[Python人工智能] 三十二.Bert模型 Keras-bert基本用法及预训练模型
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python人工智能] 三十二.Bert模型 Keras-bert基本用法及预训练模型相关的知识,希望对你有一定的参考价值。
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章结合文本挖掘介绍微博情感分类知识,包括数据预处理、机器学习和深度学习的情感分类。这篇文章将开启新的内容——Bert,首先介绍Keras-bert库安装及基础用法,为后续文本分类、命名实体识别提供帮助。基础性文章,希望对您有所帮助!
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\\DTC\\SVM\\KNN\\NB\\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
- [Python人工智能] 三十二.Bert模型 (1)Keras-bert基本用法及预训练模型
一.Bert模型引入
Bert模型的原理知识将在后面的文章介绍,主要结合结合谷歌论文和模型优势讲解。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- https://arxiv.org/pdf/1810.04805.pdf
- https://github.com/google-research/bert

BERT(Bidirectional Encoder Representation from Transformers)是一个预训练的语言表征模型,是由谷歌AI团队在2018年提出。该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩,并且在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
Bert强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。其模型框架图如下所示,后面的文章再详细介绍,这里仅作引入,推荐读者阅读原文。
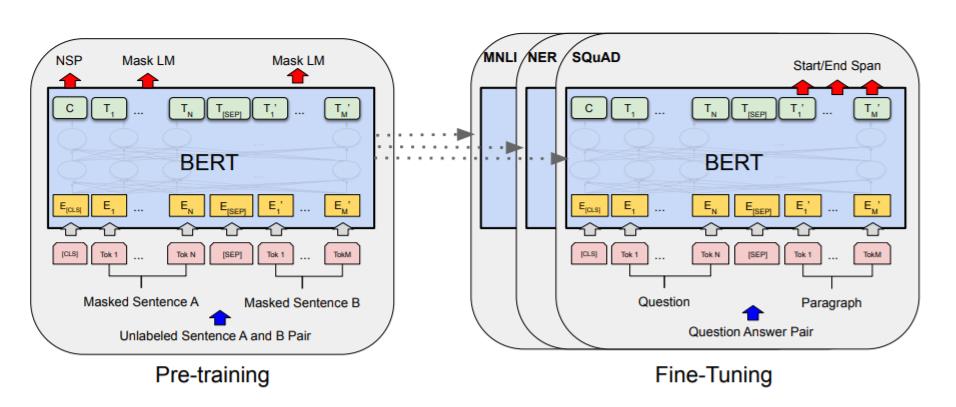
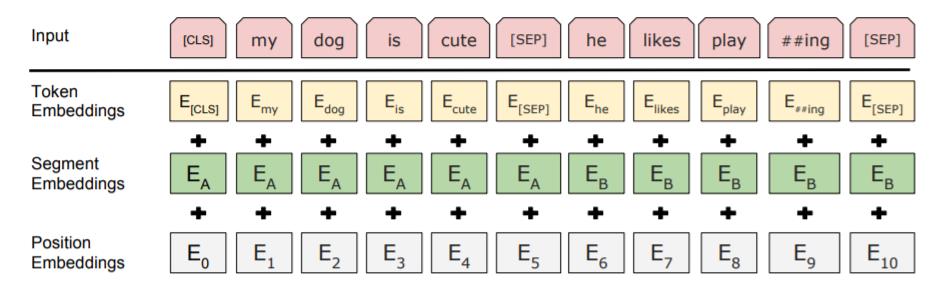
二.keras-bert基础知识
Bert安装常用的包括keras-bert和bert4keras等,这里以keras-bert为例进行简单介绍。
1.安装
keras_bert是CyberZHG大佬用Keras封装好的Bert模型,可以直接调用官方发布的预训练权重,方便大家实现想要的功能。

Github代码地址如下:
在Pypi中提供了下载信息。
安装主要调用PIP实现,具体如下:
- pip install keras-bert

keras-bert扩展包支持的环境(requirements.txt):
- numpy
- Keras>=2.4.3
- keras-transformer>=0.39.0
bert4keras是封装好了Keras版的Bert,可以直接调用官方发布的预训练权重,后文再详细介绍。
- https://github.com/bojone/bert4keras
2.Tokenizer
在keras-bert里面,我们使用Tokenizer类来将文本拆分成字并生成相应的id。通过定义字典存放token和id的映射。其对应的源码如下,可以看到:
- TOKEN_CLS:the token represents classification
- TOKEN_SEP:the token represents separator
- TOKEN_UNK:the token represents unknown token
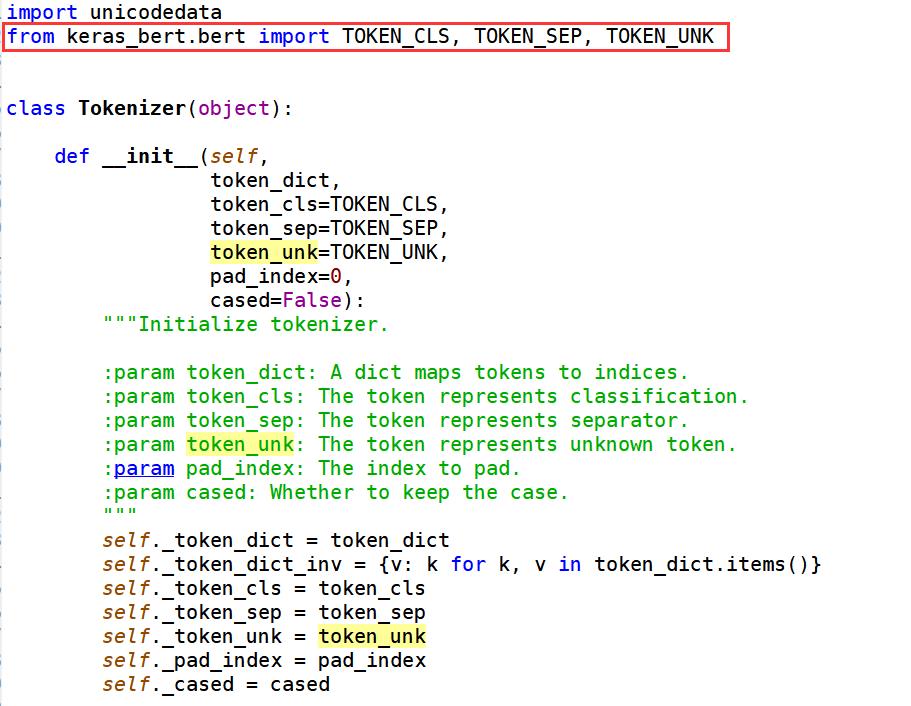
在下面的示例中,如果文本拆分出来的字在字典不存在,它的id会是 5,对应unknown(UNK)。
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 23 15:35:48 2021
@author: xiuzhang
"""
from keras_bert import Tokenizer
token_dict =
'[CLS]': 0,
'[SEP]': 1,
'un': 2,
'##aff': 3,
'##able': 4,
'[UNK]': 5,
#分词器-Tokenizer
tokenizer = Tokenizer(token_dict)
print(tokenizer.tokenize('unaffable'))
#拆分单词
indices, segments = tokenizer.encode('unaffable')
print(indices) #字对应索引
print(segments) #索引对应位置上字属于第一句话还是第二句话
print(tokenizer.tokenize(first='unaffable', second='钢'))
