分析一套源代码的代码规范和风格并讨论如何改进优化代码
Posted liujianing0421
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析一套源代码的代码规范和风格并讨论如何改进优化代码相关的知识,希望对你有一定的参考价值。
此次选取的代码是智能合约漏洞检测及分析工具Oyente的源代码。
一、Oyente
Oyente是melon.fund于2018年10月发布的一款为现有的以太坊智能合约开发人员构建的符号执行工具,以发现智能合约中潜在的安全漏洞。
开发语言:Python
工具类型:静态分析工具
分析内容:EVM字节码
工具原理:Oyente将需要分析的合约的字节码和当前以太坊的全局状态作为输入,检测合约是否存在安全问题,并向用户输入有问题的符号路径。在这个过程中,使用Z3求解器来确定可满足性。
模块划分:Oyente遵循模块化设计,由四个主要组件组成,分别是分别是CFGBuilder,Explorer,CoreAnalysis和Validator。
(1)CFGBuilder:构造合约的控制流图,其中节点是基本执行块,边表示这些块之间的执行跳转。
(2)Explorer:主要模块,象征性地执行合约。
(3)CoreAnalsis:Explorer的输出将输入CoreAnalsis,在其中我们实现针对漏洞的逻辑。
(4)Validator:在向用户报告前,由Validator确认是否有误报。
主要作用:(1)帮助开发人员编写更好的合约 (2)防止用户调用有问题的合约
局限性:可能会错过严重违规、可能会产生误报、也可能无法在现实合约中获得足够的代码覆盖率(在Parity钱包仅获得20.2%的覆盖率)
源代码:https://github.com/melonproject/oyente
相关论文:Loi Luu, Duc-Hiep Chu, Hrishi Olickel, Prateek Saxena, Aquinas Hobor: Making Smart Contracts Smarter. IACR Cryptology ePrint Archive 2016: 633 (2016)
