用深度学习做命名实体识别-BERT介绍
Posted anai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用深度学习做命名实体识别-BERT介绍相关的知识,希望对你有一定的参考价值。
什么是BERT?
BERT,全称是Bidirectional Encoder Representations from Transformers。可以理解为一种以Transformers为主要框架的双向编码表征模型。所以要想理解BERT的原理,还需要先理解什么是Transformers。
Transformers简单来说是一个将一组序列转换成另一组序列的黑盒子,这个黑盒子内部由编码器和解码器组成,编码器负责编码输入序列,然后解码器负责将编码器的输出转换为另一组序列。具体可以参考这篇文章《想研究BERT模型?先看看这篇文章吧!》
这里需要注意的是,BERT使用的Transformers中在表示位置信息时,没有使用Positional Encoding,而是使用了Positional Embedding,所以位置信息是训练出来的,并且为了让模型能同时考虑到单词左边和右边的上下文信息,BERT使用了双向Transformers的架构。而由于位置信息是采用的embedding的方式,所以对序列的最大长度就有所限制了,受限于训练时最大序列的长度,这里BERT预训练模型的最大序列长度是512.也就是说如果训练样本超过了长度,就需要采用截断或者其他方式以保证序列的长度在512以内。
BERT能做什么?
- 文本推理
给定一对句子,预测第二个句子和第一个句子的关系:蕴含、矛盾、中性。 - 问答
给定问题和短文,从短文预测出对应span作为答案。 - 文本分类
比如对电影评论做情感预测。 - 文本相似度匹配
输入两个句子,计算语义相似度。 - 命名实体识别
给定一个句子,输出句子中特定的实体,比如人名、地址、时间等。
怎么使用BERT?
BERT有2种用法:
feature-based
直接使用BERT预训练模型提取出文本序列的特征向量。比如文本相似度匹配。fine-tuning
在预训练模型层上添加新的网络;冻结预训练模型的所有层,训练完成后,放开预训练模型的所有层,联合训练解冻的部分和添加的部分。比如文本分类、命名实体识别等。
为什么BERT能做到这些?
BERT在训练的时候采用了无监督的方式,其主要采用2种策略来得到对序列的表征。
MLM
为了训练一个深度双向表征,作者简单的随机mask一些百分比的输入tokens,然后预测那些被mask掉的tokens。这一步称为“masked LM”(MLM),在一些文献中,被称为完型填空任务(Cloze task)。mask掉的tokens对应的最后的隐藏层向量喂给一个输出softmax,像在标准的LM中一样。在实验中,作者为每个序列随机mask掉了15%的 tokens。尽管这允许作者获得双向预训练模型,其带来的负面影响是在预训练和微调模型之间创造了不匹配,因为[MASK]符号不会出现在微调阶段。所以要想办法让那些被mask掉的词的原本的表征也被模型学习到,所以这里作者采用了一些策略:
假设原句子是“my dog is hairy”,作者在3.1节 Task1中提到,会随机选择句子中15%的tokens位置进行mask,假设这里随机选到了第四个token位置要被mask掉,也就是对hairy进行mask,那么mask的过程可以描述如下:
- 80% 的时间:用[MASK]替换目标单词,例如:my dog is hairy --> my dog is [MASK] 。
- 10% 的时间:用随机的单词替换目标单词,例如:my dog is hairy --> my dog is apple 。