indices, segments = tokenizer.encode(first='unaffable', second='钢', max_len=10)
print(indices)
print(segments)
运行结果如下图所示:
- 首先将“unaffable”拆分成 [’[CLS]’, ‘un’, ‘##aff’, ‘##able’, ‘[SEP]’]
- 接下来输出对应的索引和索引位置对应字属于第一句话或第二句话,因为只有一句话,所以segments都是0
- 接下来两句话进行分词,同时如果拆分完的字不超过max_len,则用0补充

注意:安装keras-bert可能会因为keras、tensorflow版本(tf2)问题,报各种错误,建议大家谷歌解决,版本兼容确实是个问题。
ImportError: cannot import name ‘get_config’ from tensorflow.python.eager.context import get_config
3.Train & Use
模型训练和使用的案例代码如下所示:
- get_model
- fit_generator
- compile_model
- gen_batch_inputs
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 23 19:22:23 2021
@author: xiuzhang
"""
import keras
from keras_bert import get_base_dict, get_model, compile_model, gen_batch_inputs
#输入样本:toy玩具
sentence_pairs = [
[['all', 'work', 'and', 'no', 'play'], ['makes', 'jack', 'a', 'dull', 'boy']],
[['from', 'the', 'day', 'forth'], ['my', 'arm', 'changed']],
[['and', 'a', 'voice', 'echoed'], ['power', 'give', 'me', 'more', 'power']],
]
#构建token词典
token_dict = get_base_dict() # A dict that contains some special tokens
print(token_dict)
for pairs in sentence_pairs:
for token in pairs[0] + pairs[1]:
if token not in token_dict:
token_dict[token] = len(token_dict)
token_list = list(token_dict.keys()) # Used for selecting a random word
print(token_list)
#构建训练模型
model = get_model(
token_num=len(token_dict),
head_num=5,
transformer_num=12,
embed_dim=25,
feed_forward_dim=100,
seq_len=20,
pos_num=20,
dropout_rate=0.05,
)
compile_model(model)
model.summary()
def _generator():
while True:
yield gen_batch_inputs(
sentence_pairs,
token_dict,
token_list,
seq_len=20,
mask_rate=0.3,
swap_sentence_rate=1.0,
)
model.fit_generator(
generator=_generator(),
steps_per_epoch=1000,
epochs=100,
validation_data=_generator(),
validation_steps=100,
callbacks=[
keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
],
)
#使用训练好的模型
inputs, output_layer = get_model(
token_num=len(token_dict),
head_num=5,
transformer_num=12,
embed_dim=25,
feed_forward_dim=100,
seq_len=20,
pos_num=20,
dropout_rate=0.05,
training=False, # The input layers and output layer will be returned if `training` is `False`
trainable=False, # Whether the model is trainable. The default value is the same with `training`
output_layer_num=4, # The number of layers whose outputs will be concatenated as a single output.