二、源代码分析
(一)源代码特点
1、目录结构
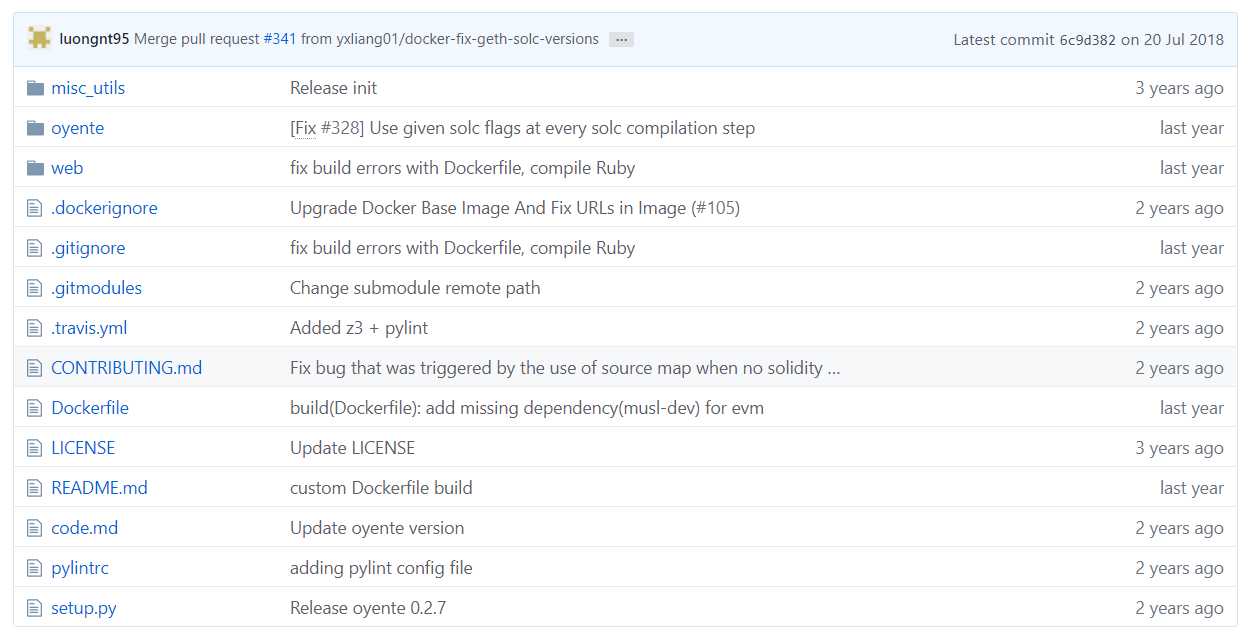
图1 源代码目录结构
做法:除了自动生成的文件外,该源代码分成了三个文件夹:mic_utils、oyente、web,分别存储接口相关代码、oyente实现相关代码和网页相关代码,结构简明清晰,让人一目了然。三个文件夹中各自的内容如下图2-4所示。
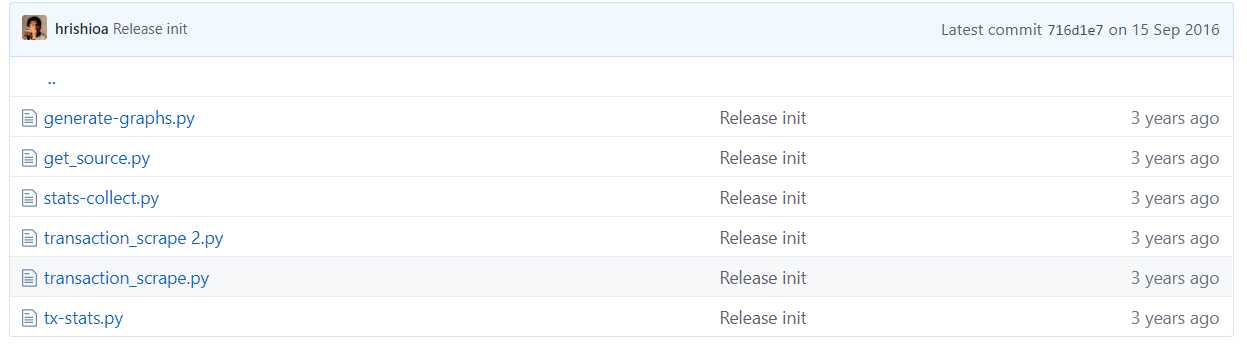
图2 misc_utils文件夹内容
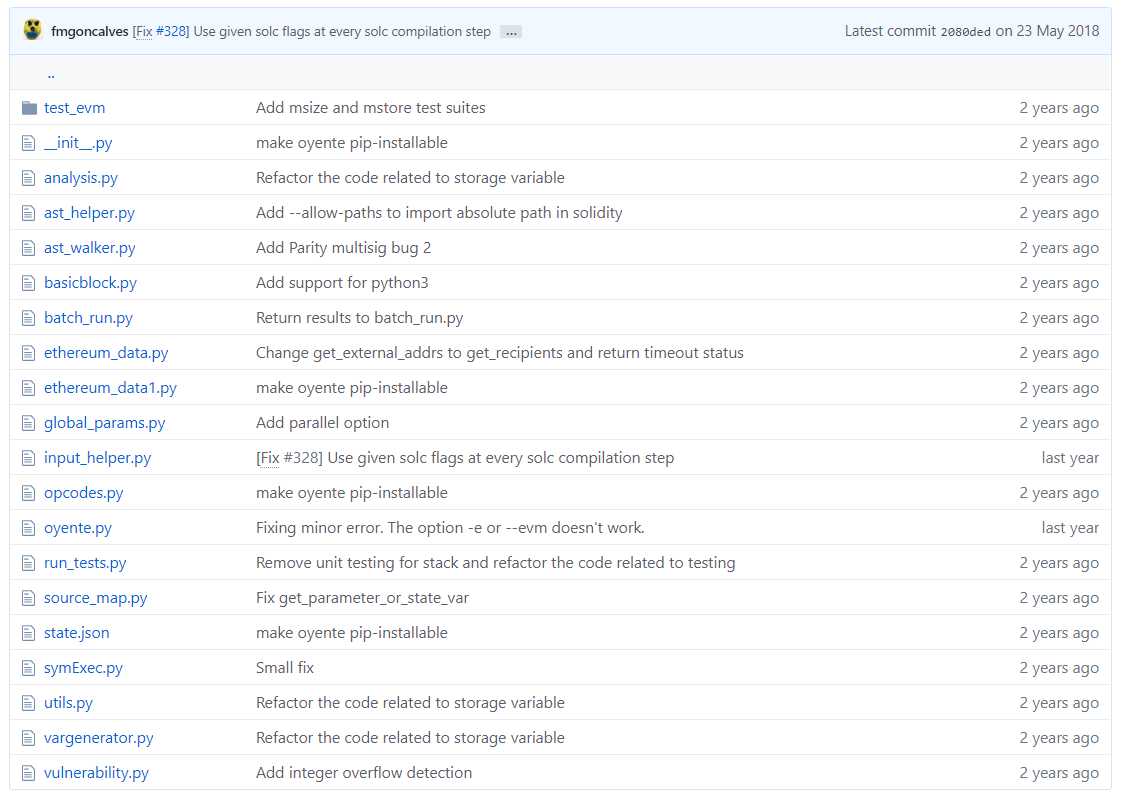
图3 oyente文件夹内容
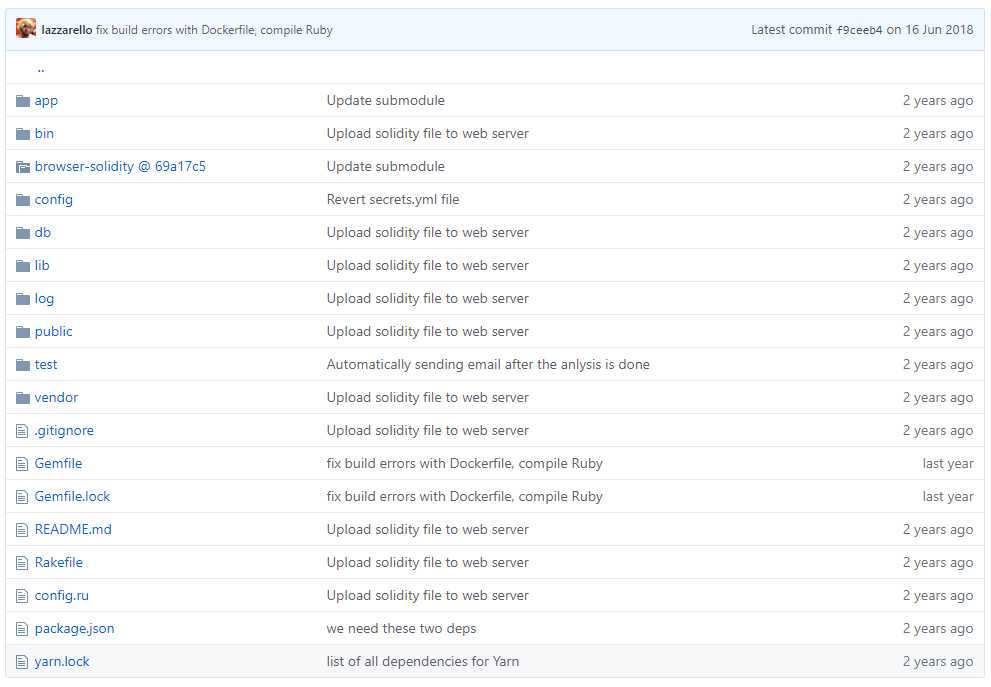
图4 web文件夹内容
2、命名规范
1 def ceil32(x): 2 return x if x % 32 == 0 else x + 32 - (x % 32) 3 4 def isSymbolic(value): 5 return not isinstance(value, six.integer_types) 6 7 def isReal(value): 8 return isinstance(value, six.integer_types) 9 10 def isAllReal(*args): 11 for element in args: 12 if isSymbolic(element): 13 return False 14 return True 15 16 def to_symbolic(number): 17 if isReal(number): 18 return BitVecVal(number, 256) 19 return number 20 21 def to_unsigned(number): 22 if number < 0: 23 return number + 2**256 24 return number 25 26 def to_signed(number): 27 if number > 2**(256 - 1): 28 return (2**(256) - number) * (-1) 29 else: 30 return number 31 32 def check_sat(solver, pop_if_exception=True): 33 try: 34 ret = solver.check() 35 if ret == unknown: 36 raise Z3Exception(solver.reason_unknown()) 37 except Exception as e: 38 if pop_if_exception: 39 solver.pop() 40 raise e 41 return ret
做法:
(1)变量名:由于Python中变量不用提前定义,此处直接使用小写字母来表示变量
(2)函数名:使用了驼峰命名法(Camel-Case),即第一个单词以小写字母开始;第二个单词的首字母大写或每一个单词的首字母都采用大写字母;且使用了易于理解的命名,让人见其形而知其意。
(二)符合代码规范和风格一般要求的做法
1、组织结构和目录结构都比较清晰
2、使用了编程中常用的驼峰命名法,命名比较规范且易于理解
3、严格使用缩进和大小写来进行组织
(三)有悖于“代码的简洁、清晰、无歧义”基本原则的做法
全程没有注释,即使阅读了工具相关的论文之后也不能理解代码的具体含义和用途。
改进方式:在合适的地方进行注释,有助于对代码的理解和应用。
三、Python编码规范(国内)
(一)格式上的编码规范
行长度:每行不超过80个字符;不要用反斜杠连接行
以下情况除外:(1)长的导入模块语句
(2)注释里的URL
语句:通常每个语句应该独占一行
导入格式:每个导入应该独占一行
缩进:用4个空格来缩进代码。绝对不可以使用Tab键,也不能将Tab和空格混用!!!