- 10% 的时间:不改变目标单词,例如:my dog is hairy --> my dog is hairy 。 (这样做的目的是使表征偏向于实际观察到的单词。)
上面的过程,需要结合训练过程的epochs来理解,每个epoch表示学完了一遍所有的样本,所以每个样本在多个epochs过程中是会重复输入到模型中的,知道了这个概念,上面的80%,10%,10%就好理解了,也就是说在某个样本每次喂给模型的时候,用[MASK]替换目标单词的概率是80%;用随机的单词替换目标单词的概率是10%;不改变目标单词的概率是10%。
有的介绍BERT的文章中,讲解MLM过程的时候,将这里的80%,10%,10%解释成替换原句子被随机选中的15%的tokens中的80%用[MASK]替换目标单词,10%用随机的单词替换目标单词,10%不改变目标单词。这个理解是不对的。
然后,作者在论文中谈到了采取上面的mask策略的好处。大致是说采用上面的策略后,Transformer encoder就不知道会让其预测哪个单词,或者说不知道哪个单词会被随机单词给替换掉,那么它就不得不保持每个输入token的一个上下文的表征分布(a distributional contextual representation)。也就是说如果模型学习到了要预测的单词是什么,那么就会丢失对上下文信息的学习,而如果模型训练过程中无法学习到哪个单词会被预测,那么就必须通过学习上下文的信息来判断出需要预测的单词,这样的模型才具有对句子的特征表示能力。另外,由于随机替换相对句子中所有tokens的发生概率只有1.5%(即15%的10%),所以并不会影响到模型的语言理解能力。
NSP
许多下游任务,比如问答,自然语言推理等,需要基于对两个句子之间的关系的理解,而这种关系不能直接通过语言建模来获取到。为了训练一个可以理解句子间关系的模型,作者为一个二分类的下一个句子预测任务进行了预训练,这些句子对可以从任何单语言的语料中获取到。特别是,当为每个预测样例选择一个句子对A和B,50%的时间B是A后面的下一个句子(标记为IsNext), 50%的时间B是语料库中的一个随机句子(标记为NotNext)。图1中,C用来输出下一个句子的标签(NSP)。
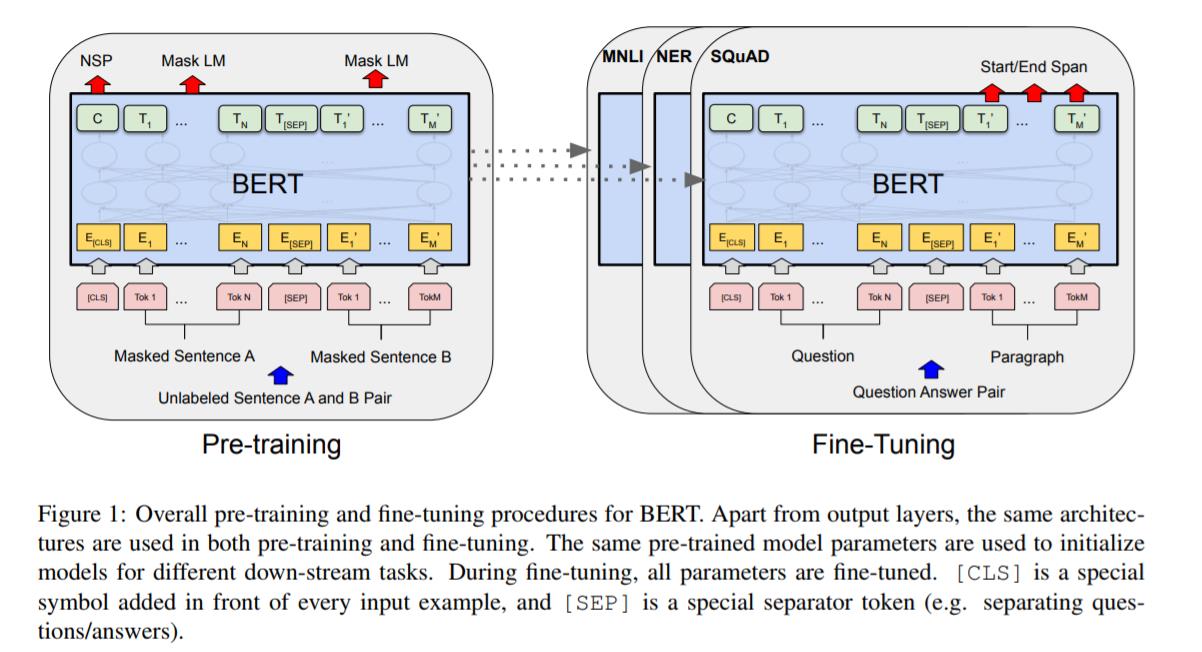
”下个句子预测“的任务的例子:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext还有哪些模型可以做到这些,它们和BERT的区别是什么?
论文中作者提到了另外的两个模型,分别是OpenAI GPT和ELMo。
图3展示了这3个模型架构的对比:
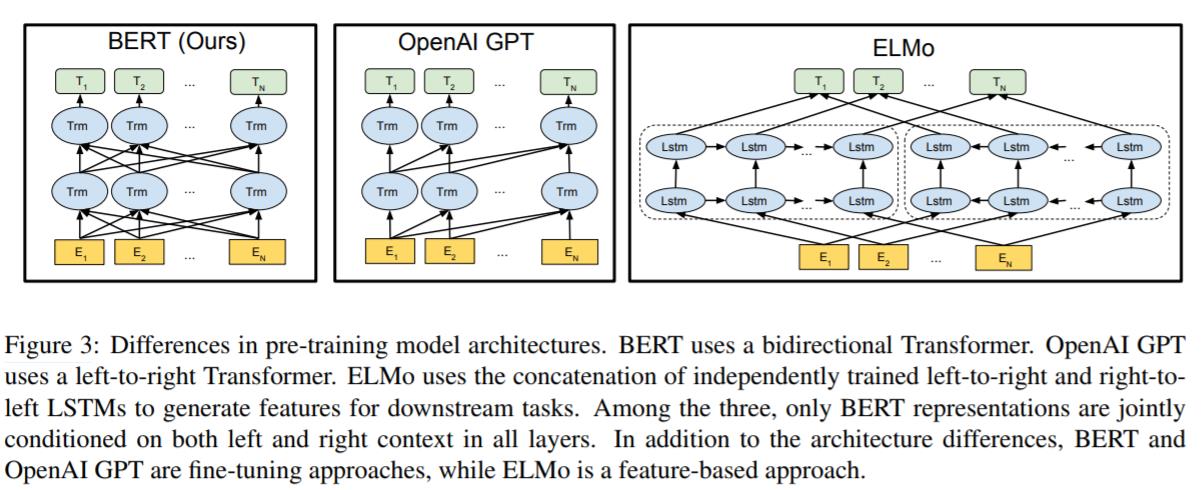
- BERT使用了双向的Transformer架构,预训练阶段使用了MLM和NSP。
- OpenAI GPT使用了left-to-right的Transformer。
- ELMo分别使用了left-to-right和right-to-left进行独立训练,然后将输出拼接起来,为下游任务提供序列特征。
上面的三个模型架构中,只有BERT模型的表征在每一层都联合考虑到了左边和右边的上下文信息。另外,除了架构不同,还要说明的一点是:BERT和OpenAI GPT是基于fine-tuning的方法,而ELMo是基于feature-based的方法。
更多细节
请阅读原论文,或者参考笔者的这篇文章《BERT论文解读》。
以上是关于用深度学习做命名实体识别-BERT介绍的主要内容,如果未能解决你的问题,请参考以下文章