全国高校计算机能力挑战赛验证码识别竞赛一等奖调参经验分享
Posted GiantPandaCV
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全国高校计算机能力挑战赛验证码识别竞赛一等奖调参经验分享相关的知识,希望对你有一定的参考价值。
前言:这是为验证码识别竞赛而开发的一个基于pytorch实现的端到端的验证码识别系统。前后开发大概有2个月,其中大部分时间都在调参,后期参考kaggle大神经验,加入了一些trick,但是由于第一个榜截止了,所以没有得到测试集结果,只有验证集的参考结果。该库比较简单,适合入门竞赛,不过调参难度比较大,需要尝试合适的超参数,如果超参数不合适,可能会导致无法收敛,具体问题还需具体分析。
-
作者:pprp -
编辑:BBuf
1. 竞赛背景
本次比赛是全国高校计算机能力挑战赛中的人工智能赛道里的验证码识别,该比赛需要识别26(大写)+26(小写)+数字(10)= 62个字符,随机组成的四位验证码图片。
2. 赛题分析
-
训练集仅有5000张,而所有的数字组合有 个组合。 -
验证码识别的难度系数较大,人眼也很容易识别出错。 -
噪声比较严重,存在遮挡字符的情况。
3. 数据集
比赛提供的数据集如上图所示,120 40的像素的图片,然后标签是由图片名称提供的。
训练集测试集划分:80%的数据用于训练集,20%的数据用于测试集。
-
训练图片个数为:3988
-
测试图片个数为:1000
训练的数据还是明显不够的,考虑使用数据增强,最终选择了Augmentor库作为图像增强的库。Augmentor库很适合做图像分类的数据增强。由于验证码与普通的分类图片有一定区别,所以选择的增强方式有一定局限,比如不能翻转,不能左右颠倒,不能crop等, 但是也有一些比较好用的方法,比如说distortion(弹性变形), perspective skewing (透视偏斜),图片缩放等方法也适用于验证码识别。
经过几轮实验,最终选取了distortion类的方法作为具体增强方法,输入为训练所用的图片,输出设置为原来图片个数的2倍,具体代码见dataAug.py, 核心代码如下:
def get_distortion_pipline(path, num):p = Augmentor.Pipeline(path)p.zoom(probability=0.5,min_factor=1.05,max_factor=1.05)p.random_distortion(probability=1,grid_width=6,grid_height=2,magnitude=3)p.sample(num)if __name__ == "__main__":# 生成训练集两倍的数据量get_distortion_pipline("path to image folder", 2 * len(train_folder))
将得到的图片重命名为auged_train文件夹,最终数据集组成如下:
root|---data|--- train:3988张|--- test:1000张|--- auged_train:7976张
训练流程是每隔epoch先遍历train文件夹,然后遍历auged_train文件夹,最后对test文件夹进行一次测试,完成一次遍历。PS:数据集下载链接在文末。
4. Trick总结
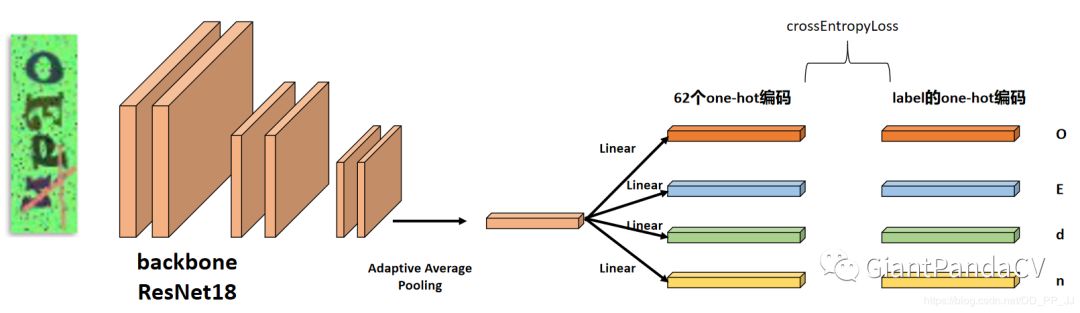
上图就是整个验证码识别的流程图,也是baseline, 在此基础上可以使用很多分类网络中用到的trick。
比赛从以下几个角度进行调参优化:
-
调整超参数: -
CosineAnnealingLR -
ReduceLROnPlateau -
StepLR -
MultiStepLR -
GradualWarmupScheduler(warm up) -
Learning Rate 调整 -
decay参数调整 -
learning rate scheduler尝试: -
更改优化器: -
Adam优化器 -
RAdam优化器 -
AdamW优化器 -
AdaBound优化器(尝试过后效果很差,网络不收敛,可能是由于超参数设置问题) -
数据增强 -
augmentor库中的distortion方法 -
attention机制 -
尝试se模块 -
修改backbone: -
添加dual pooling 模块 -
添加bnneck模块 -
添加ibn模块 -
senet -
densenet -
resnet18 -
更换loss: -
使用center loss+CrossEntropyLoss,收敛比较慢,对参数敏感
5. 调参过程记录
调参过程记录:null代表未记录
| Name | item1 | item2 | item3 | item4 | item5 | 测试:线上 |
