PyTorch深度学习实战 | 搭建卷积神经网络进行图像分类与图像风格迁移
Posted TiAmo zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch深度学习实战 | 搭建卷积神经网络进行图像分类与图像风格迁移相关的知识,希望对你有一定的参考价值。

PyTorch是当前主流深度学习框架之一,其设计追求最少的封装、最直观的设计,其简洁优美的特性使得PyTorch代码更易理解,对新手非常友好。
本文为实战篇,介绍搭建卷积神经网络进行图像分类与图像风格迁移。
1、实验数据准备
本文中准备使用MIT67数据集,这是一个标准的室内场景检测数据集,一共有67个室内场景,每类包括80张训练图片和20张测试图片,大家可以登录http://web.mit.edu/torralba/www/indoor.html,在如图1所示的页面中,下载得到这个数据集。

■ 图1 MIT67数据集
将下载的数据集解压,主要使用Image文件夹,这个文件夹一共包含6700张图片,还有TrainImages.txt,包含67×80张训练集图像路径和它们的标签,以及TestImages.txt,包含67×20张测试集图像路径和它们的标签。
2、数据预处理和准备
主要介绍如何利用PyTorch构建需要的场景识别算法。我们采用一个标准的ResNet-50网络,基于ResNet结构,构建一个在MIT67数据集上可以解决室内场景分类任务的模型。
1●数据集的读取
首先需要将下载的数据集读入内存,读入路径和标签这些信息存在于两个.label文件中。读取完成后应该得到一个图片路径组成的数组和一个标签组成的数组。这一步可以根据机器上的路径进行读取。将读取的结果记为train_list, train_labels(test_list, test_labels)。
我们的最终目标是将输入组织成DataLoader的结构,这个结构中将图片像素矩阵与label一一对应并且随机排序,这也是能够被PyTorch框架作为输入的标准结构。可以通过将上一步得到的数组放入DataLoader的构造函数来自动生成这个类。

2●重载data.Dataset类
可以发现,在构造DataLoader的时候,第一个参数是MyDataset类对象,首先需要定义这个类。这个类是data.Dataset这个PyTorch框架中的数据类的继承,需要重写以下几个函数,其中尤其要注意使得__getitem__()方法可以返回tensor格式的预处理后的图像和标签。

3●transform数据预处理
PyTorch中利用torchvision中的transforms包对图像输入进行预处理,在上一步重载data.Dataset中可以找到这个函数。这个函数接受一个PIL图像,首先缩放到256×256×3,然后随机截取成224×224×3,这是为了保证训练集的多样性,然后转化成PyTorch运算所接受的tensor格式,最后进行数据标准化。

3、图像风格迁移
VGG模型是由Simonyan等人于2014年提出的图像分类模型,这一模型采用了简单粗暴的堆砌3×3卷积层的方式构建模型,并花费了大量的时间逐层训练,最终斩获了2014年ImageNet图像分类比赛的亚军。这一模型的优点是结构简单,容易理解,便于利用到其他任务当中。
VGG-19网络的卷积部分由5个卷积块构成,每个卷积块中有多个卷积(convolution)层,结尾处有一个池化(pooling)层,如图2所示。
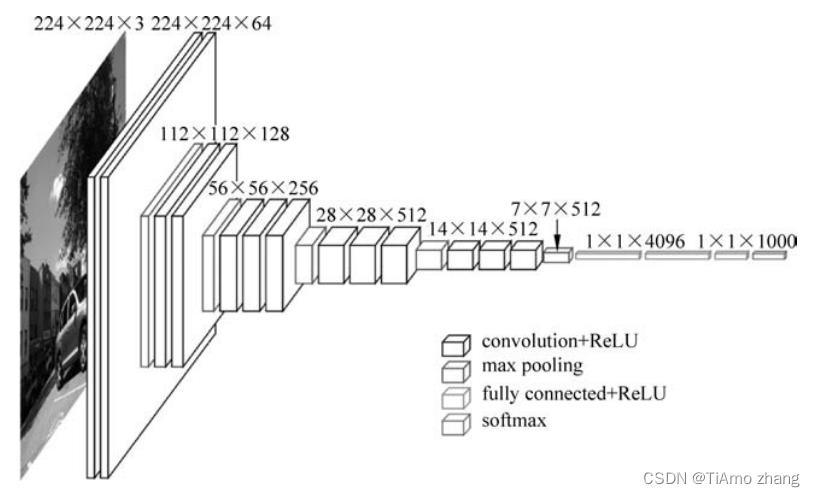
■ 图2 VGG-19的网络结构
卷积层中的不同卷积核会被特定的图像特征激活,图3展示了不同卷积层内卷积核的可视化(通过梯度上升得到)。可以看到,低层卷积核寻找的特征较为简单,而高层卷积核寻找的特征比较复杂。