# Only available when `training` is `False`.
)
输出结果如下,本文的第三部分和第四部分我们将详细介绍。
- ’’: 0, ‘[UNK]’: 1, ‘[CLS]’: 2, ‘[SEP]’: 3, ‘[MASK]’: 4
- [’’, ‘[UNK]’, ‘[CLS]’, ‘[SEP]’, ‘[MASK]’, ‘all’, ‘work’, ‘and’, ‘no’, ‘play’, ‘makes’, ‘jack’, ‘a’, ‘dull’, ‘boy’, ‘from’, ‘the’, ‘day’, ‘forth’, ‘my’, ‘arm’, ‘changed’, ‘voice’, ‘echoed’, ‘power’, ‘give’, ‘me’, ‘more’]
ValueError: Could not interpret optimizer identifier: <keras_bert.optimizers.warmup_v2.AdamWarmup object>
4.Use Warmup
AdamWarmup优化器(optimizer)主要用于预热(warmup)和衰减(decay)。学习率经过warmpup_steps步后将达到 lr,经过decay_steps步后将衰减到 min_lr。其中,calc_train_steps是辅助函数,用于计算这两个步骤。
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 23 20:51:40 2021
@author: xiuzhang
"""
import numpy as np
from keras_bert import AdamWarmup, calc_train_steps
#生成随机数
train_x = np.random.standard_normal((1024, 100))
print(train_x)
#分批训练
total_steps, warmup_steps = calc_train_steps(
num_example=train_x.shape[0],
batch_size=32,
epochs=10,
warmup_proportion=0.1,
)
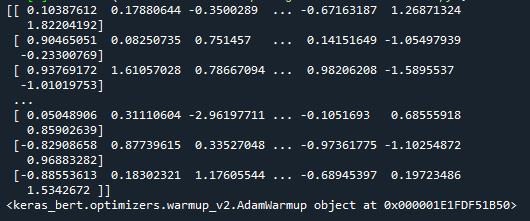
optimizer = AdamWarmup(total_steps, warmup_steps, lr=1e-3, min_lr=1e-5)
print(optimizer)
输出结果如下图所示:
5.Download Pretrained Checkpoints
该扩展包提供了几个下载路径,并且能够获取检测点的下载和未压缩路径。
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 23 21:00:40 2021
@author: xiuzhang
"""
from keras_bert import get_pretrained, PretrainedList, get_checkpoint_paths
#下载解压数据
model_path = get_pretrained(PretrainedList.multi_cased_base)
paths = get_checkpoint_paths(model_path)
print(paths.config, paths.checkpoint, paths.vocab)
输出结果如下图所示:

6.Extract Features
如果您需要tokens或句子的特征,则可以使用辅助函数extract_embeddings。下面的代码能提取所有的tokens特征。
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 23 21:05:39 2021
@author: xiuzhang
"""
from keras_bert import extract_embeddings
model_path = 'xxx/yyy/uncased_L-12_H-768_A-12'
texts = ['all work and no play', 'makes jack a dull boy~']
embeddings = extract_embeddings(model_path, texts)
该段代码将返回一个与文本长度相同的列表。列表中的每一项都是一个被输入长度截断的 numpy 数组。本例中输出的形状是 (7, 768) 和 (8, 768)。
三.Bert模型预训练语料
该部分我们参考了 “天空是很蓝” 老师的博客,主要通过Bert模型预训练语料。
1.下载语料
首先,我们下载官方预训练模型chinese_L-12_H-768_A-12。Google提供了多种预训练好的Bert模型,有针对不同语言的和不同模型大小的。对于中文模型,我们使用Bert-Base Chinese。
- Bert源代码 : https://github.com/google-research/bert
- Bert预训练模型:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
2.加载预训练模型
接着,撰写代码加载预训练模型。
