k 近邻算法解决字体反爬手段|效果非常好
Posted huaweicloud
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k 近邻算法解决字体反爬手段|效果非常好相关的知识,希望对你有一定的参考价值。
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段。其高明之处在于,就算借助(Selenium 套件、Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容。
这种反爬虫手段通常被用来保护页面中的关键数据,例如影片票房、外卖平台的商家电话、汽车门户上的车型报价或者是电商平台上商品的属性和价格。
关于字体反爬虫的介绍、实现和原理可以参考书籍《Python3 反爬虫原理与绕过实战》,也可以通过搜索引擎查找资料,本篇文章不再赘述。
本篇文章要解决的问题,是如何让程序准确的识别那些用自定义字体代替的文字。
本文将围绕网站 aHR0cHM6Ly9tYW95YW4uY29tL2ZpbG1zLzEyMTgwMjk= 进行讨论,具体目标如下图:
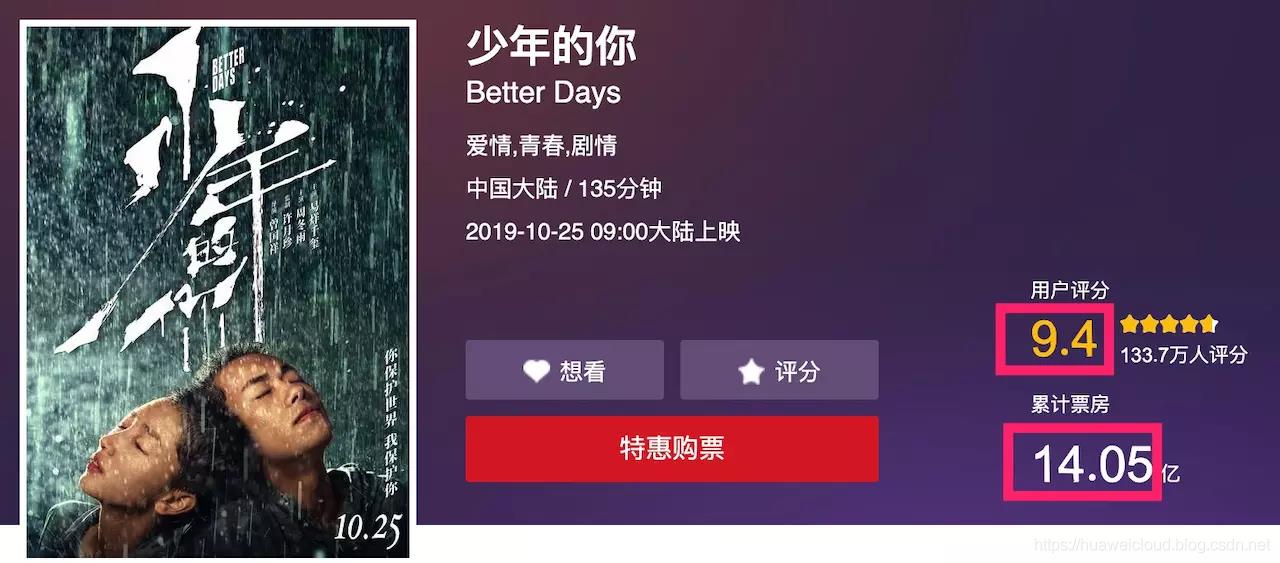
显然,页面中的用户评分、累计票房等内容是关键数据,它们也正是爬虫工程师们想要的东西。虽然人类的眼睛看到的是 9.4、14.05,但在浏览器开发者工具中它们却是 .?、?.??。9.4 对应的 html 代码为:
<span class="stonefont">.?</span>
而网页源代码中,却是另外一番景象:
<span class="stonefont">.</span>
有经验的朋友一眼就看出来了,这是字体反爬虫的手段!没有经验的朋友,请去阅读《Python3 反爬虫原理与绕过实战》。
这种字体反爬虫的破解思路为:
获取相关 CSS 文件中 ttf 或 woff 字体文件,通过 python 的 fontTools 模块建立字体对应关系。
但是当你分析本文给出的案例时,却发现页面使用的字体是实时动态变化的,无法建立确定的对应关系。这跟Python3 反爬虫原理与绕过实战》中提到的反爬虫思路很相似,很棘手!
但庆幸的是,遇到的字体反爬手段和《Python3 反爬虫原理与绕过实战》中介绍的不是完全相同的,有些手段并没有用上,还好还好。
接下来,将介绍基于深度学习中最简单的K-近邻算法来破解这种实时动态变化的字体反爬措施。先说一下破解的步骤:
- 将页面用到的字体文件下载到本地
- 通过字体编辑器查看该字体文件
- 观察字体文件随机动态的现象,并记录变化规律
- 得出变化规律的规则
以本文给出的案例网站为例,首先在浏览器开发者工具的 NetWork 一栏找到页面加载的字体文件(通常是 WOFF 格式),并将问价下载到本地。然后用字体编辑器(例如百度字体编辑器)查看字体文件,如下图:

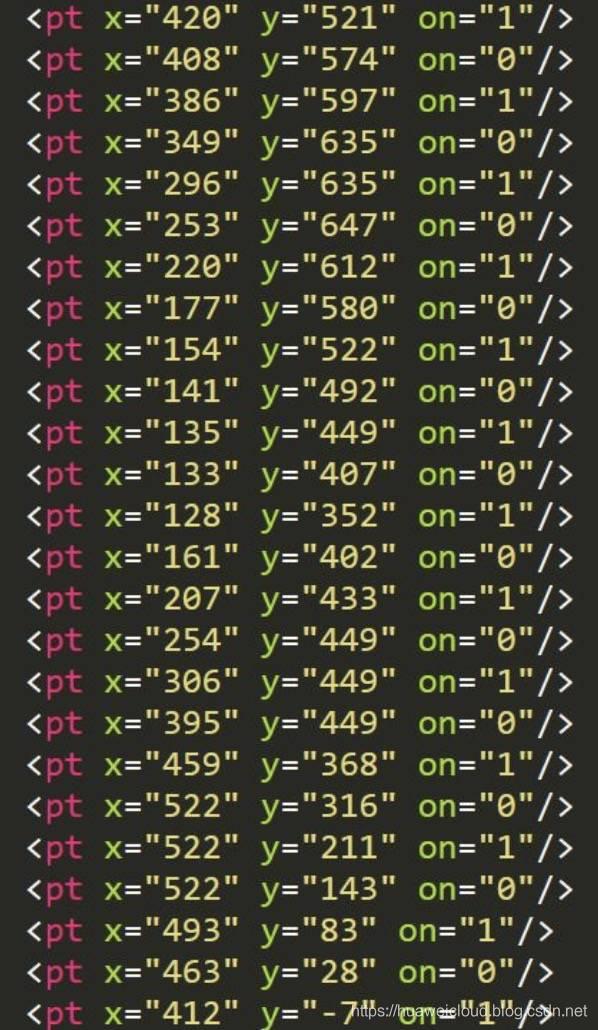
接着用 fontTools 库将 WOFF 格式的文件转换为 XML,并查看坐标变化规律。例如数字 6 对应的特殊字符为 uniF5DE,其对应的坐标值如下:
另一个字体文件中,数字 6 对应的坐标值如下:
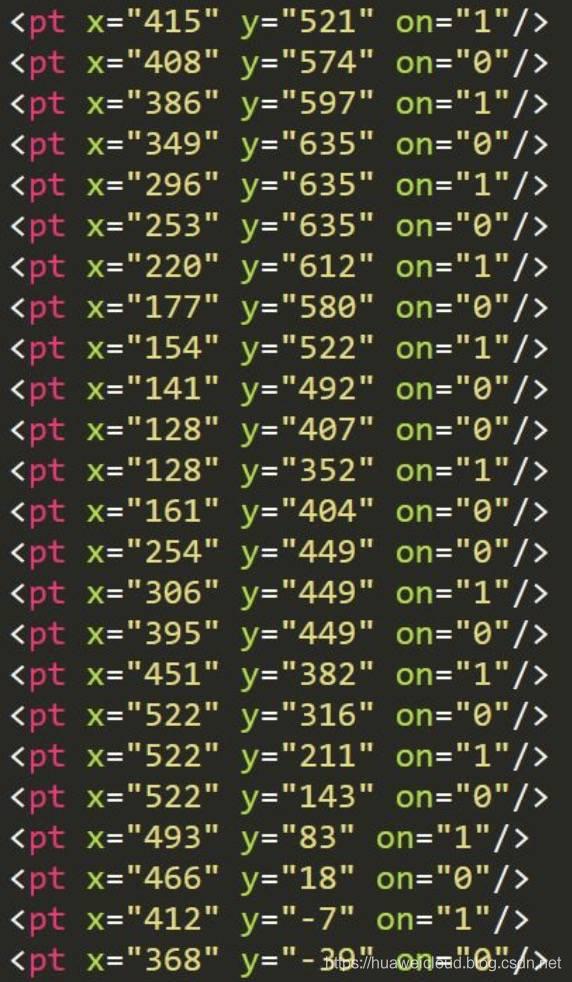
经过多次测试发现:同一数字的对象虽然不同,但是区别甚微,对象中每个坐标的差值较小。这样我们可以通过限定对象的坐标值差值在一定范围内就可以认为是两个相同的数字了。
接下来采用机器学习最简单的方法KNN算法经过简单的训练,即可将坐标分类。
那么什么是KNN算法呢?
简单的说,K-近邻算法采用策略不同特征值之间的距离方法进行分类。
工作原理:
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中 k 的出处,通常k是不大于20的整数。最后,选择 k 个最相似数据中出现次数最多的分类作为新数据的分类。
基于上述介绍,可以先制作一个样本数据集合,样本数据集合如下:

即从 XML 文件中提取相关数字的坐标。通过 KNN 算法,对输入的字体的坐标进行计算,标记其标签:
-
def classifyPerson(font):
-
# 完整代码将在文末获得
-
pass
通过 KNN 算法标记标签后,即可通过 replace 方法对源代码文件进行替换:
-
fonts = {}
-
for i in base_list:
-
# 完整代码将在文末获得
这里随意选取了多个目标地址,并验证了其正确输出,本文案例对应的数据如下:
{"电影名称": "少年的你", "用户评分": "9.4", "评分人数": "95.2 万", "累计票房": "7.32 亿"}
至此,字体反爬的问题就解决了。
更多关于字体反爬的思路和研究请翻阅《Python3 反爬虫原理与绕过实战》,本文中还有一些重要观点未提及,建议翻书补齐知识。
完整代码请关注微信公众号爬虫工程师之家,并回复 20191029,即可获得代码仓库的链接。
本文参考:
公众号爬虫工程师之家的文章《基于K-近邻算法,破解CSS动态混淆字体》
韦世东的新书《Python3 反爬虫原理与绕过实战》
HDC.Cloud 华为开发者大会2020 即将于2020年2月11日-12日在深圳举办,是一线开发者学习实践鲲鹏通用计算、昇腾AI计算、数据库、区块链、云原生、5G等ICT开放能力的最佳舞台。
欢迎报名参会(https://www.huaweicloud.com/HDC.Cloud.html?utm_source=&utm_medium=&utm_campaign=&utm_content=techcommunity)

以上是关于k 近邻算法解决字体反爬手段|效果非常好的主要内容,如果未能解决你的问题,请参考以下文章