实战!轻松搭建图像分类 AI 服务
Posted huaweicloud
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战!轻松搭建图像分类 AI 服务相关的知识,希望对你有一定的参考价值。
人工智能技术(以下称 AI)是人类优秀的发现和创造之一,它代表着至少几十年的未来。在传统的编程中,工程师将自己的想法和业务变成代码,计算机会根据代码设定的逻辑运行。与之不同的是,AI 使计算机有了「属于自己的思想」,它就像生物一样,能够「看」、「听」、「说」、「动」、「理解」、「分辨」和「思考」。

AI 在图像识别和文本处理方面的效果尤为突出,且已经应用到人类的生活中,例如人脸识别、对话、车牌识别、城市智慧大脑项目中的目标检测和目标分类等。


接下来,我们将了解图像分类的需求、完成任务的前提条件和任务实践。
图像分类以及目标检测的需求
AI 的能力和应用都非常广泛,这里我们主要讨论的是图像分类。
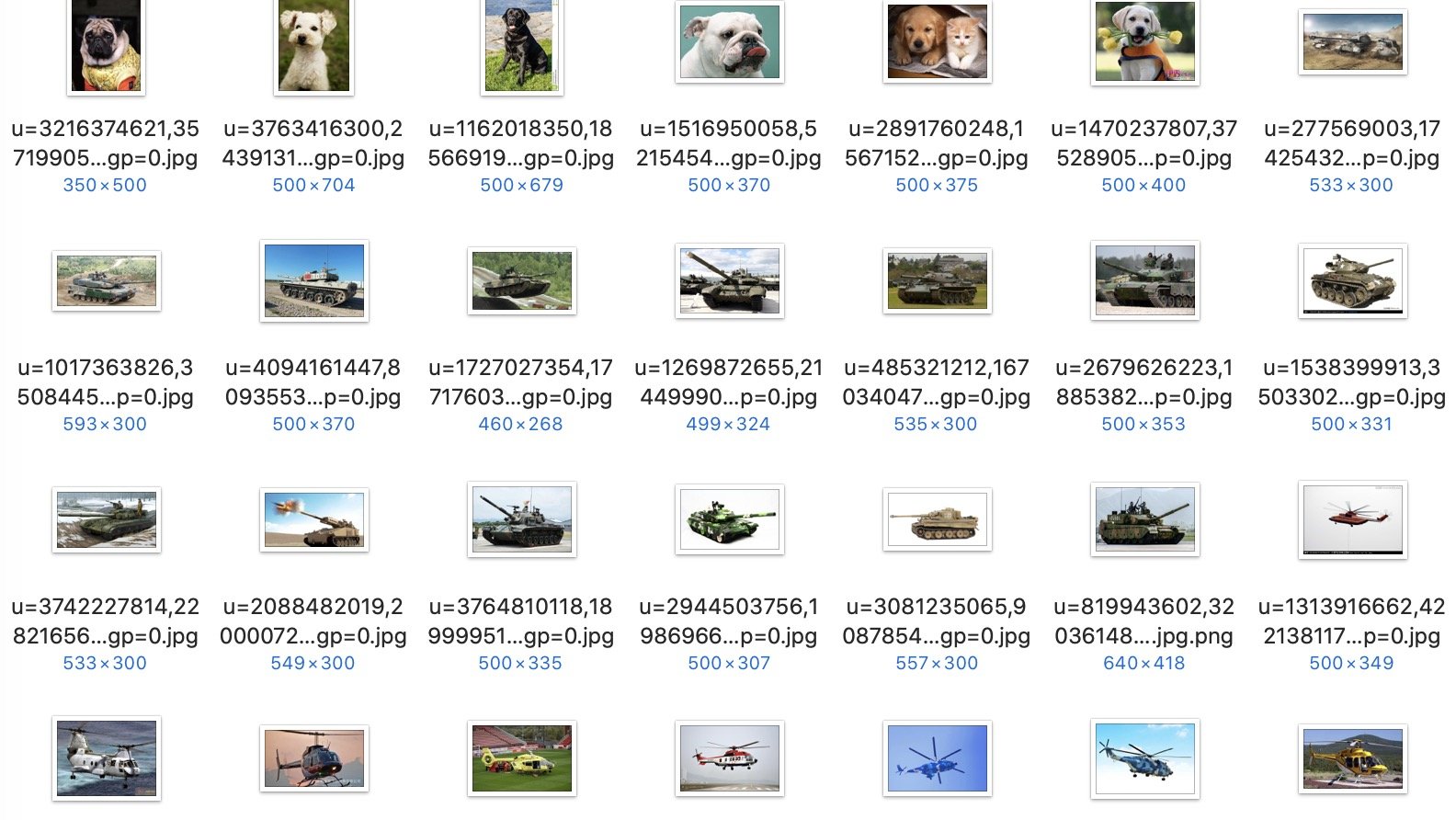
图像分类,其实是对图像中主要目标的识别和归类。例如在很多张随机图片中分辨出哪一张中有直升飞机、哪一张中有狗。或者给定一张图片,让计算机分辨图像中主要目标的类别。
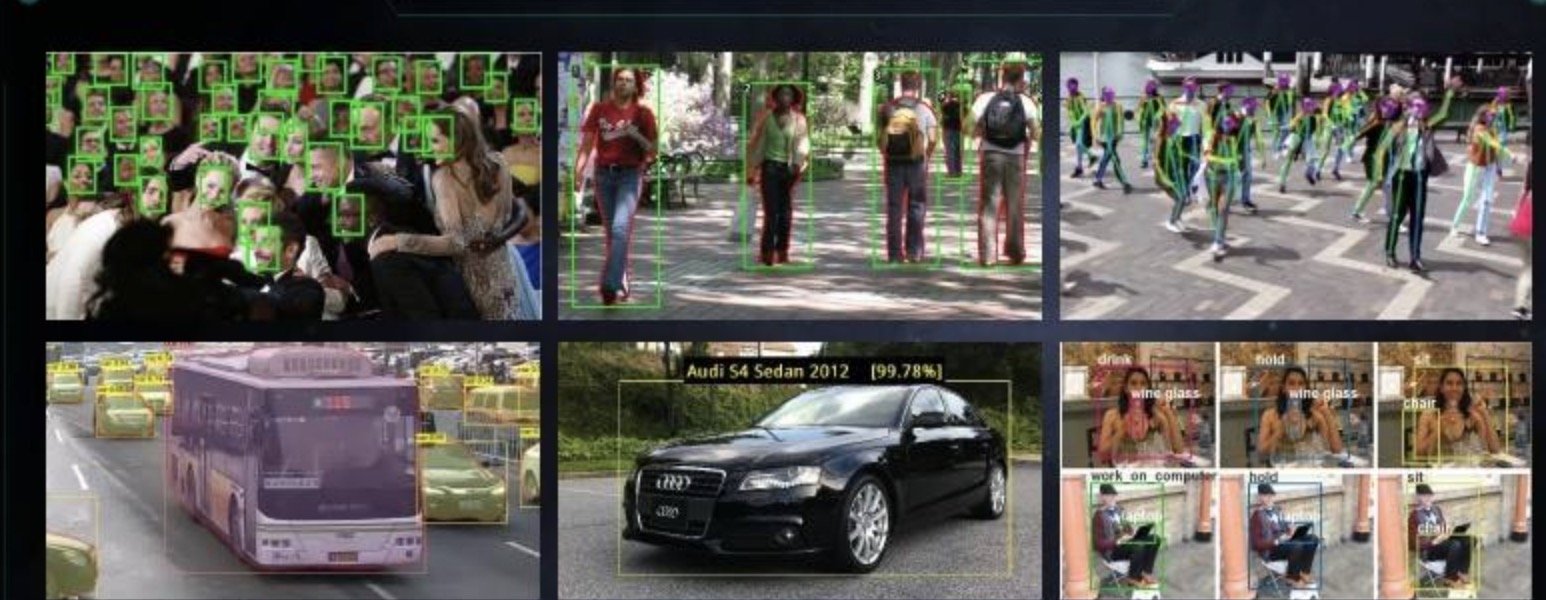
目标检测,指的是检测目标在图片中的位置。例如智慧交通项目中,路面监控摄像头拍摄画面中车辆的位置。目标检测涉及两种技术:分类和定位。也就是说先判定图片中是否存在指定的目标,然后还需要确定目标在图片中的位置。
 这样的技术将会应用在人脸识别打卡、视频监控警报、停车场、高速收费站和城市智慧交通等项目当中。
这样的技术将会应用在人脸识别打卡、视频监控警报、停车场、高速收费站和城市智慧交通等项目当中。
计算机识图的步骤
我们可以将计算机的看作是一个小朋友,它在拥有「分辨」的能力之前,必须经历「看」和「认识」这两个步骤,在看过很多图片后,它就会形成自己的「认知」,也就是获得了「分辨」能力。

简单来说,AI 工程师必须准备很多张不同的图片,并且将一大部分图片中的目标标注出来,然后让计算机提取每张图片中的特征,最后就会形成「认知」。
想一想,你还小的时候,是如何分辨鸭子和鹅的呢?