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 24 00:09:48 2021
@author: xiuzhang
"""
import os
from keras_bert import load_vocabulary
from keras_bert import Tokenizer
from keras_bert import load_trained_model_from_checkpoint
#设置预训练模型的路径
pretrained_path = 'chinese_L-12_H-768_A-12'
config_path = os.path.join(pretrained_path, 'bert_config.json')
checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
vocab_path = os.path.join(pretrained_path, 'vocab.txt')
#构建字典
token_dict = load_vocabulary(vocab_path)
print(token_dict)
print(len(token_dict))
#Tokenization
tokenizer = Tokenizer(token_dict)
print(tokenizer)
#加载预训练模型
model = load_trained_model_from_checkpoint(config_path, checkpoint_path)
print(model)
输出结果如下图所示,可以看到共加载21128个汉字及对应编号。


当我们在AI或Python编写代码学习新知识阶段,建议多使用print打桩输出,由于Python调试没有其他编程语言方便,但个人非常喜欢print打桩输出,既能直观地给出每个阶段输出结果,又能加深我们对每个阶段处理反馈效果的理解,真心推荐初学者。我现在也一直保持着这种习惯,当然熟悉后,或者实际项目中可以将其简略。此外,良好的注释习惯也是非常必要的。
3.特征提取
对自定义语料进行tokenizer处理,并使用预训练模型提取输入文本的特征。
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 24 00:09:48 2021
@author: xiuzhang
"""
import os
from keras_bert import load_vocabulary
from keras_bert import Tokenizer
from keras_bert import load_trained_model_from_checkpoint
import numpy as np
#-------------------------------第一步 加载模型---------------------------------
#设置预训练模型的路径
pretrained_path = 'chinese_L-12_H-768_A-12'
config_path = os.path.join(pretrained_path, 'bert_config.json')
checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
vocab_path = os.path.join(pretrained_path, 'vocab.txt')
#构建字典
token_dict = load_vocabulary(vocab_path)
print(token_dict)
print(len(token_dict))
#Tokenization
tokenizer = Tokenizer(token_dict)
print(tokenizer)
#加载预训练模型
model = load_trained_model_from_checkpoint(config_path, checkpoint_path)
print(model)
#-------------------------------第二步 特征提取---------------------------------
text = '语言模型'
tokens = tokenizer.tokenize(text)
print(tokens)
#['[CLS]', '语', '言', '模', '型', '[SEP]']
indices, segments = tokenizer.encode(first=text, max_len=512)
print(indices[:10])
print(segments[:10])
#提取特征
predicts = model.predict([np.array([indices]), np.array([segments])])[0]
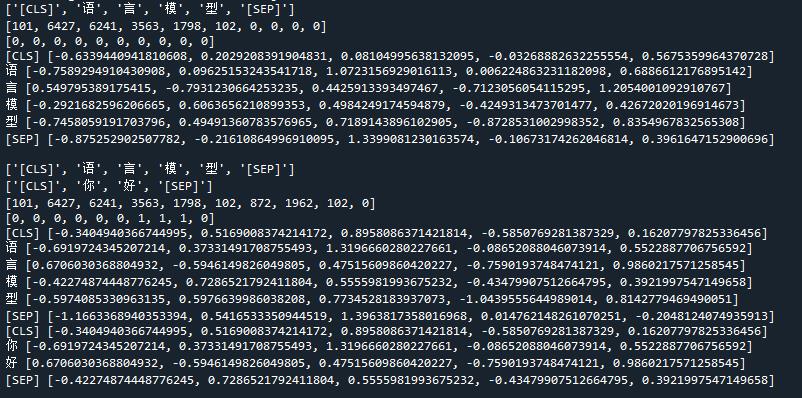
for i, token in enumerate(tokens):
print(token, predicts[i].tolist()[:5])
输出结果如下,可以看到对应的向量。
21128
