候步长为1,也就是我们讲的插入排序。
python实现
def gapInsertionSort(test,start,gap):#这里是一个带步长gap的插入排序
for i in range(start,len(test),gap):
data=test[i]
pos=i
while pos>=gap and data<test[pos-gap]:
test[pos]=test[pos-gap]
pos=pos-gap
test[pos]=data
return test
def shellSort(alist): #希尔排序是在插入排序的基础上,当间隔为1时就是插入排序
sublistcount = len(alist) // 2 #步长为n/2
while sublistcount > 0:
for startposition in range(sublistcount):
gapInsertionSort(alist, startposition, sublistcount)
print("After increments of size", sublistcount,"The list is", alist)
sublistcount = sublistcount // 2 #每次循步长都减半
可能你会觉得插入排序比希尔排序好,因为希尔排序需要多次的局部插入排序,最后还需要进行一次完整的插入排序,但实际上,列表已经由增量的插入排序做了预处理,所以最后一步插入排序不需要进行多次比较或移动。也就是说,每一轮遍历都生成了“更有序”的列表,这使得最后一步非常高效。最后希尔排序的时间复杂度介于O(n)和O(n2)之间。
1.5 归并排序
归并排序:这是递归算法,每次将一个列表一分为二。如果列表为空或只有一个元素,那么从定义上来说它就是有序的(基本情况)。如果列表不止一个元素,就将列表一分为二,并对两部分都递归调用归并排序。当两部分都有序后,就进行归并这一基本操作。
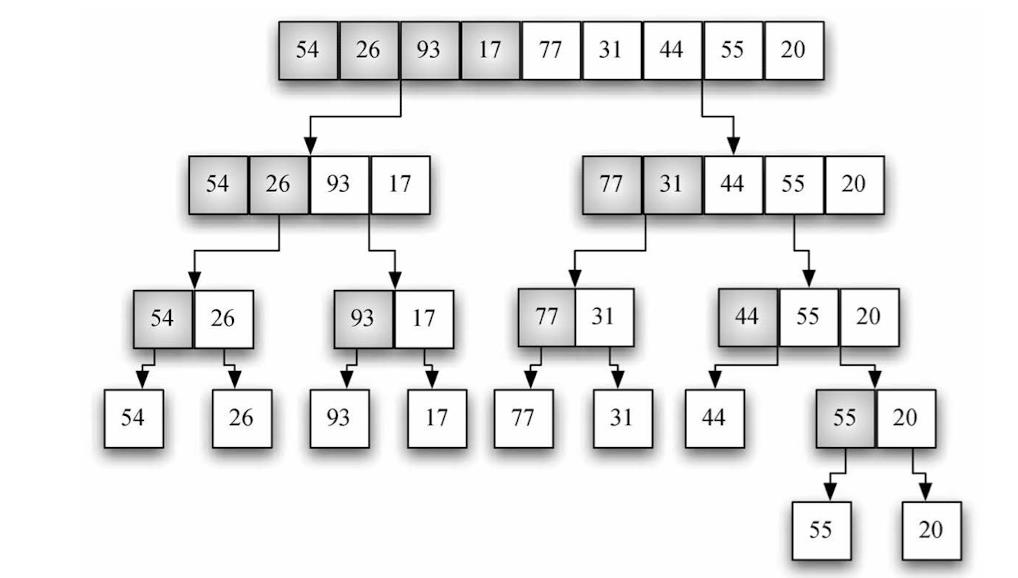
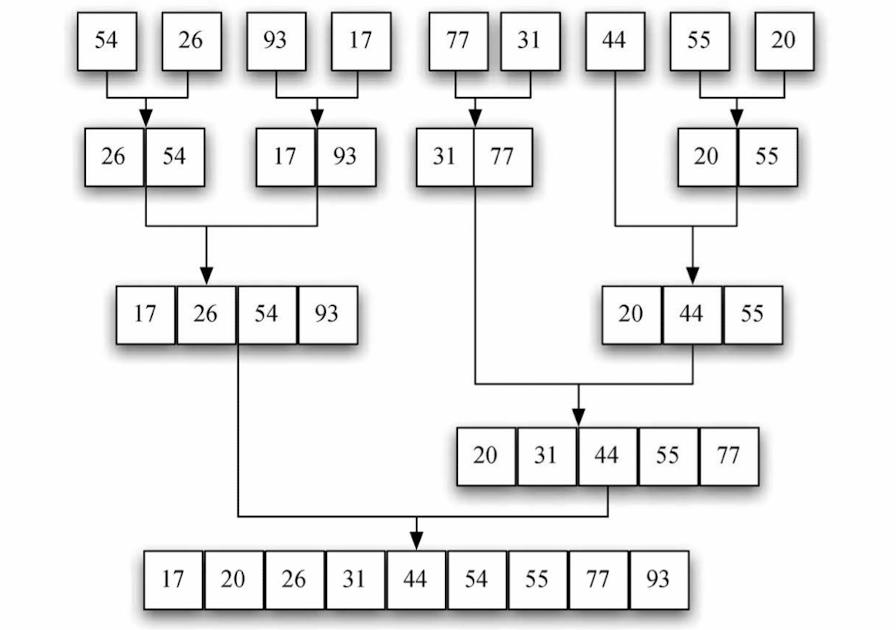
python实现
def mergeSort(alist):
print("Splitting ", alist)
if len(alist) > 1:
mid = len(alist) // 2
lefthalf = alist[:mid]