是不是根据它们的特征进行判断的?
学习和编程实现任务需要的条件
了解完需求和步骤之后,我们还需要准备一些条件:
- 首先,你必须是一名 IT 工程师。
- 然后你有一定的数学和统计学习基础。
- 你还得了解计算机处理图像的方式。
- 如果图片较多,你需要一台拥有较高算力 GPU 的计算机,否则计算机的「学习」速度会非常慢。
具备以上条件后,再通过短时间(几天或一周)的学习,我们就能够完成图像分类的任务。
讨论个额外的话题,人人都能够做 AI 工程师吗?
AI 的门槛是比较高的,首先得具备高等数学、统计学习和编程等基础,然后要有很强的学习能力。对于 IT 工程师来说:
- 编程基础是没有问题的
- 学习能力看个人,但花时间、下功夫肯定会有进步
- 高等数学基础,得好好补
- 统计学习基础,也得好好补
- 经济上无压力
如果你想要成为一名 AI 工程师,那么「高学历」几乎是必备的。无论是一线互联网企业或者新崛起的 AI 独角兽,它们为 AI 工程师设立的学历门槛都是「硕士」。除非特别优秀的、才华横溢的大专或本科生,否则是不可能有机会进入这样的企业做 AI 工程师的。

AI 在硬件、软件、数据资料和人才方面都是很费钱的,普通的 IT 工程师也就是学习了解一下,远远达不到产品商用的要求。
普通的中小企业,极少有资质和经济能力吸引高学历且优秀的 AI 工程师,这就导致了资源的聚拢和倾斜。
想要将图像分类技术商用,在让计算机经历「看」、「认识」的步骤并拥有「分辨」能力后,还要将其转换为 Web 服务。
但我只想将人脸识别或者图像分类的功能集成到我的项目当中,就那么困难吗?
我只是一个很小的企业,想要在原来普通的视频监控系统中增加「家人识别」、「陌生人警报」、「火灾警报」和「生物闯入提醒」等功能,没有上述的条件和经济投入,就不能实现了吗?
我好苦恼!
有什么好办法吗?
ModelArts 简介和条件
ModelArts 是华为云推出的产品,它是面向开发者的一站式 AI 开发平台。

它为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式 Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。
它为用户提供了以下可选模式:
- 零编码经验、零 AI 经验的自动学习模式
- 有 AI 研发经验的全流程开发模式
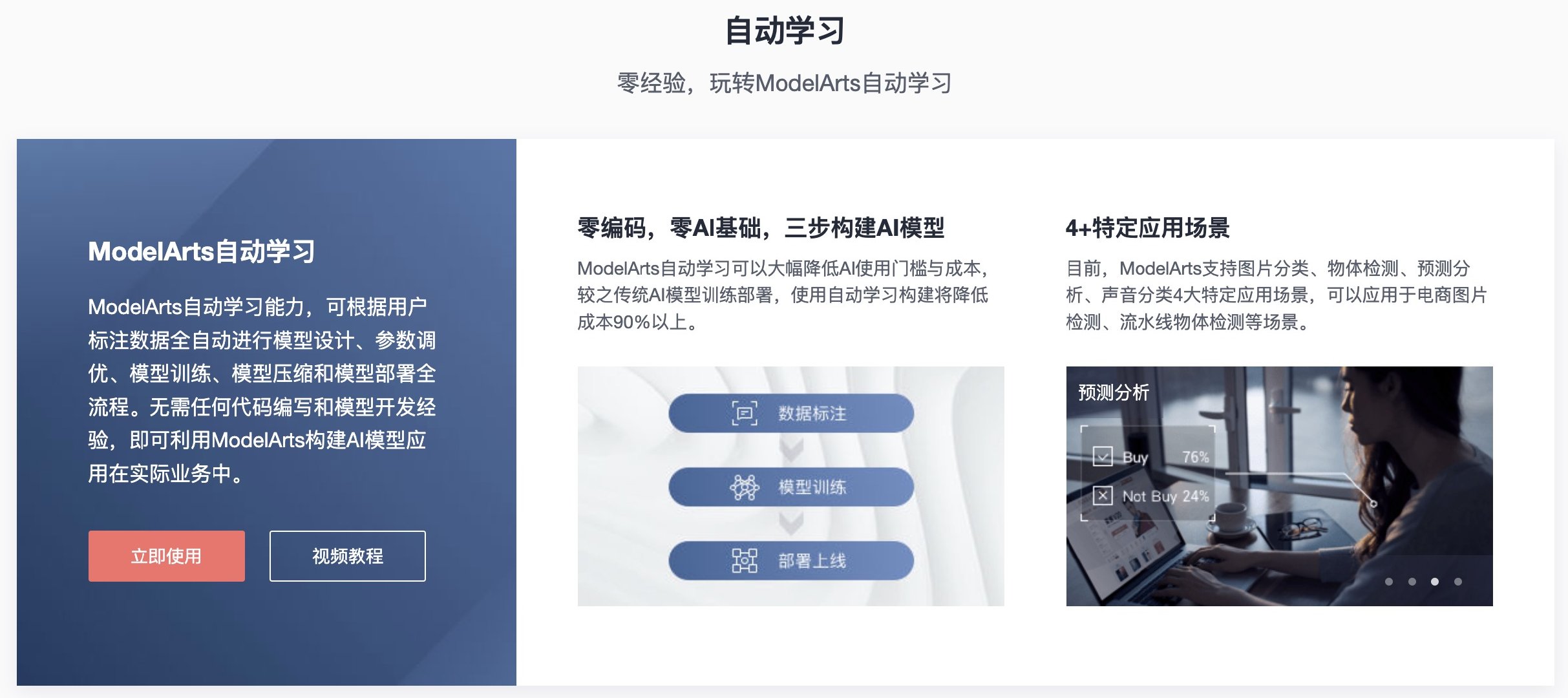

同时,它将 AI 开发的整个过程都集成了进来。例如数据标注、模型训练、参数优化、服务部署、开放接口等,这就是「全周期 AI 工作流」。

还有,平台上的操作都是可视化的。
这些条件对于想要将 AI 技术应用于产品,但无奈条件不佳的个人开发者和企业提供了机会,这很重要!可以说 ModelArts 缩短了 AI 商用的时间,降低了对应的经济成本、时间成本和人力成本。
更贴心的是,华为云 ModelArts 为用户准备了很多的教程。即使用户没有经验,但只要按照教程指引进行操作,也能够实现自己的 AI 需求。

想想就美滋滋,太棒了!
