机器学习 | 浅谈K-近邻算法
Posted qiutenglong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 | 浅谈K-近邻算法相关的知识,希望对你有一定的参考价值。
K-近邻(KNN)算法是解决分类问题的算法。既可以解决二分类,也可以解决多分类问题。
其实它也可以解决回归问题。
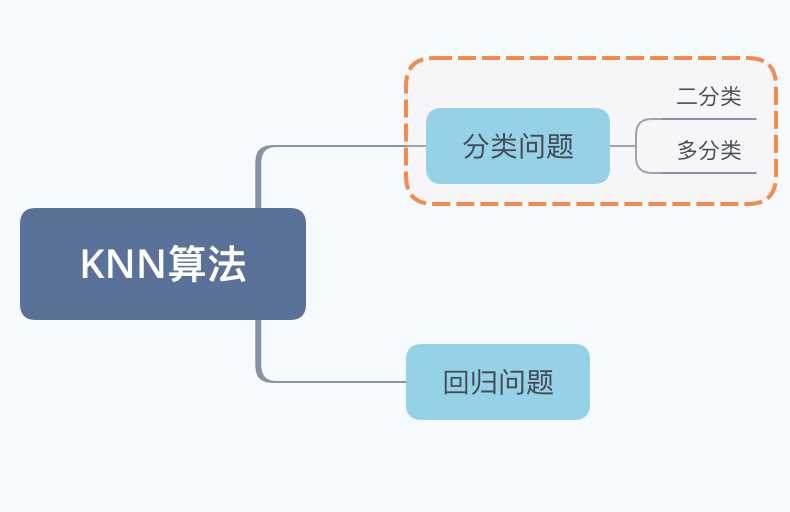
K-近邻原理:
某个样本的类别,由与之最相近的K个邻居投票所决定。
例子:
现在有一个样本集,其中所有数据都已经标记好类别,假设有一个未知类别的样本x需要进行分类。
在离这个样本距离最近的K个样本中,统计各个类别的占比。假设k=5时,计算出哪5个样本离未知样本x最近,