righthalf = alist[mid:]
mergeSort(lefthalf)#左边递归
mergeSort(righthalf)#右边递归
i = 0
j = 0
k = 0
while i < len(lefthalf) and j < len(righthalf):#左右比较
if lefthalf[i] < righthalf[j]:
alist[k] = lefthalf[i]
i = i + 1
else:
alist[k] = righthalf[j]
j = j + 1
k = k + 1
while i < len(lefthalf):#如果左边剩余多,进行填充
alist[k] = lefthalf[i]
i = i + 1
k = k + 1
while j < len(righthalf):#如果右边剩余多,进行填充
alist[k] = righthalf[j]
j = j + 1
k = k + 1
print("Merging ", alist)
分析归并排序时,要考虑它的两个独立的构成部分。首先,列表被一分为二。在学习二分搜索时已经算过,当列表的长度为 n 时,能切分 O ( l o g 2 n ) O(log_2 n) O(log2n)次。第二个处理过程是归并。列表中的每个元素最终都得到处理,并被放到有序列表中。所以,得到长度为 n 的列表需要进行 n 次操作。由此可知,需要进行 l o g 2 n log_2 n log2n 次拆分,每一次需要进行 n 次操作,所以一共是 n l o g 2 n nlog_2 n nlog2n次操作。 也就是说,归并排序算法的时间复杂度为 O ( n l o g 2 n ) O(nlog_2 n) O(nlog2n)
1.6 快速排序
快速排序:该算法首先选出一个基准值。尽管有很多种选法,但为简单起见,一般选取列表中的第一个元素。基准值的作用是帮助切分列表。在最终的有序列表中,基准值的位置通常被称作分割点,算法在分割点切分列表,以进行对快速排序的子调用。

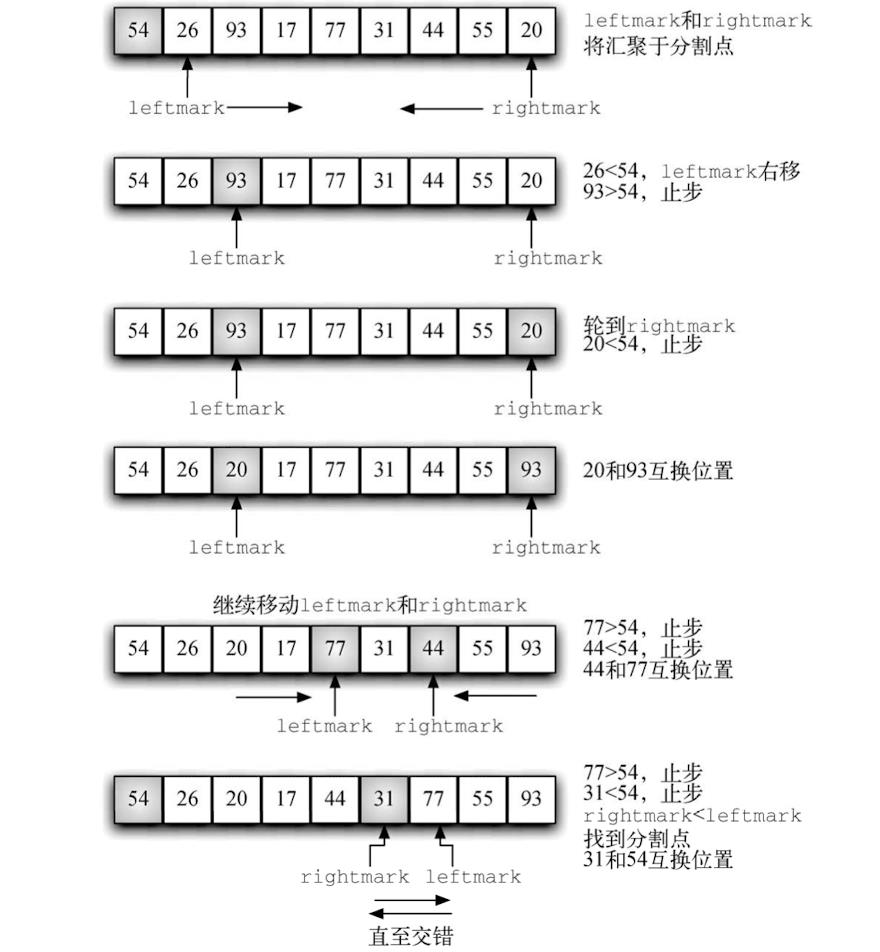
- 分区操作首先找到两个坐标——leftmark 和 rightmark——它们分别位于列表剩余元素 的开头和末尾,如上图所示。分区的目的是根据待排序元素与基准值的相对大小将它们放到正确的一边,同时逐渐逼近分割点。