赶紧体验一下!
图像分类服务实践
这次我们以零 AI 基础和零编码经验的自动学习模式演示如何搭建一个图像分类的 AI 服务。
前期准备和相关设置
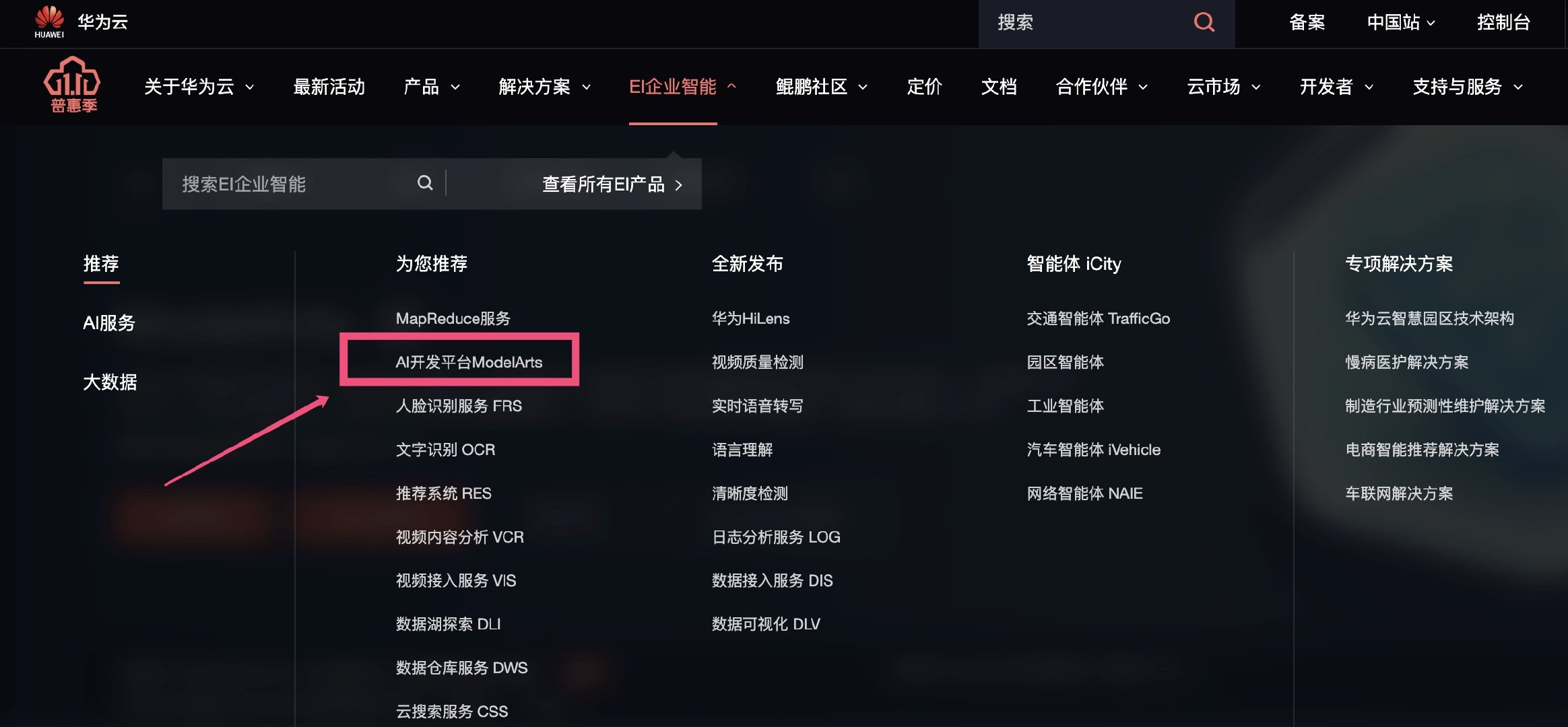
首先打开华为云官网,将鼠标移动导航栏的「EI 企业智能」菜单上,并在弹出的选项中选择「AI 开发平台 ModelArts」。
进入到 ModelArts 主页后,可以浏览一下关于 ModelArts 的介绍。
点击 Banner 处的「进入控制台」按钮,页面会跳转到 ModelArts 控制台。控制台大体分为几个区域:
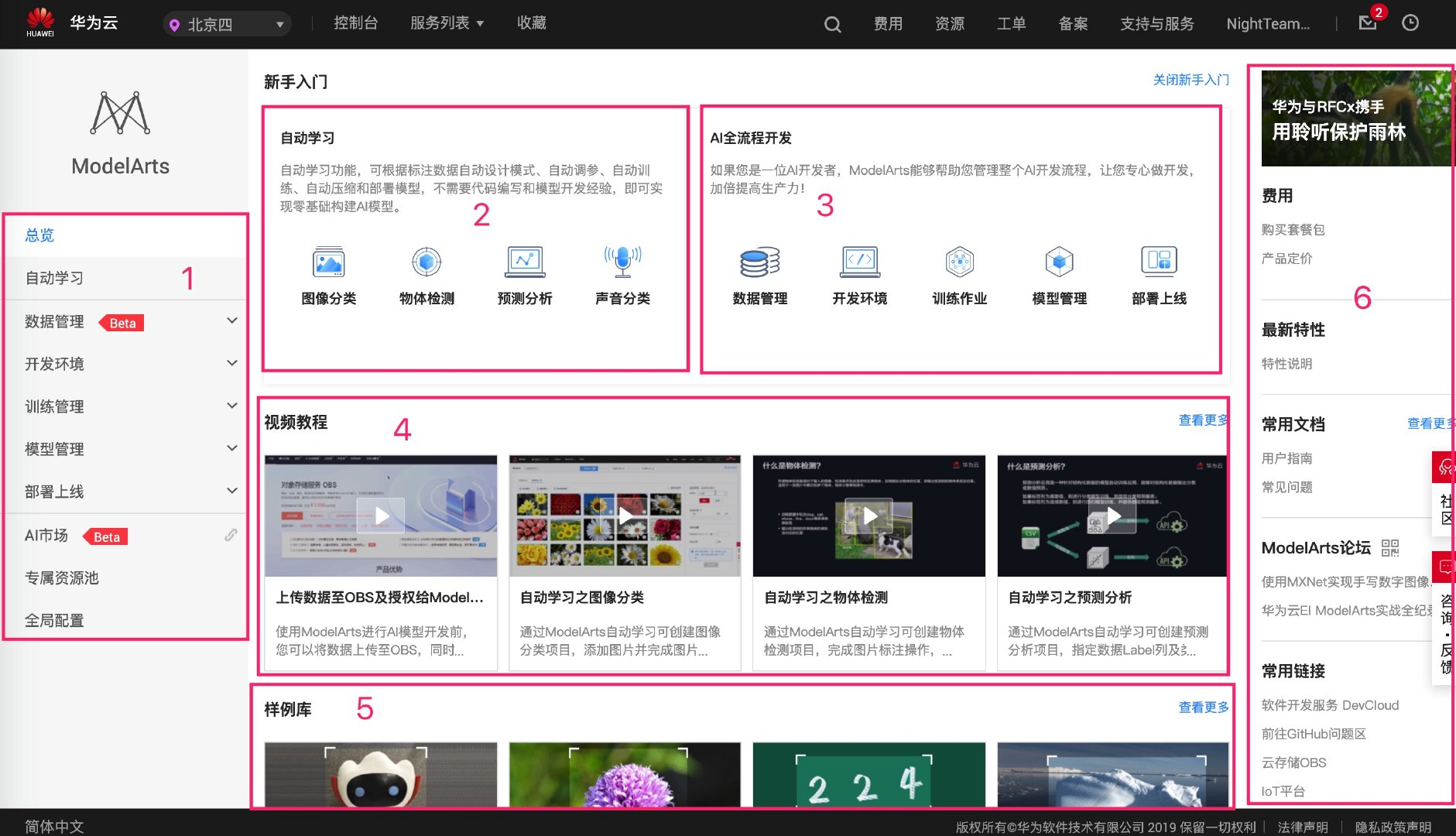
区域 2 自动学习模式中有图像分类,将鼠标移动到图标上,并点击弹出的「开始体验」按钮。如果是华为云的新用户,网页会提示我们输入访问密钥和私有访问密钥。
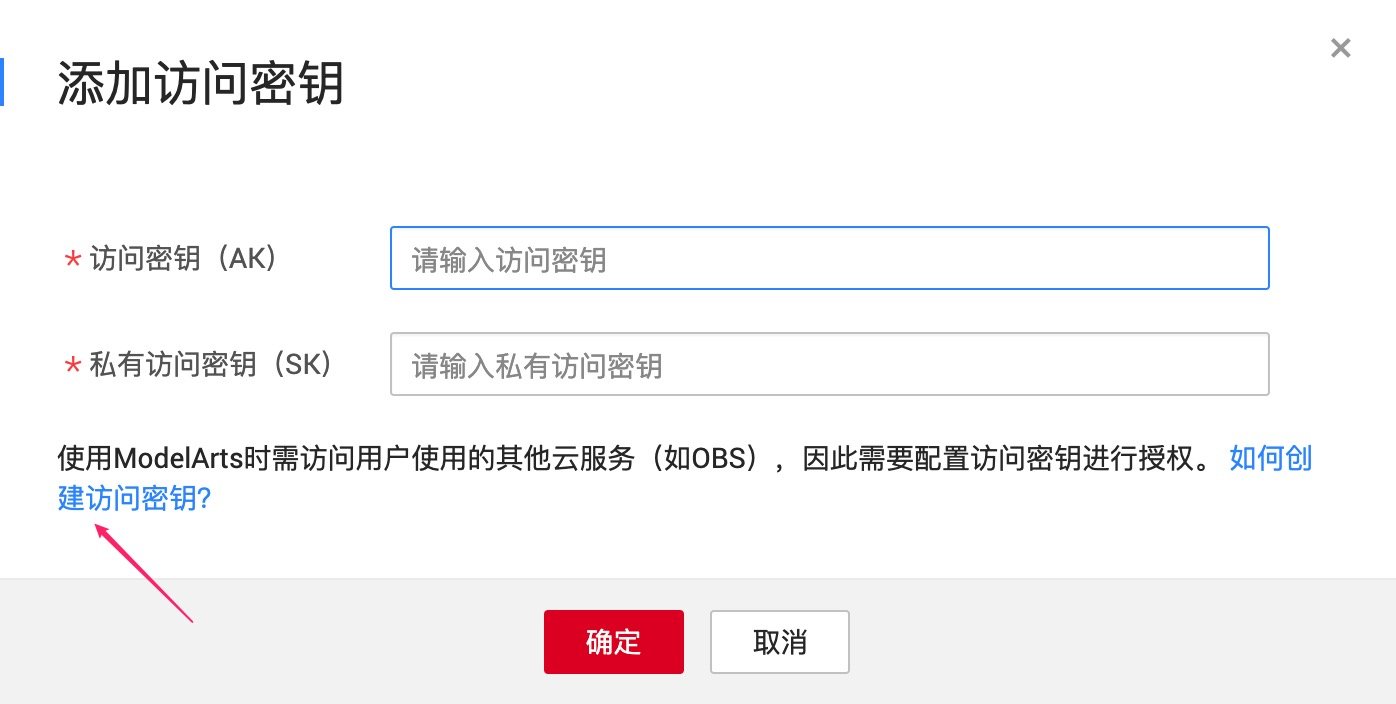
没有密钥的开发者可以点击页面给出的链接并按照指引获取密钥,得到两种密钥后将其填入框中,点击「确定」按钮即可。
此时正式进入项目创建流程中,点击「图像分类」中的「创建项目」按钮(华为云为用户准备了对应的教程,很贴心)。

