学习--基于深度学习命名实体识别综述
Posted mokoaxx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习--基于深度学习命名实体识别综述相关的知识,希望对你有一定的参考价值。
A Survey on Deep Learning for Named Entity Recognition
https://arxiv.org/abs/1812.09449
命名实体识别(Named Entity Recognition, NER)是指从自由文本中识别出属于预定义类别的文本片段。NER 任务最早由第六届语义理解会议(Message Understanding Conference)提出,当时仅定义一些通用实体类别,如地点、机构、人物等。目前命名实体识别任务已经深入各种垂直领域,如医疗、金融等。将实体归为两类:generic(通用类)和 domain-specific(特定领域类)。
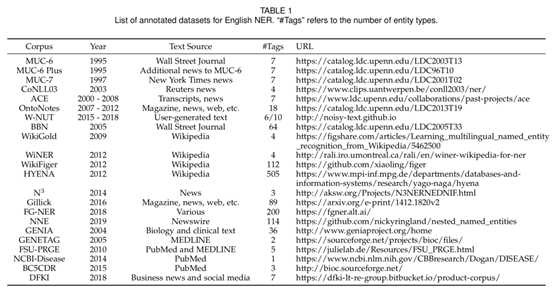
现有公开评测任务使用的 NER 语料库汇总:
学术界和工业界一些 NER 工具汇总:

NER 评测指标 P R F1 分两类,也是比赛和论文中通用评测方式:
1. Exact-match严格匹配,范围与类别都正确。其中 F1 值又可以分为 macro-averaged 和 micro-averaged,前者是按照不同实体类别计算 F1,然后取平均;后者是把所有识别结果合在一起,再计算 F1。这两者的区别在于实体类别数目不均衡,因为通常语料集中类别数量分布不均衡,模型往往对于大类别的实体学习较好。
2. relaxed match 宽松匹配,简言之,可视为实体位置区间部分重叠,或位置正确类别错误的,都记为正确或按照匹配的位置区间大小评测。
序列标注标签方案:1. BIO 2. BIOES B 开始位置、I 中间位置、O 其他类别、S 单字表示一个实体。
四类常用NER方法
1. 规则模板,不需要标注数据,依赖于人工规则;
2. 无监督学习方法,不需要标注数据,依赖于无监督学习算法;
3. 基于特征的有监督学习算法,依赖于特征工程;
4. 深度学习方法。
基于规则方法
1. 特定领域词典,其中还包括同义林词典;2. 句法词汇模板;3. 正则表达式;
论文列出了一些基于规则的 NER 系统:LaSIE-II, NetOwl, Facile, SAR, FASTUS, and LTG。总的来说,当词汇表足够大时,基于规则的方法能够取得不错效果。但总结规则模板花费大量时间,且词汇表规模小,且实体识别结果普遍高精度、低召回。
无监督学习方法
主要基于聚类,根据文本相似度得到不同的簇,表示不同的实体类别组。常用到的特征或者辅助信息有词汇资源、语料统计信息(TF-IDF)、浅层语义信息(分块NP-chunking)等。
基于特征的有监督学习(传统机器学习)
NER 任务可以是看作是 token 级别的多分类任务或序列标注任务,深度学习方法也是依据这两个任务建模。特征工程:word 级别特征(词法特征、词性标注等),词汇特征(维基百科、DBpdia 知识),文档及语料级别特征。机器学习算法:隐马尔可夫模型 HMM、决策树 DT、最大熵模型 MEM、最大熵马尔科夫模型 HEMM、支持向量机 SVM、条件随机场 CRF。
深度学习方法
1. 深度学习优势2. 分布式表示3. 上下文编码结构4. 标签解码结构
11.1 深度学习优势
不能算深度学习做 NER 的优势,深度学习解决其他问题也是这些亮点:1. 强大的向量表示能力;2. 神经网络的强大计算能力;3. DL 从输入到输出的非线性映射能力;4. DL 无需复杂的特征工程,能够学习高维潜在语义信息;5. 端到端的训练方式。
11.2 分布式表示
1. 词级别表示word-level representation:首先 Mikolov 提出的 word2vec(两种框架 CBOW 和 skip-gram),斯坦福的 Glove,Facebook 的 fasttext 和 SENNA。使用这几种词嵌入方式,一些研究工作使用不同语料进行训练,如生物医学领域PubMed、NYT 之类。
2. 字符级别表示 character-level representation:字符级别通常是指英文或者是其他具备自然分隔符语种的拆开嵌入,在中文中指字级别嵌入,字符嵌入主要可以降低 OOV 率。文中给出了两种常用的字符级别嵌入方式,分别为 CNN、RNN。