空行:顶级定义之间空两行, 方法定义之间空一行。
空格:按照标准的排版规范来使用标点两边的空格
(1)括号内不能有空格
(2)逗号, 分号, 冒号前面不要加空格, 但在它们后面应该加空格(除了在行尾)
(3)参数列表, 索引或切片的左括号前不应加空格
(4)在二元操作符两边都加上一个空格, 比如赋值(=), 比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not), 布尔(and, or, not);算术运算符自行把握,但要注意保持一致
(5)当‘=‘用于指示关键字参数或默认参数值时, 不要在其两侧使用空格
分号:不要在行尾加分号, 也不要用分号将两条命令放在同一行。
括号:宁缺毋滥的使用括号。
除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号; 不过在元组两边使用括号是可以的
(二)命名规范
应该避免的名称:
(1)单字符名称, 除了计数器和迭代器.
(2)包/模块名中的连字符(-)
(3)双下划线开头并结尾的名称(Python保留, 例如__init__)
命名约定:
(1)所谓"内部(Internal)"表示仅模块内可用, 或者, 在类内是保护或私有的.
(2)用单下划线(_)开头表示模块变量或函数是protected的(使用import * from时不会包含).
(3)用双下划线(__)开头的实例变量或方法表示类内私有.
(4)将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
(5)对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰
(三)函数和方法
【下文所指的函数,包括函数, 方法以及生成器】
一个函数必须要有文档字符串, 除非它满足以下条件:外部不可见、非常短小、简单明了
文档字符串:
(1)应该包含函数做什么, 以及输入和输出的详细描述
(2)应该提供足够的信息, 当别人编写代码调用该函数时, 只要看文档字符串就可以了
(3)对于复杂的代码, 在代码旁边加注释会比使用文档字符串更有意义
关于函数的几个方面(如下所示:Args、Returns、Raises)应该在特定的小节中进行描述记录, 每节应该以一个标题行开始, 标题行以冒号结尾;除标题行外,,其他内容应被缩进2个空格。
- Args:列出每个参数的名字, 并在名字后使用一个冒号和一个空格, 分隔对该参数的描述.如果描述太长超过了单行80字符,用2或者4个空格的悬挂缩进(与文件其他部分保持一致)。 描述应该包括所需的类型和含义, 如果一个函数接受*foo(可变长度参数列表)或者**bar (任意关键字参数), 应该详细列出*foo和**bar。
- Returns:(或者 Yields: 用于生成器)描述返回值的类型和语义。 如果函数返回None, 这一部分可以省略。
- Raises:列出与接口有关的所有异常。
1 def fetch_bigtable_rows(big_table, keys, other_silly_variable=None): 2 """Fetches rows from a Bigtable. 3 4 Retrieves rows pertaining to the given keys from the Table instance 5 represented by big_table. Silly things may happen if 6 other_silly_variable is not None. 7 8 Args: 9 big_table: An open Bigtable Table instance. 10 keys: A sequence of strings representing the key of each table row 11 to fetch. 12 other_silly_variable: Another optional variable, that has a much 13 longer name than the other args, and which does nothing. 14 15 Returns: 16 A dict mapping keys to the corresponding table row data 17 fetched. Each row is represented as a tuple of strings. For 18 example: 19 20 {‘Serak‘: (‘Rigel VII‘, ‘Preparer‘), 21 ‘Zim‘: (‘Irk‘, ‘Invader‘), 22 ‘Lrrr‘: (‘Omicron Persei 8‘, ‘Emperor‘)} 23 24 If a key from the keys argument is missing from the dictionary, 25 then that row was not found in the table. 26 27 Raises: 28 IOError: An error occurred accessing the bigtable.Table object. 29 """ 30 pass
以上是关于分析一套源代码的代码规范和风格并讨论如何改进优化代码的主要内容,如果未能解决你的问题,请参考以下文章