在创建项目的页面中,我们需要填两三项配置。要注意的是,项目是按需计费的,这次我们只是体验,也没有训练和存储太多数据,所以费用很低,大家不用担心。
项目名称可以根据需求设定一个容易记的,案例中我将其设定为 ImageCLF-Test-Pro。在训练数据的存储选择处,点击输入框中的文件夹图标,在弹出的选项卡中新建 obs 桶
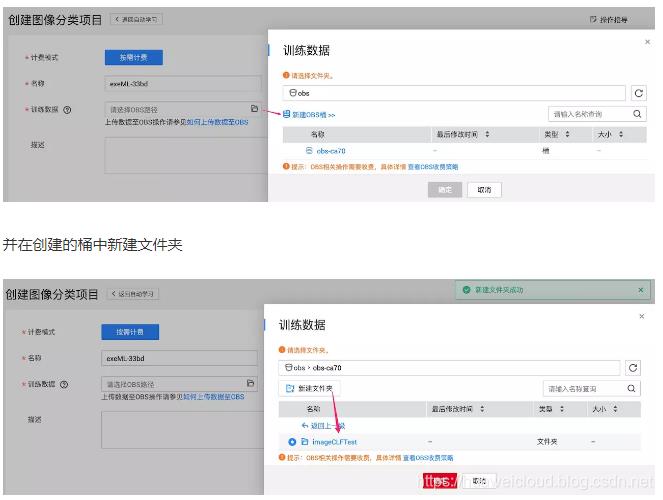
最后输入描述,并点击页面右下角的「创建项目」按钮即可。
上传图片和标注
项目创建好之后,我们需要准备用于训练的多张图片,图片尽量清晰、种类超过 2 类、每种分类的图片数量不少于 5 张。
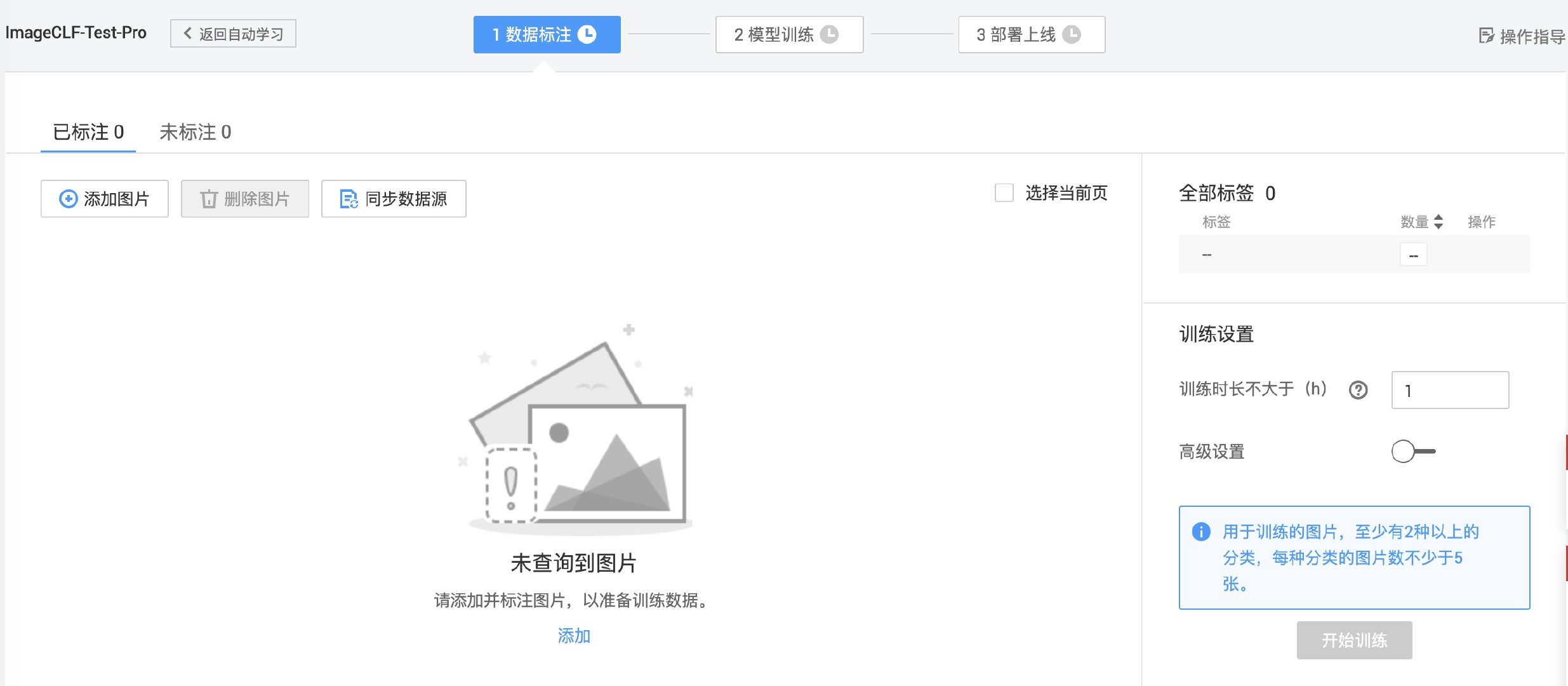
当然,数据越多、形态越丰富、标注越准确,那么训练结果就会越好,AI 服务的体验就会越好。
这里我准备了一些直升机、坦克和狗的图片,共 45 张。
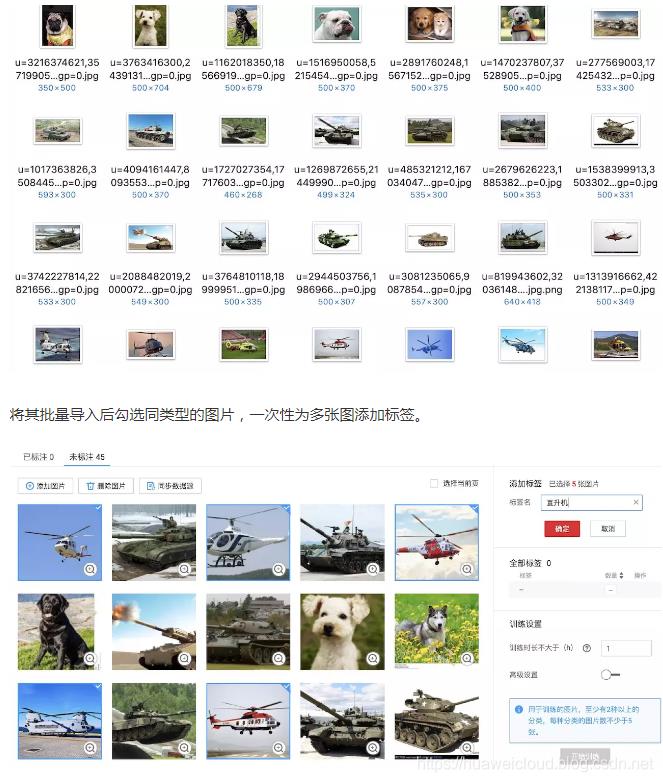
依次将 3 类图片标注后,左侧图片标注的「未标注」选项卡中的图就会清空,而「已标注」选项卡中可以看到标注好的图片。
训练设置
右侧的标签栏会显示每种分类和对应的图片数量,下方的训练设置可以让我们设置训练时长的上限,高级设置中还有推理时间。
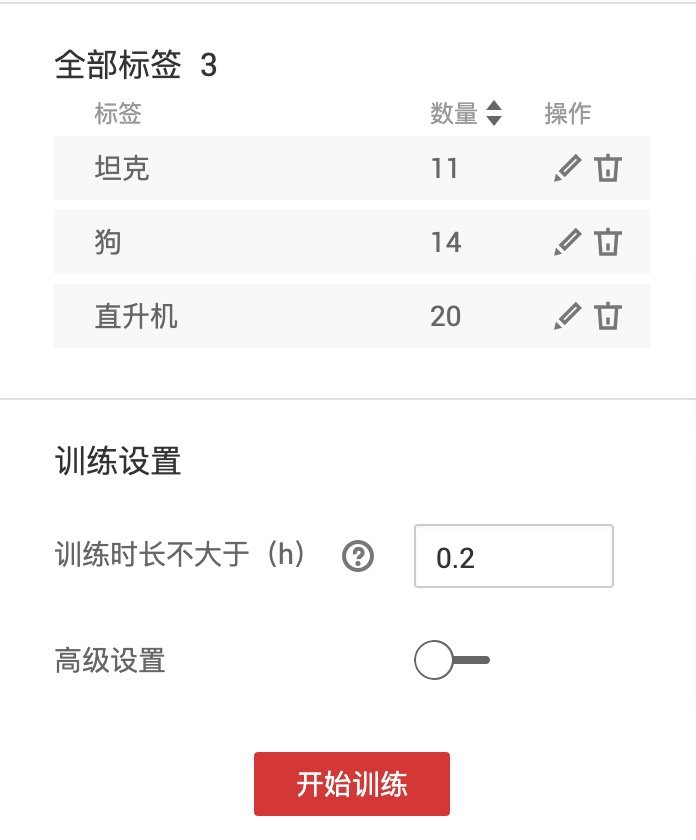
