20 行代码带你实现验证码自动识别
Posted 大学IT圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20 行代码带你实现验证码自动识别相关的知识,希望对你有一定的参考价值。
阅读文本大概需要 8 分钟。
这几天在写代码的过程中遇到一个需求,爬虫模拟登录。这个过程中需要填写验证码,于是本着以人为本的原则,这当然是能用代码实现就用代码实现了。于是乎提出了验证码自动识别的需求。
经过一顿探索发现,终于解决了这个问题,其实也很简单。主要的工具就是 tesseract-ocr 和对应的 python 包 pytesseract。tesseract-ocr 是一个用来实现图像识别的工具。
https://github.com/UB-Mannheim/tesseract/wiki
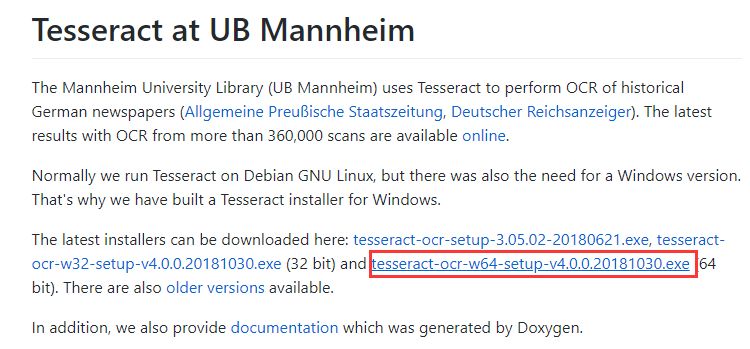
下载工程中会出现选择安装内容的提示框,记得要将语言选项中的中文选上,这次验证码识别可能不会用到,为以后中文识别做准备。如果点了全选,在下载过程中可能会出现错误提示,忽略即可。
pytesseract 下载:
pip3 install pytesseract
到这里我们的基本工具就安装好了,接下来用代码实现。代码实现之前我们先来找一个验证码来测试,我这里找的是中国知网登录时的验证码:
http://login.cnki.net/checkcode.aspx
一句 Python 代码即可爬到验证码,十分方便。
import requests
imgdata = requests.get('http://login.cnki.net/checkcode.aspx')
接下来就可以用 pytesseract 实现验证码识别了。
import requests
import pytesseract
import io
from PIL import Image
imgdata = requests.get('http://login.cnki.net/checkcode.aspx')
# 通过 io 模块实现模拟文件读取操作,让Image.open读取爬取的图片数据
image = Image.open(io.BytesIO(imgdata.content))
# 模式L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
img = image.convert('L')
vcode = pytesseract.image_to_string(img, lang='eng', config='--psm 7 ')
print(vcode)
这里用到了 PIL 库,执行以下命令安装:
pip3 install pillow
如果你在安装 tesseract-ocr 的时候自定义了安装路径,执行这个代码会遇到一个报错,如果没有请自行忽略,通过修改 pytesseract.py 文件代码,将 tesseract_cmd 变量修改为 tesseract-ocr 安装路径执行成功,不要忘记字符串前面的 r 。
tesseract_cmd = r'D:\Program Files (x86)\Tesseract-OCR\tesseract.exe'

在上面代码可以看到,我们在进行图片识别前还进行了一些图片的处理操作。首先用 Image 方法打开图片。因为 Image.open 方法打开的是图片文件,所以我们这里用 io.BytesIO() 方法模拟文件打开操作,注意这个方法的参数是二进制数据。我也看了好多百度的方法,还是用这个方法最简单。
打开文件之后还进行了一步灰度处理操作,它可以将文件处理成类似这样的样式:

经过处理可以大幅提高图片识别成功率。在我这里只用到了灰度处理方法,除此之外,常用的还有二值处理,即将图片处理成非黑即白的图像。代码如下:
imgdata = requests.get('http://login.cnki.net/checkcode.aspx')
# 通过 io 模块实现模拟文件读取操作,让Image.open读取爬取的图片数据
image = Image.open(io.BytesIO(imgdata.content))
# 模式L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
img = image.convert('L')
#二值化,阈值可以根据情况修改
threshold = 128
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
img2 = img.point(table, '1')
vcode = pytesseract.image_to_string(img, lang='eng', config='--psm 7 ')
print(vcode)
二值处理后的图片是这样的:

二值化的阀值可以根据时间情况进行调整,一般150左右效果比较好。
最后 pytesseract.image_to_string 这个方法就是完成图片识别的代码了,你没有看错,真正用来识别的代码就这一句。不过通常都会提前对图片进行一定的处理,可以显著提高识别的正确率。
另外可以看到这个方法还有几个参数,img 就是处理过后的图片,lang 参数用来指定语言 eng 表示英语、chi_sim 表示中文,config 指定识别模式,这里指定为 --psm 7,默认为 --psm 3,如果默认的不能识别成功的话,不妨试试 --psm 7 或其他模式。这里有一份各种模式的参数表:
1自动页面分割与OSD。
2自动页面分割,但没有OSD或OCR。
3全自动页面分割,但没有OSD。 (默认)
4假设单列可变大小的文本。
5假设一个垂直对齐的文本的统一块。
6假设单个统一的文本块。
7将图像视为单个文本行。
8将图像视为单个字。
9将图像视为一个单个的单词。
10将图像视为单个字符。
利用上述代码已经可以完成简单的验证码识别操作,我自己也只使用了灰度处理操作,因为我的验证码风格比较统一,直接识别灰度图比二值图成功率更高一些,直接将登陆操作放到一个循环里面,直到验证码识别正确登陆成功才推退出循环,时间的消耗也还能接受。
另外还有一些提高正确率的方法,比如:对 tesseract 进行训练、对二值图进行去噪等等都是可行的办法,需要自行探索。
到这里,就已经结束了吗?不,还有最后一步,那就是在服务器配置。不得不说,有时候在 Windows 弄的好好的,一上到服务器就是一个大坑。
服务器配置:
这里我们直接按照官方提供的方法进行安装即可,安装过程也十分舒适,比百度的教程要简单很多。
https://github.com/tesseract-ocr/tesseract/wiki
为了方便,这里直接将官方的教程也贴出来了,我的服务器是CentOS,直接找到对应服务器安装教程:
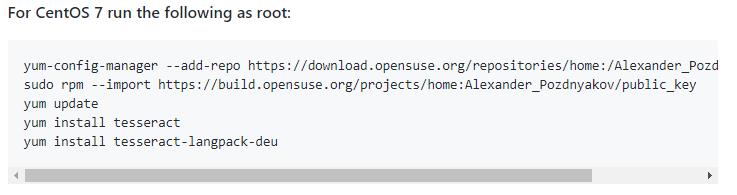
直接复制到服务器执行即可安装成功。这里还有一个小坑就是 yum-config-manager 命令找不到,执行下面这条命令再执行教程即可安装成功:
yum -y install yum-utils
附最后成功登陆效果图:
这个登陆其实是需要用户填写验证码的,通过后台自动识别完成验证码填写,用户只需要填写账号和密码即可,还是很舒服的。
学会了吗?点击留言留下你的评论,另外不要忘记点赞哦~
长按关注~
以上是关于20 行代码带你实现验证码自动识别的主要内容,如果未能解决你的问题,请参考以下文章