■ 图3 VGG网络中部分卷积层内卷积核的可视化
4、图像风格迁移介绍
图像风格迁移是指将一张风格图Is的风格与另一张内容图Ic的内容相结合并生成新的图像。Gatys等人于2016年提出了一种简单而有效的方法,利用预训练的VGG网络提取图像特征,并基于图像特征组合出了两种特征度量,一种用于表示图像的内容,另一种用于表示图像的风格。他们将这两种特征度量加权组合,通过最优化的方式生成新的图像,使新的图像同时具有一幅图像的风格和另一幅图像的内容。
图4对风格迁移的内部过程进行了可视化。上面的一行中,作者将VGG网络不同层的输出构建风格表示,再反过来进行可视化,得到重构的风格图片;下面的一行中,作者将VGG网络不同层的输出构建内容表示,再反过来进行可视化,得到重构的内容图片。可以看到,低层卷积层提取的风格特征较细节,提取的内容特征较详细;高层卷积层提取的风格特征较整体,提取的内容特征较概括。

■ 图4 风格迁移中使用的风格数学表示和内容数学表示
5、内容损失函数
1●内容损失函数的定义
内容损失函数用于衡量两幅图像之间的内容差异大小,其定义如下。
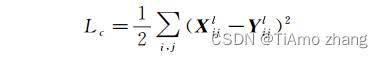
其中,Xl和Yl分别是两幅图片由VGG网络某一卷积层提取的特征图(feature map),l表示卷积层的下标,i和j表示矩阵中行与列的下标。可见两幅图像的内容损失函数是由特征图对位求差得到的。低层卷积特征图对图片的描述较为具体,高层卷积特征图对图片的描述较为概括。Gatys等人选择了第4个卷积块的第2层(conv4_2)用于计算内容损失,因为我们希望合成的图片的内容与内容图大体相近,但不是一笔一画都一模一样。
2●内容损失模块的实现
模块在初始化时需要将内容图片的特征图传入,通过detach()方法告诉AutoGrad优化时不要变更其中的内容。forward()方法实现上面的公式即可。

6、风格损失函数
1●风格损失函数的定义
风格损失函数用于衡量两幅图像之间的风格差异大小。首先需要通过计算特征图的Gram矩阵得到图像风格的数学表示。给定VGG在一幅图像中提取的特征图Xl,与之对应的Gram矩阵Gl定义如下。

Gram矩阵本质上是特征的协方差矩阵(只是没有减去均值),表示的是特征与特征(卷积核与卷积核)的相关性。
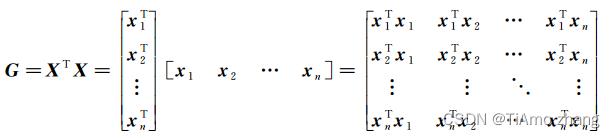
设由以上方式获得Xl和Yl对应的Gram矩阵Gl和Hl,风格损失函数定义如下。
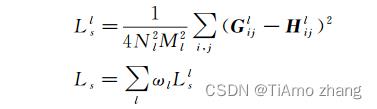
其中,Nl和Ml分别为特征图的通道数与边长,ωl为权重。Gatys等选择了conv1_1,conv2_1, conv3_1, conv4_1, conv5_1用于计算风格损失。
2●计算Gram矩阵函数的实现
因为PyTorch传入数据必须以批的形式,传入的input的大小为[batch_size, channels, height, width]。计算Gram矩阵时,先用view方法改变张量的形状,然后再将它与它自己转置进行点积即可。