这个我们不必理解它的作用,可以按照默认值进行,也可以稍微调整,例如将训练时长的上限改为 0.2。
开始训练
设置好后点击「开始训练」按钮就会进入训练状态,耐心等待一段时间(图片越少训练时间越短)。
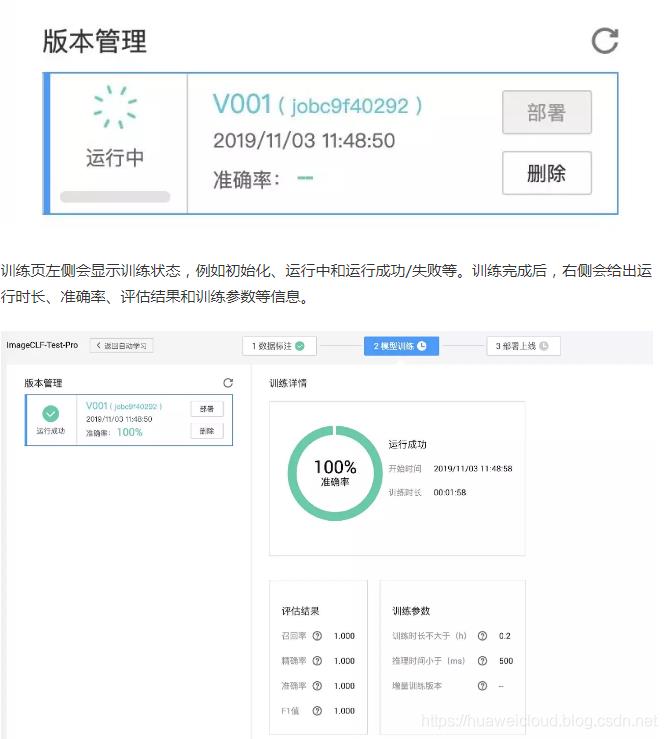
服务的自动化部署
我们的目的是搭建一个图像分类的 AI 服务,所以在训练结束后点击左侧的「部署」按钮,此时会进入自动化部署的流程。
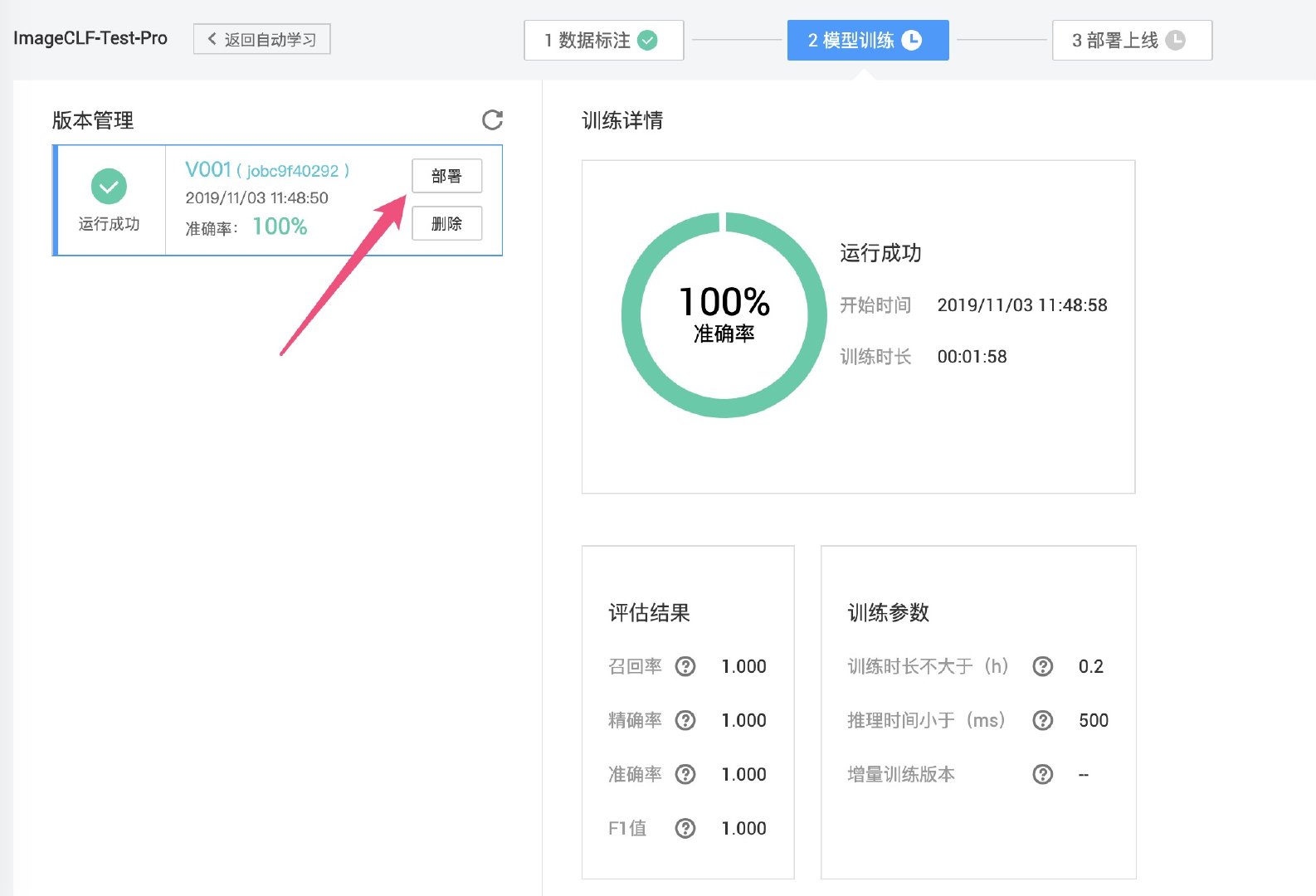
稍微等待些许时间(本次约 10 分钟)后,页面提示部署完成,同时页面将会分为 3 栏。
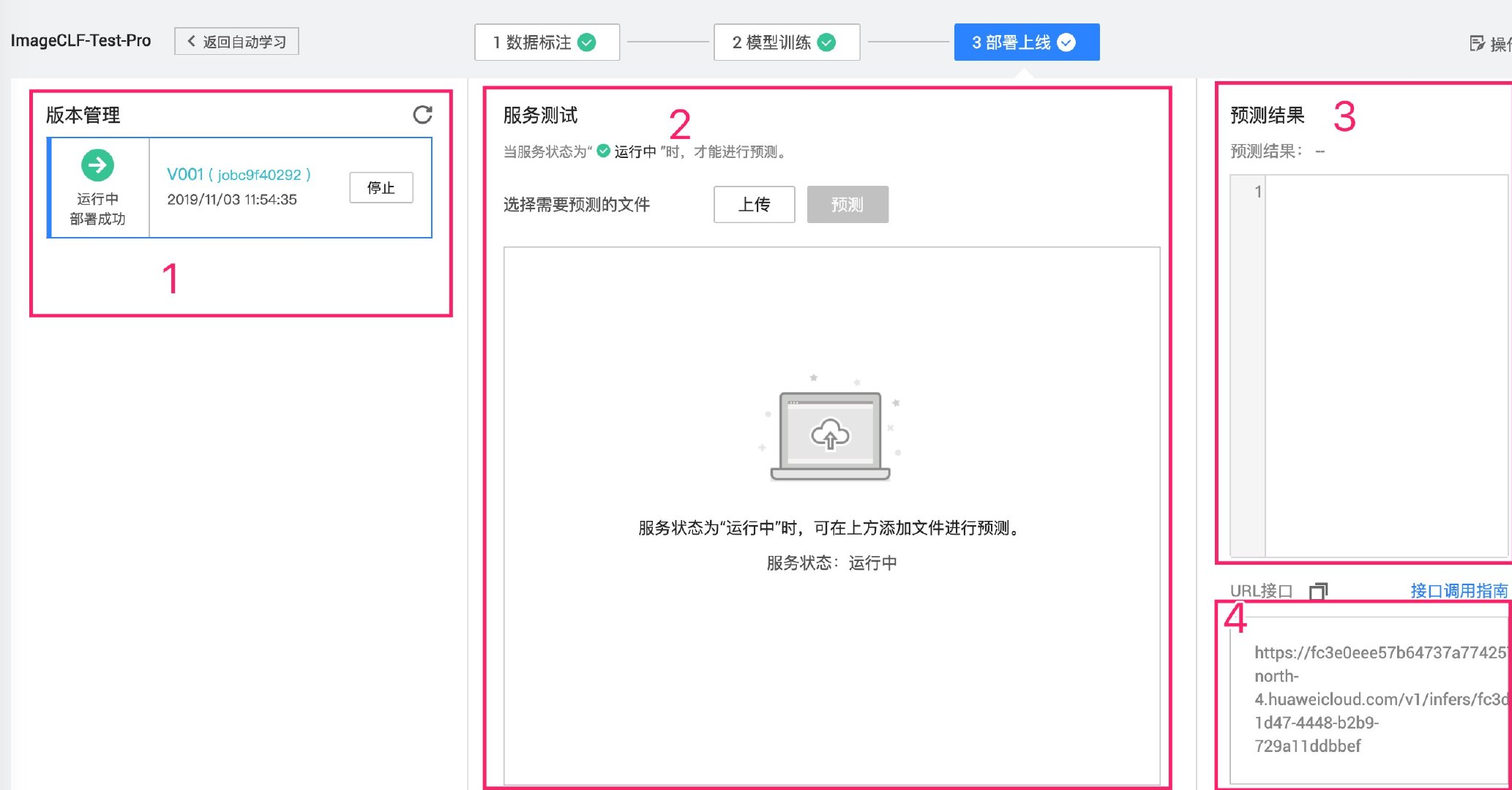
左侧 1 区为部署状态和控制。中间 2 区可以在线测试图片分类,右侧 3 区会显示在线测试的结果(包括准确率),右侧 4 区提供了 API 接口,方便我们将其集成到 Web 应用当中。
在线预测,训练结果测试
我们来测试一下,准备几张没有经过标注的图片,图片中可以包含狗、直升机和坦克。点击中间 2 区的「上传」按钮并选择一张图片,然后点击「预测」按钮。
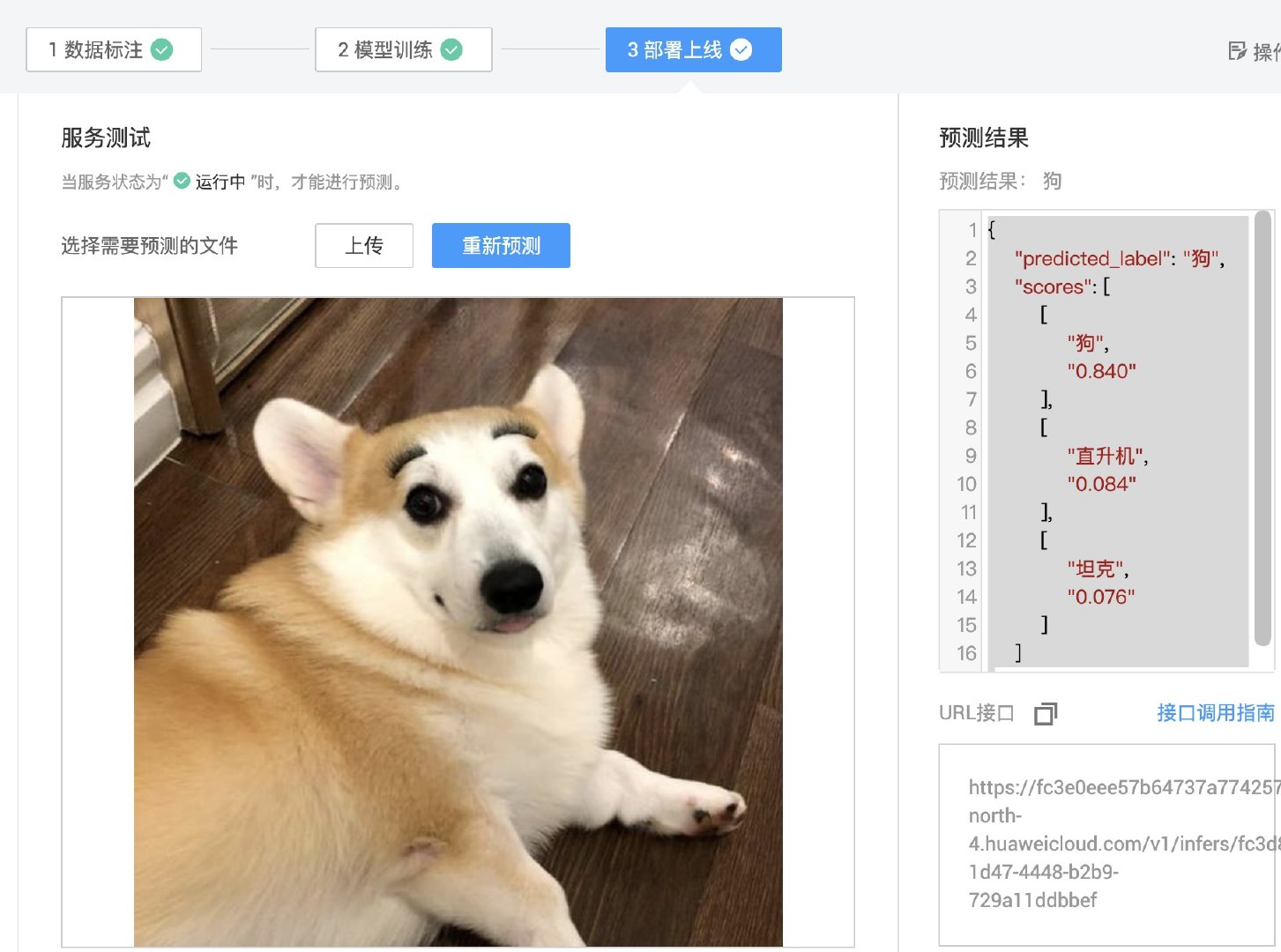