- 首先加大 leftmark,直到遇到一个大于基准值的元素。然后减小 rightmark,直到遇到 一个小于基准值的元素。这样一来,就找到两个与最终的分割点错序的元素。本例中,这两个元素就是 93 和 20。互换这两个元素的位置,然后重复上述过程。
- 当 rightmark 小于 leftmark 时,过程终止。此时,rightmark 的位置就是分割点。将基准值与当前位于分割点的元素互换,即可使基准值位于正确位置,如下图 。分割点左边的所有元素都小于基准值,右边的所有元素都大于基准值。因此,可以在分割点处将列表一分 为二,并针对左右两部分递归调用快速排序函数。
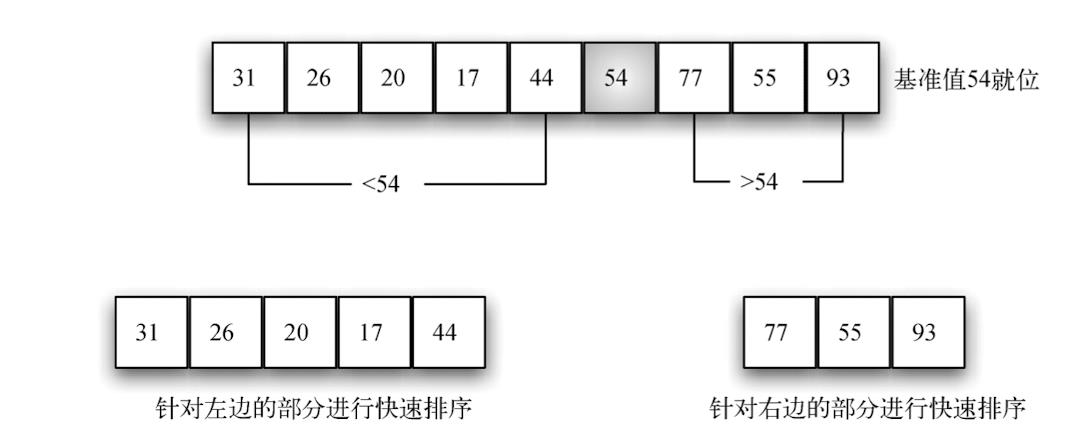
python实现
def quickSort(array, start, end):
if start >= end:
return
mid_data=array[start]
left=start
right=end
while left < right:
while array[right] >= mid_data and left < right:
right -= 1
array[left] = array[right]
while array[left] < mid_data and left < right:
left += 1
array[right] = array[left]
array[left] = mid_data
quickSort(array, start, left-1)
quickSort(array, left+1, end)
对于快速排序,对于长度为 n 的列表,如果分区操作总是发生在列表的中部,就会切分 logn 次。为了找到分割点,n 个元素都要与基准值比较。所以,时间复杂度是
n
l
o
g
2
n
nlog_2 n
nlog2n。另外,快速排序算法不需要像归并排序算法那样使用额外的存储空间。
不幸的是,最坏情况下,分割点不在列表的中部,而是偏向某一端,这会导致切分不均匀,在这种情况下,含有 n 个元素的列表可能被分成一个不含元素的列表与一个含有 n–1 个元素的列 表。然后,含有 n–1 个元素的列表可能会被分成不含元素的列表与一个含有 n–2 个元素的列表,依此类,这会导致时间复杂度变为O(n2),因为还要加上递归的开销。
2.参考资料
《python数据结构与算法》
《大话数据结构》
以上是关于python数据结构之排序的主要内容,如果未能解决你的问题,请参考以下文章