然后统计它们的类别,如在这5个样本中,有2个属于类别A,3个属于类别B。由于类别B的占比比较高,
所以得出样本x属于类别B。
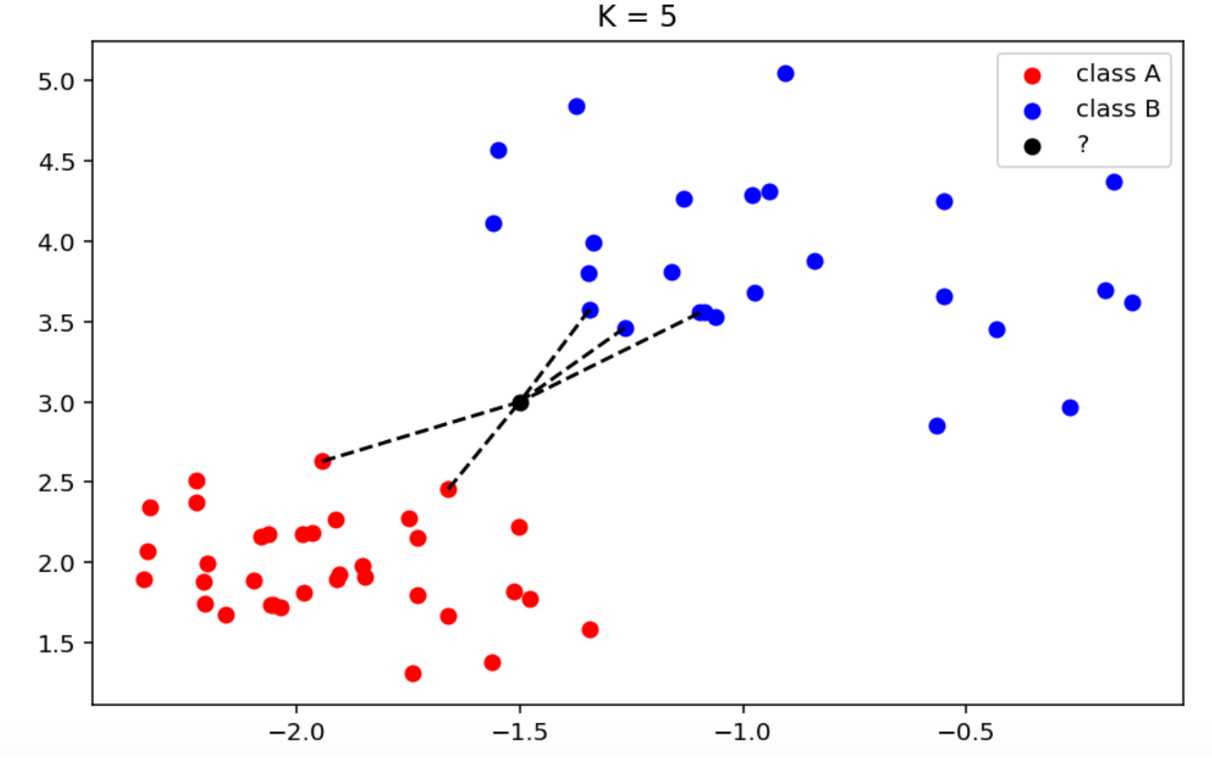
如图:
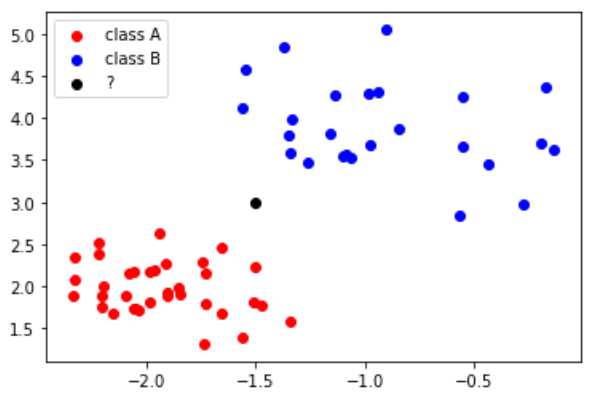
红点的类别为class A ,蓝点的类别为class B,黑点表示需要预测类别的样本x。
通过Knn算法,当k=5时:
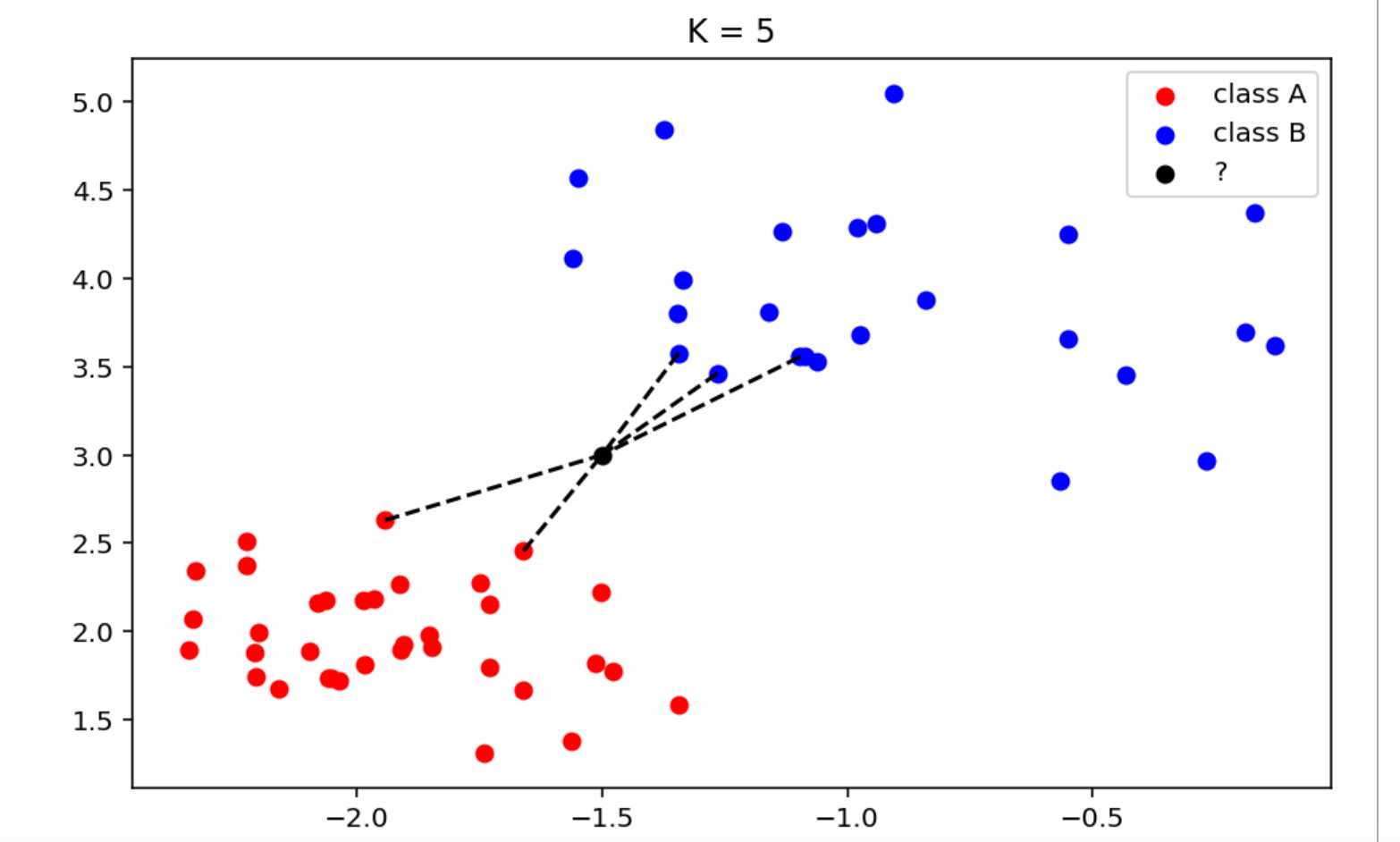
离黑点(样本x)最近的5(K所决定)个样本中,有3个蓝点,2个红点。所以可判定黑点和蓝点属同一个类别,为class B
既然K的取值决定了取K个邻居进行投票。那么当K取其他值,又是什么情况呢?