1 秒中不到,右侧 3 区就会返回本次预测的结果:
1 { 2 "predicted_label": "狗", 3 "scores": [ 4 [ 5 "狗", 6 "0.840" 7 ], 8 [ 9 "直升机", 10 "0.084" 11 ], 12 [ 13 "坦克", 14 "0.076" 15 ] 16 ] 17 }
这次我们上传的是包含狗的图片,返回的预测结果中显示本次预测的标签是「狗」,并且列出了可信度较高的几个类别和对应的可信度(1 为 100% 肯定),其中最高的是 「0.840-狗」。
这次上传直升机的图片试试。
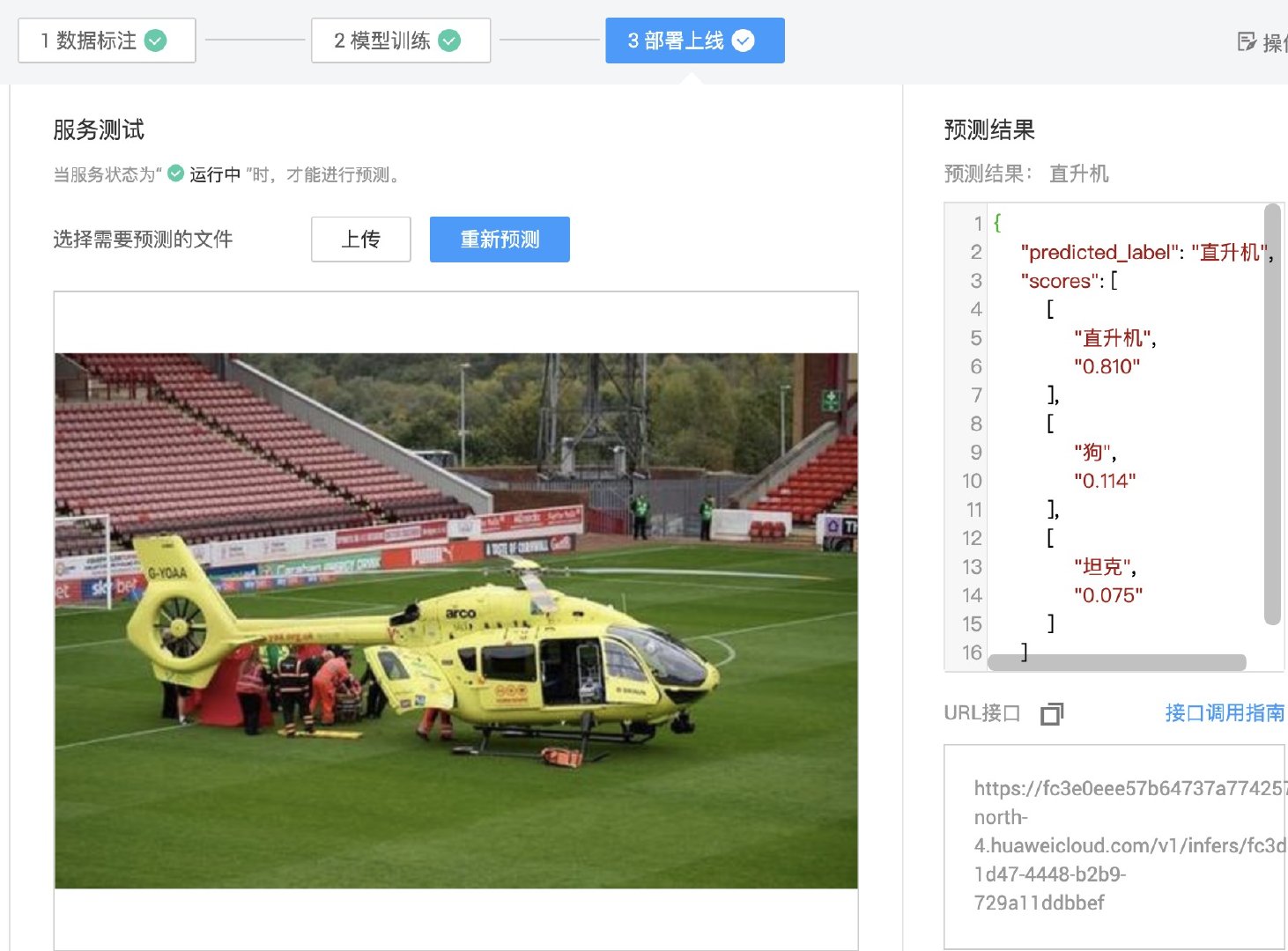
返回的预测结果如下:
1 { 2 "predicted_label": "直升机", 3 "scores": [ 4 [ 5 "直升机", 6 "0.810" 7 ], 8 [ 9 "狗", 10 "0.114" 11 ], 12 [ 13 "坦克", 14 "0.075" 15 ] 16 ] 17 }
再试试坦克
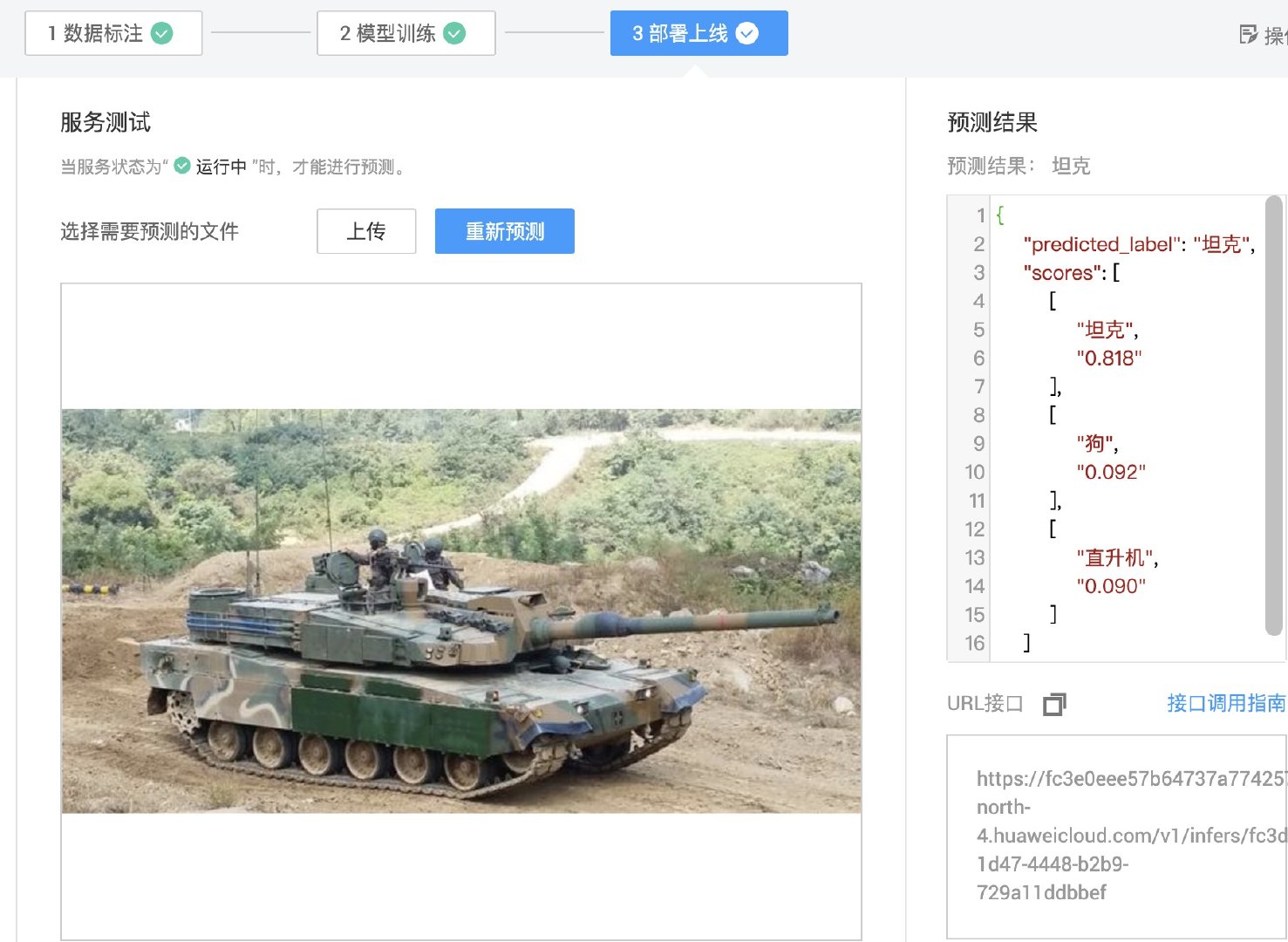
返回的预测结果如下:
1 { 2 "predicted_label": "坦克", 3 "scores": [ 4 [ 5 "坦克", 6 "0.818" 7 ], 8 [ 9 "狗", 10 "0.092" 11 ], 12 [ 13 "直升机", 14 "0.090" 15 ] 16 ] 17 }
从几次测试的结果可以看出,预测的结果非常准确,而且给出的可信度也比较高。这次准备的图片并不是很多,形态也不是很丰富,但预测效果却非常好,不得不说华为云 ModelArts 开发团队为此做了很多的优化,甚至比我自己(深度学习入门水平)编写代码用卷积神经网络训练和预测的结果要好。
如果想要将其集成到 Web 应用中,只需要根据页面给出的「接口调用指南」的指引进行操作即可。
释放资源
如果不是真正商用,仅仅作为学习和练习,那么在操作完成后记得点击左侧 1 区的「停止」按钮。然后在华为云导航栏中的搜索框输入「OBS」,点击搜索结果后跳转到 OBS 主页,接着再 OBS 主页点击「管理控制台」,进入到 OBS 控制台中,删除之前创建的桶即可。这样就不会导致资源占用,也不会产生费用了。
小结
体验了一下 ModelArts,我感觉非常奈斯!
每处都有提示或教程指引,操作过程流畅,没有出现卡顿、报错等问题。
批量数据标注太好用了!批量导入、批量标注,自动计数,舒服!
训练速度很快,应该是用了云 GPU,这样就算我的电脑没有显卡也能够快速完成训练。