3●风格损失模块的实现
模块在初始化时需要将风格图片的特征图传入并计算其Gram矩阵,通过detach()方法告诉AutoGrad优化时不要变更其中的内容。forward()方法实现上面的公式即可。

PyTorch深度学习实战 | 典型卷积神经网络

在深度学习的发展过程中,出现了很多经典的卷积神经网络,它们对深度学习的学术研究和工业生产都起到了巨大的促进作用,如VGG、ResNet、Inception和DenseNet等,很多投入实用的卷积神经都是在它们的基础上进行改进的。初学者应从试验开始,通过阅读论文和实现代码(tensorflow.keras.applications包中实现了很多有影响力的神经网络模型的源代码)来全面了解它们。下文简要讨论两个有代表性的卷积神经网络,它们都是卷积层、池化层、全连接层等的不同组合。
01、VGG-16,VGG-19
VGG-16[32]是牛津大学的Visual Geometry Group在2015年发布的共16层的卷积神经网络,有约1.38亿个网络参数。该网络常被初学者用来学习和体验卷积神经网络。
VGG-16模型是针对ImageNet挑战赛设计的,该挑战赛的数据集为ILSVRC-2012图像分类数据集。ILSVRC-2012图像分类数据集的训练集有总共有1281167张图片,分为1000个类别,它的验证集有50000张图片样本,每个类别50个样本。
ILSVRC-2012图像分类数据集是2009年开始创建的ImageNet图像数据集的一部分。基于该图像数据集举办了具有很大影响力的ImageNet挑战赛,很多新模型就是在该挑战赛上发布的。
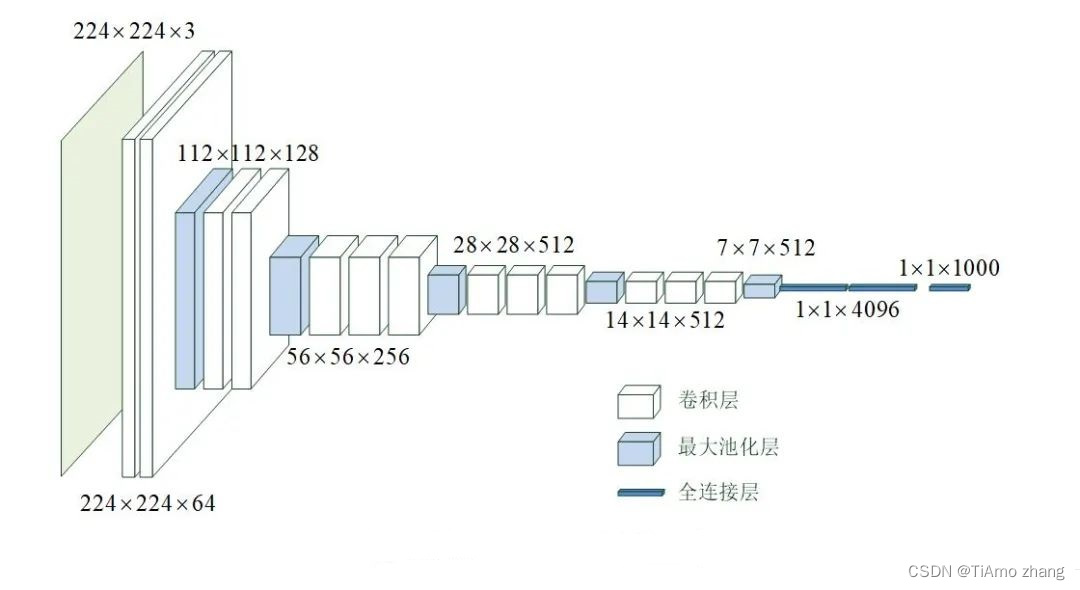
图 1 VGG-16模型的网络结构
VGG-16模型的网络结构如图1所示,从左侧输入大小为224×224×3的彩色图片,在右侧输出该图片的分类。
输入层之后,先是2个大小为3×3、卷积核数为64、步长为1、零填充的卷积层,此时的数据维度大小为224×224×64,在水平方向被拉长了。
然后是1个大小为2×2的最大池化层,将数据的维度降为112×112×64,再经过2个大小为3×3、卷积核数为128、步长为1、零填充的卷积层,再一次在水平方向上被拉长,变为112×112×128。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为256、步长为1、零填充的卷积层,数据维度变为56×56×256。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为512、步长为1、零填充的卷积层,数据维度变为28×28×512。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为512、步长为1、零填充的卷积层,数据维度变为14×14×512。
然后是1个大小为2×2的最大池化层,数据维度变为7×7×512。
然后是1个Flatten层将数据拉平。
最后是3个全连接层,节点数分别为4096、4096和1000。
除最后一层全连接层采用Softmax激活函数外,所有卷积层和全连接层都采用relu激活函数。
从上面网络结构可见,经过卷积层,通道数量不断增加,而经过池化层,数据的长度和宽度不断减少。
Visual Geometry Group后又发布了19层的VGG-19模型。
TensorFlow实现了VGG-16模型和VGG-19模型 。TensorFlow还提供了用ILSVRC-2012-CLS图像分类数据集预先训练好的VGG-16和VGG-19模型,下面给出一个用预先训练好的模型来识别一幅图片(图2)的例子。