3. 混合信息表示 hybrid representation:除了词级别表示、字符级别表示外,一些研究工作还嵌入了其他一些语义信息,如词汇相似 度、词性标注、分块、语义依赖、汉字偏旁、汉字拼音等。此外,还有一些研究从多模态学习出发,通过模态注意力机制嵌入视觉特征。论文也将 BERT 归为这一类,将位置嵌入、token 嵌入和段嵌入看作是混合信息表示。
11.3 上下文编码
包括了卷积网络 CNN、循环网络 RNN、递归网络、Transformer。
11.3.1 CNN
基本框架如下图所示,句子经过 embedding 层,一个 word 被表示为 N 维度的向量,随后整个句子表示使用卷积(通常为一维卷积)编码,进而得到每个 word 的局部特征,再使用最大池化操作得到整个句子的全局特征,可以直接将其送入解码层输出标签,也可以将其和局部特征向量一起送入解码层。
其他一些研究者,开始考虑使用 BiLSTM-CNN 的网络结构,随之而来的还有 ID-CNNs 迭代膨胀卷积(个人认为类似多层 N-Gram 语言模型)等。
11.3.2 循环神经网络 RNN
常用的循环神经网络包括 LSTM 和 GRU,在 NLP 中常使用双向网络 BiRNN,从左到右和从右到左两个方向提取问题特征。
11.3.3 递归神经网络 Recursive Neural Networks
递归神经网络相较循环神经网络,最大区别是具有树状阶层结构。循环神经网络一个很好的特性是通过神经元循环结构处理变长序列,而对于具有树状或图结构的数据很难建模(如语法解析树)。还有一点特别在于其训练算法不同于常规的后向传播算法,而是采用 BPTS (Back Propagation Through Structure)。
虽然递归神经网络理论上感觉效果不错,但实际应用中效果一般,并且很难训练。相较之下 treeLSTM 近些年的研究经常被提及,在关系抽取以及其他任务上有不少应用。
11.3.4 Transformer
Google 的一篇《Attention is all you need》将注意力机制推上新的浪潮之巅,于此同时 transformer 这一不依赖于 CNN、RNN 结构,纯堆叠自注意力、点积与前馈神经网络的网络结构也被大家所熟知。此后的研究证明,transformer 在长距离文本依赖上相较 RNN 有更好的效果。
11.3.5 神经语言模型
语言模型是在做一件事:判断语言是否合理
发展历史:专家语法规则模型-->统计语言模型-->神经语言模型
现有的神经语言模型:
1. word2vec2. Glove3. fasttext4. ELMO5. BERT6. GPT7. GPT28. XLNET9. ALBERT10. RoBERTa
11.4 解码层
1. MLP+softmax2. CRF3. RNN4. Pointer Network
使用 RNN 解码,框架图如下所示。文中所述当前输出(并非隐藏层输出)经过 softmax 损失函数后输入至下一时刻 LSTM 单元,所以这是一个局部归一化模型。
使用指针网络解码,是将 NER 任务当作先识别“块”即实体范围,然后再对其进行分类。指针网络通常是在 Seq2seq 框架中。
其他研究方向的NER方法
下面列出各类研究方向的 NER 方法:1. 多任务学习 Multi-task Learning2. 深度迁移学习 Deep Transfer Learning3. 深度主动学习 Deep Active Learning4. 深度强化学习 Deep Reinforcement Learning5. 深度对抗学习 Deep Adversarial Learning6. 注意力机制 Neural Attention
NER任务的挑战与机遇
13.1 挑战
1. 数据标注2. 非正式文本(评论、论坛发言、tweets 或朋友圈状态等),未出现过的实体。
13.2 机遇与未来可研究方向
1. 多类别实体2. 嵌套实体3. 实体识别与实体链接联合任务4. 利用辅助资源进行基于深度学习的非正式文本 NER(补充一点,知识图谱方向)5. NER模型压缩6. 深度迁移学习 for NER
以上是关于学习--基于深度学习命名实体识别综述的主要内容,如果未能解决你的问题,请参考以下文章