<keras_bert.tokenizer.Tokenizer object at 0x000002C007A7DDF0>
<keras.engine.functional.Functional object at 0x000002C007A7DD00>
['[CLS]', '语', '言', '模', '型', '[SEP]']
[101, 6427, 6241, 3563, 1798, 102, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[CLS] [-0.6339440941810608, 0.2029208391904831, 0.08104995638132095, -0.03268882632255554, 0.5675359964370728]
语 [-0.7589294910430908, 0.09625153243541718, 1.0723156929016113, 0.006224863231182098, 0.6886612176895142]
言 [0.549795389175415, -0.7931230664253235, 0.4425913393497467, -0.7123056054115295, 1.2054001092910767]
模 [-0.2921682596206665, 0.6063656210899353, 0.4984249174594879, -0.4249313473701477, 0.42672020196914673]
型 [-0.7458059191703796, 0.49491360783576965, 0.7189143896102905, -0.8728531002998352, 0.8354967832565308]
[SEP] [-0.875252902507782, -0.21610864996910095, 1.3399081230163574, -0.10673174262046814, 0.3961647152900696]
同样我们可以对多个句子进行特征提取。
#----------------------------第三步 多句子特征提取------------------------------
text1 = '语言模型'
text2 = "你好"
tokens1 = tokenizer.tokenize(text1)
print(tokens1)
tokens2 = tokenizer.tokenize(text2)
print(tokens2)
indices_new, segments_new = tokenizer.encode(first=text1, second=text2 ,max_len=512)
print(indices_new[:10])
#[101, 6427, 6241, 3563, 1798, 102, 0, 0, 0, 0]
print(segments_new[:10])
#[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
#提取特征
predicts_new = model.predict([np.array([indices_new]), np.array([segments_new])])[0]
for i, token in enumerate(tokens1):
print(token, predicts_new[i].tolist()[:5])
for i, token in enumerate(tokens2):
print(token, predicts_new[i].tolist()[:5])
输出结果如下图所示:
4.字词预测
下面代码是对“数学”进行mask处理,然后成功预测该词语。最终完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 24 00:09:48 2021
@author: xiuzhang
"""
import os
from keras_bert import load_vocabulary
from keras_bert import Tokenizer
from keras_bert import load_trained_model_from_checkpoint
import numpy as np
#-------------------------------第一步 加载模型---------------------------------
#设置预训练模型的路径
pretrained_path = 'chinese_L-12_H-768_A-12'
config_path = os.path.join(pretrained_path, 'bert_config.json')
checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
vocab_path = os.path.join(pretrained_path, 'vocab.txt')
#构建字典
token_dict = load_vocabulary(vocab_path)
print(token_dict)
print(len(token_dict))
#Tokenization
tokenizer