图2 试验用的小狗照片
代码清单1 VGG-19预训练模型应用(vgg19_app.py)
1. import tensorflow.keras.applications.vgg19 as vgg19
2. import tensorflow.keras.preprocessing.image as imagepre
3.
4. # 加载预训练模型
5. model = vgg19.VGG19(weights='E:\\\\MLDatas\\\\vgg19_weights_tf_dim_ordering_tf_kernels.h5', include_top=True) # 加载预先下载的模型
6. # 加载图片并转换为合适的数据形式
7. image = imagepre.load_img('116.jpg', target_size=(224, 224))
8. imagedata = imagepre.img_to_array(image)
9. imagedata = imagedata.reshape((1,) + imagedata.shape)
10.
11. imagedata = vgg19.preprocess_input(imagedata)
12. prediction = model.predict(imagedata) # 分类预测
13. results = vgg19.decode_predictions(prediction, top=3)
14. print(results)
15. #[[('n02113624', 'toy_poodle', 0.6034094), ('n02113712', 'miniature_poodle', 0.34426507), ('n02113799', 'standard_poodle', 0.0124355545)]]可见,图片为toy poodle的概率最大,为0.6。
02、残差网络
随着网络层次的加深,训练集的损失函数可能会呈现出先下降再上升的现象,称为网络退化(degradation)现象。残差网络(ResNet)[33]提出了抑制梯度消散、网络退化来加速训练收敛的方法,克服了层数多导致的收敛慢、甚至无法收敛的问题,使网络的层数得以增加。
残差单元是残差网络的基本组成部分,它的特点是有一条跨层的短接。图3示例了一个残差单元。该单元有两条传递路径,除了常规的卷积、批标准化、激活处理路径外,还有一条跨层的直接传递路径。
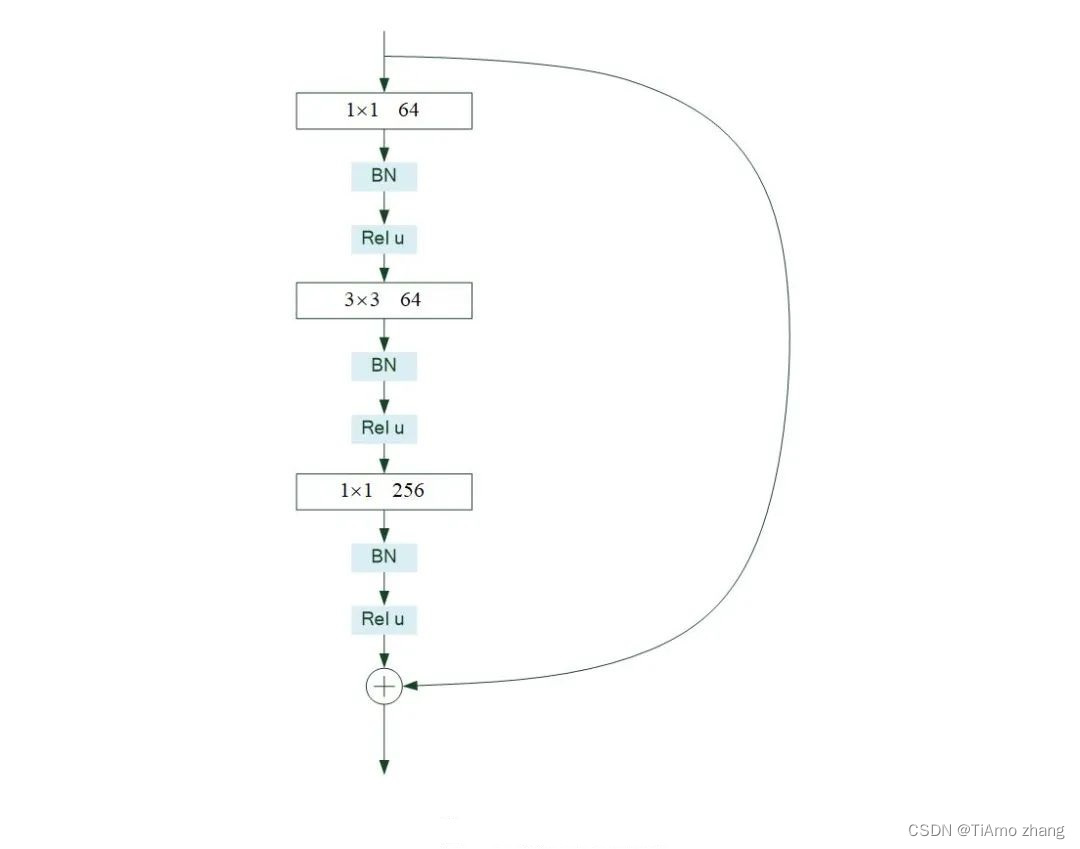
图3 残差单元示例
残差网络一般要由很多残差单元首尾连接而成。残差网络的思想是通过跨层的短接,在误差反向传播时,去掉不变的主体部分,从而突出微小的变化,使得网络对误差更加敏感。通过短接还使得误差消散问题得到了较好的解决。试验结果证明残差网络具有良好的学习效果。
图3所示残差单元在TensorFlow框架下的实现见代码清单2,其中第28行是将两条处理路径传来的数据相加。该代码来自tensorflow.keras.applications包,该包包含了许多经典模型的实现代码,值得读者仔细分析。
