验证码识别竞赛解决方案(97%)
Posted pprp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了验证码识别竞赛解决方案(97%)相关的知识,希望对你有一定的参考价值。
前言:这个库是为验证码识别竞赛而开发的一个基于pytorch实现的端到端的验证码识别系统。前后开发大概有2个月,其中大部分时间都在调参,后期参考kaggle大神经验,加入了一些trick,但是由于第一个榜截止了,所以没有得到测试集结果,只有验证集的参考结果。该库比较简单,适合入门竞赛,不过调参难度比较大,需要尝试合适的超参数,如果超参数不合适,可能会导致无法收敛,具体问题具体分析。
1. 竞赛背景
基于https://github.com/dee1024/pytorch-captcha-recognition进行改进,原版中数据集采用的captcha库自动生成的图片,可以随意制定生成数量,并且相对而言生成的图片比较简单。
本次项目是全国高校计算机能力挑战赛中的人工智能赛道里的验证码识别,该比赛需要识别26(大写)+26(小写)+数字(10)= 62个字符,随机组成的四位验证码图片。训练集仅有5000张,并且识别的难度系数较大,人眼有时候也很容易识别出错。
最终库地址:https://github.com/pprp/captcha.Pytorch
2. 环境要求
- 显存:2G以上
- Ubuntu16.04
- numpy
- torch==1.1.0
- torchnet==0.0.4
- torchvision==0.2.0
- tqdm
- visdom
- adabound
- Augmentor
可通过pip install -r requirements.txt进行环境的安装或者使用以下命令进行安装
pip install numpy torchnet==0.0.4 torchvision==0.2.0 tqdm visdom adabound Augmentor -i https://mirrors.aliyun.com/pypi/simple3. 数据集

比赛提供的数据集如上图所示,120$ imes$40的像素的图片,然后标签是由图片名称提供的。训练集测试集划分:80%的数据用于训练集,20%的数据用于测试集。
- 训练图片个数为:3988
- 测试图片个数为:1000
训练的数据还是明显不够的,考虑使用数据增强,最终选择了Augmentor库作为图像增强的库。
安装方式:pip install Augmentor
API: https://augmentor.readthedocs.io/en/master/index.html
由于验证码与普通的分类图片有一定区别,所以选择的增强方式有一定局限,经过几轮实验,最终选取了distortion类的方法作为具体增强方法,输入为训练所用的图片,输出设置为原来图片个数的2倍,具体代码见dataAug.py, 核心代码如下:
def get_distortion_pipline(path, num):
p = Augmentor.Pipeline(path)
p.zoom(probability=0.5, min_factor=1.05, max_factor=1.05)
p.random_distortion(probability=1, grid_width=6, grid_height=2, magnitude=3)
p.sample(num)
return p将得到的图片重命名为auged_train文件夹,最终数据集组成如下:
root
- data
- train:3988张
- test:1000张
- auged_train:7976张增强后的数据集,建议使用dataset2
链接:https://pan.baidu.com/s/13BmN7Na4ESTPAgyfBAHMxA
链接:https://pan.baidu.com/s/13BmN7Na4ESTPAgyfBAHMxA
提取码:v4nk
数据集结构的组织,从网盘下载数据以后,按照以下文件夹格式进行组织:
- data
- train
- test
- auged_train然后就可以训练了。
4. 库的组织架构
root
- config
- parameters.py 主要包括超参数,最重要的是learning rate
- lib
- center_loss.py 将center loss引入,用于训练
- dataset.py 包装Dataset,针对train文件夹和auged_train文件夹内容各自写了一个处理类
- generate_captcha.py 生成简单的数据集,在没有官方数据集的情况下
- optimizer.py RAdam, AdamW, label smooth等新的optimizer
- scheduler.py 新增了warmup机制
- model
- BNNeck.py 基于resnet18使用了bnnect结构,来自罗浩大佬行人检测中的trick
- CaptchaNet.py 手工构建的一个简单网络,原有库提供的
- dense.py 更改backbone,使用dense121作为backbone,其他也可以更改
- dualpooling.py 在resnet18基础上添加了dual pooling,增加了信息
- IBN.py 使用ibn模块,以resnet18为基础
- model.py resnet18,添加dropout
- res18.py 引入了attention机制和dual pooling
- senet.py 将senet作为backbone
- result
- submission.csv 结果保存
- utils
- cutoff.py 数据增强方法,不适合验证码,可以用在普通图片
- dataAug.py 使用Agumentor进行数据增强
- Visdom.py 使用visdom记录log,进行可视化
- predict.py 引入了多模型预测,然后分析结果
- run.py 与predict类似,不过是单模型的预测
- test.py 规定测试模型权重,待测试图片路径,对测试集进行测试
- train.py 模型的训练,每个epoch先训练所有的train,然后训练所有的auged_train图片5. 训练结果