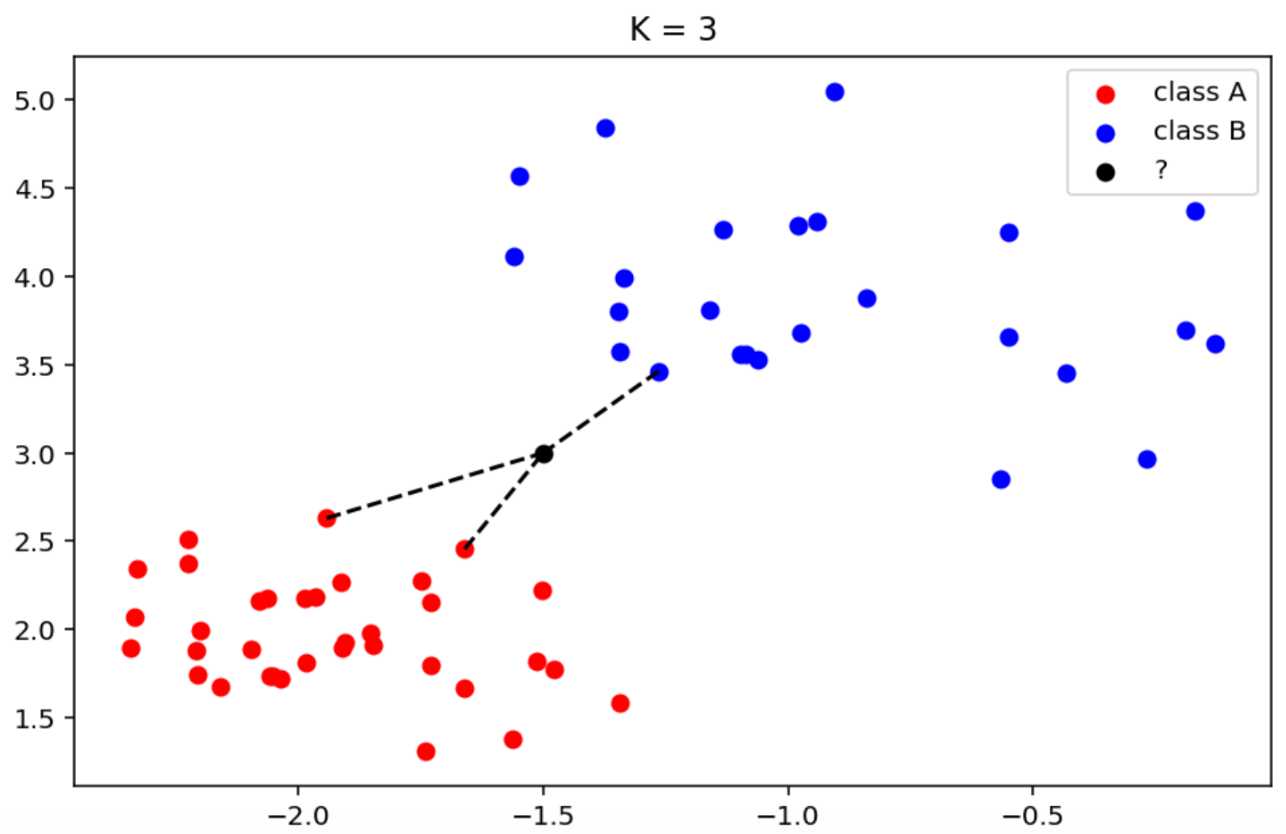
(另一种情况)当k=3时:
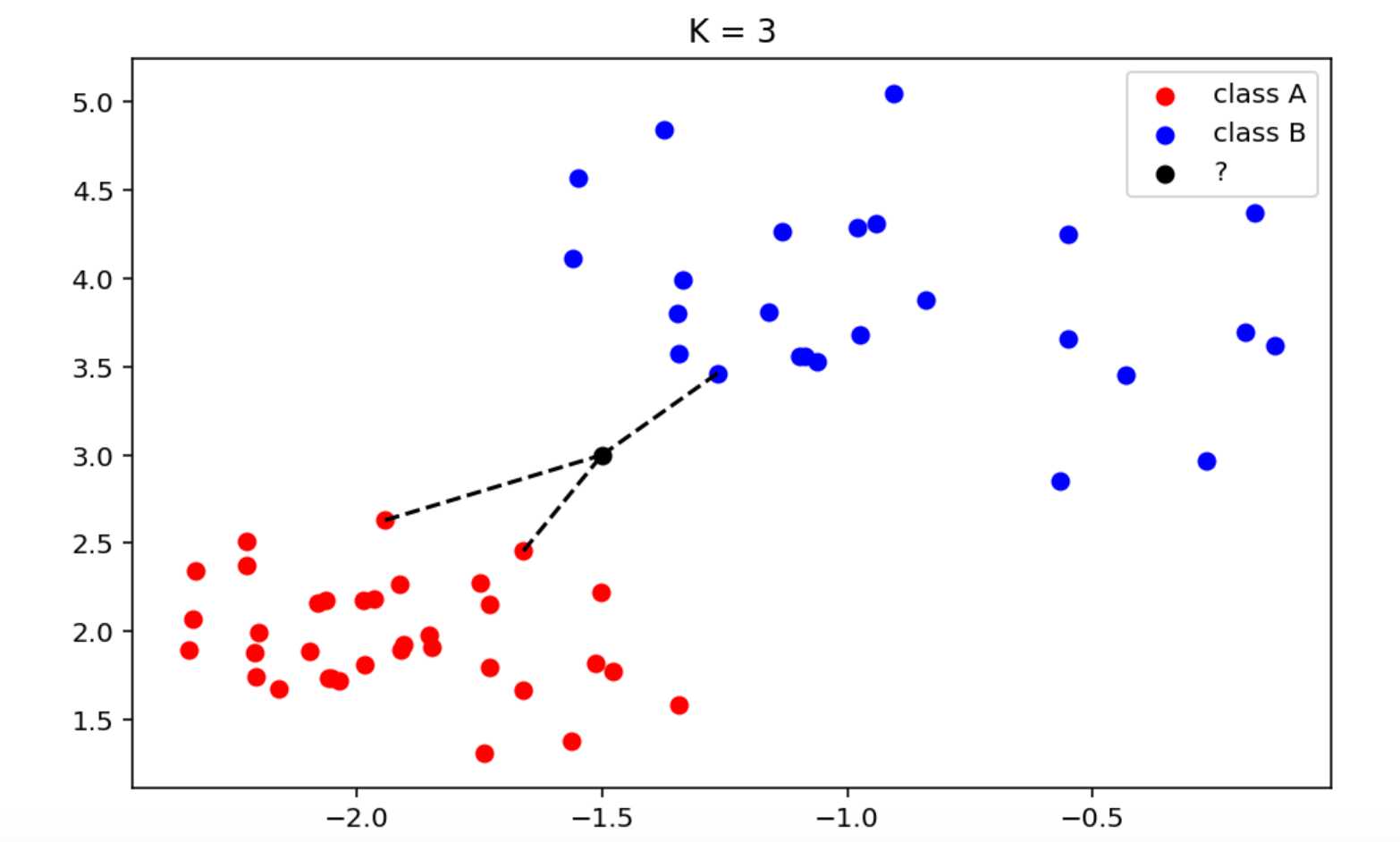
此时离黑点最近的3个邻居中,2个红点,1个蓝点,因此红点占比高,所以可以判定黑点和红点一样属于class A类别
通过对比可知:
在K-近邻中,K的取值影响了最终预测的结果。
K-近邻伪代码:
1.遍历训练集所有样本,计算每个样本与样本x之间的距离,保存所有距离
2.对这些距离进行排序(升序),取出k个最近的样本
3.对k个样本的类别进行统计,找出占比最高的类别
4.待标记样本的类别就是占比最高的类别
以上是关于机器学习 | 浅谈K-近邻算法的主要内容,如果未能解决你的问题,请参考以下文章