代码清单 2残差单元[1]
1. def block1(x, filters, kernel_size=3, stride=1, conv_shortcut=True, name=None):
2. bn_axis = 3 if backend.image_data_format() == 'channels_last' else 1
3. if conv_shortcut:
4. shortcut = layers.Conv2D(
5. 4 * filters, 1, strides=stride, name=name + '_0_conv')(
6. x)
7. shortcut = layers.BatchNormalization(
8. axis=bn_axis, epsilon=1.001e-5, name=name + '_0_bn')(
9. shortcut)
10. else:
11. shortcut = x
12. x = layers.Conv2D(filters, 1, strides=stride, name=name + '_1_conv')(x)
13. x = layers.BatchNormalization(
14. axis=bn_axis, epsilon=1.001e-5, name=name + '_1_bn')(
15. x)
16. x = layers.Activation('relu', name=name + '_1_relu')(x)
17. x = layers.Conv2D(
18. filters, kernel_size, padding='SAME', name=name + '_2_conv')(
19. x)
20. x = layers.BatchNormalization(
21. axis=bn_axis, epsilon=1.001e-5, name=name + '_2_bn')(
22. x)
23. x = layers.Activation('relu', name=name + '_2_relu')(x)
24. x = layers.Conv2D(4 * filters, 1, name=name + '_3_conv')(x)
25. x = layers.BatchNormalization(
26. axis=bn_axis, epsilon=1.001e-5, name=name + '_3_bn')(
27. x)
28. x = layers.Add(name=name + '_add')([shortcut, x])
29. x = layers.Activation('relu', name=name + '_out')(x)
30. return x03、源码展示
链接: https://pan.baidu.com/s/1kG88Z39otL7GrVhiSOJlqA?pwd=6yb8 提取码: 6yb8
以上是关于PyTorch深度学习实战 | 搭建卷积神经网络进行图像分类与图像风格迁移的主要内容,如果未能解决你的问题,请参考以下文章