最好结果:
ResNet18+Dropout(0.5)+RAdam+DataAugmentation+lr(3e-4) = 98.4%测试集准确率,线上A榜:97%
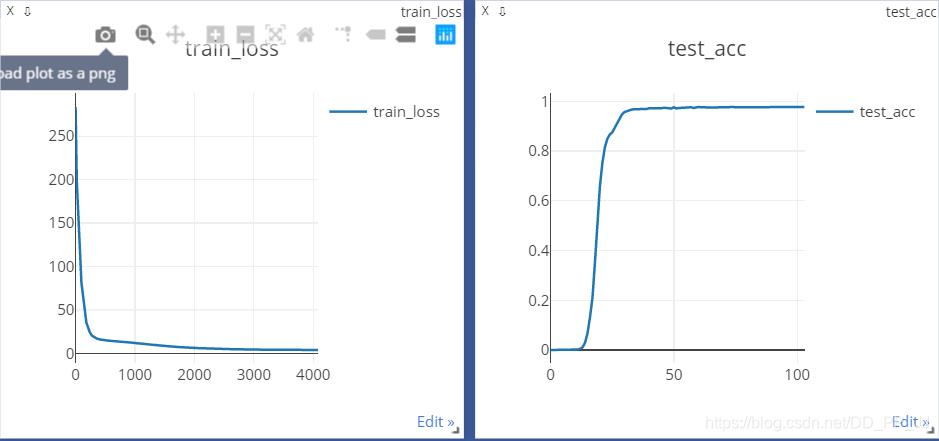
模型分析:分析四个模型,python predict.py 观察预测出错的结果,评判模型好坏,最终选择了0号模型。

6. 调参过程记录
调参过程记录:null代表未记录
| Name | item1 | item2 | item3 | item4 | item5 | 测试:线上 |
|---|---|---|---|---|---|---|
| baseline0 | ResNet18 | lr=1e-3 | 4:1划分 | Adam | 88%:84% | |
| baseline1 | ResNet34 | lr=1e-3 | 4:1划分 | Adam | 90%:84% | |
| baseline2 | ResNet18 | lr=1e-3 | 4:1划分 | RAdam | null:90% | |
| baseline3 | ResNet18 | lr=3e-4 | 4:1划分 | RAdam | 未收敛 | |
| baseline4 | ResNet18 | lr=1e-1 | 4:1划分 | RAdam | 96.4%:87% | |
| baseline5 | ResNet18 | lr=1e-1 | 4:1划分 | RAdam | aug0 | 98%:93% |
| baseline6 | ResNet18 | lr=1e-1 | 9:1划分 | RAdam | aug1 | 60%:null |
| baseline7 | ResNet18 | lr=1e-3 | 4:1划分 | RAdam | aug2 | null:94% |
| baseline8 | ResNet18 | lr=1e-3 | 4:1划分 | AdamW | aug2 | 98.4%:92.56% |
| baseline9 | ResNet18 | lr=1e-3 | 4:1划分 | RAdam | aug3 | null:93.52% |
| baseline10 | ResNet18 | lr=1e-3 | 4:1划分 | RAdam | aug4 | null:94.16% |
| baseline11 | ResNet18 | lr=1e-3 | 9:1划分 | RAdam | aug5 | 60%:null |
| baseline12 | ResNet18 | lr=3.5e-4 | 4:1划分 | RAdam | aug2 | null:94.72% |
| baseline13 | ResNet18 | lr=3.5e-4 decay:6e-4 | 4:1划分 | RAdam | aug2 | null:95.16% |
| baseline14 | ResNet18 | lr=3.5e-4 decay:7e-4 | 4:1划分 | RAdam | aug2 | bad |
| baseline15 | ResNet18 | lr=3.5e-5 decay:6.5e-4 | 4:1划分 | RAdam | aug2 | null:95% |
| baseline16 | ResNet18 | lr=3.5e-5 decay:6.5e-4 | 4:1划分 | RAdam | drop(0.5) | null:97% |
以上的aug代表数据增强:
- aug0: +distrotion
- aug1: 9:1划分+扩增3倍
- aug2: +distortion+zoom
- aug3: +tilt+扩增两倍
- aug4: aug2+aug3混合
- aug5: 9:1划分 +tilt倾斜
数据增强示意图:
| example1 | example2 | example3 |
|---|---|---|
 |
 |
 |
后期由于错过了提交时间,只能进行测试集上的测试,主要方案有以下:
- learning rate scheduler尝试:CosineAnnealingLR, ReduceLROnPlateau,StepLR,MultiStepLR
- 更改backbone: senet, densenet
- 在res18基础上添加:attention机制,dual pooling, ibn模块,bnneck等
- 尝试center loss,收敛很慢,但是效果应该不错
还未尝试的方案:
- label smooth
- 多模型ensemble
联系方式:
- QQ: 1115957667
- CSDN:https://blog.csdn.net/DD_PP_JJ
- 博客园:https://www.cnblogs.com/pprp
后记:整个比赛下来得到了一等奖,整个过程可谓过山车一般,比赛还没有放榜的时候,觉得问题不会很难,因为提前查看了网上的验证码库,研究了一下发现,大部分验证码都很简单,比较清晰,但是这次验证码下来以后就发现难度比较大
- 数字+大小写字母,容易混淆
- 图片验证码难以识别,人眼都难以分辨
- 选择架构,直接选取端到端还是先切割然后 做单字符识别
- 数据量很小, 其他库可以用captcha进行验证码的生成,所以数据量不会受限制,这次训练一共给了5000,划分完训练集验证机以后就只剩下4000图片用于训练,数据规模比较小,所以可能对超参数比较敏感,如果选取不合适就会导致模型不收敛。
之后就选择了一个能达到80%准确率的baseline开始调整,然后在自己的验证集通过调参能够达到90%的准确率,然后就开始感觉差不多了,因为里边确实有很多人眼都识别不清楚。但是还是低估了神经网络的能力,榜单不断刷新,直逼100%, 后边把我从前10挤到了100多,然后这个时候开始正视这个比赛,开始认真调参,更换模型,添加最新的trick等等,其中比较有感触的是比赛结束前一段时间,突发奇想想加入dropout, dropout可以视作多模型集成,效果可能会好一点,所以加了dropout以后,榜一排名到了30左右,最终也选择提交这个带有dropout的模型,最终才得到不错的结果。
以上是关于验证码识别竞赛解决方案(97%)的主要内容,如果未能解决你的问题,请参考以下文章