|---|---|---|---|---|---|---|
| baseline0 | Ret18 | lr=1e-3 | 4:1划分 | Adam | 88%:84% | |
| baseline1 | Res34 | lr=1e-3 | 4:1划分 | Adam | 90%:84% | |
| baseline2 | Res18 | lr=1e-3 | 4:1划分 | RAdam | null:90% | |
| baseline3 | Res18 | lr=3e-4 | 4:1划分 | RAdam | 未收敛 | |
| baseline4 | Res18 | lr=1e-1 | 4:1划分 | RAdam | 96.4%:87% | |
| baseline5 | Res18 | lr=1e-1 | 4:1划分 | RAdam | aug0 | 98%:93% |
| baseline6 | Res18 | lr=1e-1 | 9:1划分 | RAdam | aug1 | 60%:null |
| baseline7 | Res18 | lr=1e-3 | 4:1划分 | RAdam | aug2 | null:94% |
| baseline8 | Res18 | lr=1e-3 | 4:1划分 | AdamW | aug2 | 98.4%:92.56% |
| baseline9 | Res18 | lr=1e-3 | 4:1划分 | RAdam | aug3 | null:93.52% |
| baseline10 | Res18 | lr=1e-3 | 4:1划分 | RAdam | aug4 | null:94.16% |
| baseline11 | Res18 | lr=1e-3 | 9:1划分 | RAdam | aug5 | 60%:null |
| baseline12 | Res18 | lr=3.5e-4 | 4:1划分 | RAdam | aug2 | null:94.72% |
| baseline13 | Res18 | lr=3.5e-4 decay:6e-4 | 4:1划分 | RAdam | aug2 | null:95.16% |
| baseline14 | Res18 | lr=3.5e-4 decay:7e-4 | 4:1划分 | RAdam | aug2 | bad |
| baseline15 | Res18 | lr=3.5e-5 decay:6.5e-4 | 4:1划分 | RAdam | aug2 | null:95% |
| baseline16 | Res18 | lr=3.5e-5 decay:6.5e-4 | 4:1划分 | RAdam | drop(0.5) | null:97% |
以上的aug代表数据增强:
-
aug0: +distrotion -
aug1: 9:1划分+扩增3倍 -
aug2: +distortion+zoom -
aug3: +tilt+扩增两倍 -
aug4: aug2+aug3混合 -
aug5: 9:1划分 +tilt倾斜
数据增强示意图:
| example1 | example2 | example3 |
|---|---|---|
 |
 |
 |
后期尝试的主要方案有以下:
-
learning rate scheduler尝试:CosineAnnealingLR, ReduceLROnPlateau,StepLR,MultiStepLR -
更改backbone: senet, densenet -
在res18基础上添加:attention机制,dual pooling, ibn模块,bnneck等 -
尝试center loss,收敛很慢,但是效果应该不错
还未尝试的方案:
-
label smooth -
多模型ensemble
6. 相关链接
augmentor API:https://augmentor.readthedocs.io/en/master/index.html
链接:https://pan.baidu.com/s/13BmN7Na4ESTPAgyfBAHMxA 提取码:v4nk
增强后的数据集,建议使用dataset2
后记:整个比赛下来得到了一等奖,整个过程可谓过山车一般,比赛还没有放榜的时候,觉得问题不会很难,因为提前查看了网上的验证码库,研究了一下发现,大部分验证码都很简单,比较清晰,但是这次验证码下来以后就发现难度比较大。之后就选择了一个能达到80%准确率的baseline开始调整。其中比较有感触的是比赛结束前突发奇想,加入了dropout,效果一下提升了很多,榜一排名到了30左右。
以上是关于全国高校计算机能力挑战赛验证码识别竞赛一等奖调参经验分享的主要内容,如果未能解决你的问题,请参考以下文章