以前还在考虑,学习 AI 是否需要准备更强的硬件设备,现在好了,在 ModelArts 上操作,就不用考虑这些条件了。
本次我们体验的是自动学习,也就是简洁易用的傻瓜式操作。对于专业的 AI 工程师来说,可以选择全流程开发模式。批量数据标注、本地代码编写、本地调试、云端训练、云端部署等一气呵成。
棒!
有兴趣的开发者可以前往华为云 ModelArts 体验。
备注:文中配图均出自互联网,通过搜索引擎而来。
HDC.Cloud 华为开发者大会2020 即将于2020年2月11日-12日在深圳举办,是一线开发者学习实践鲲鹏通用计算、昇腾AI计算、数据库、区块链、云原生、5G等ICT开放能力的最佳舞台。
欢迎报名参会(https://www.huaweicloud.com/HDC.Cloud.html?utm_source=&utm_medium=&utm_campaign=&utm_content=techcommunity)

以上是关于实战!轻松搭建图像分类 AI 服务的主要内容,如果未能解决你的问题,请参考以下文章
Serverless 实战:用 20 行 Python 代码轻松搞定图像分类和预测
PyTorch深度学习实战 | 搭建卷积神经网络进行图像分类与图像风格迁移
图像分类实战——使用EfficientNetV2实现图像分类(Pytorch)