CVPR2018PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation
Posted xiaoaoran
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2018PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation相关的知识,希望对你有一定的参考价值。
又一篇3D点云detection的顶会。这篇文章是two stage的方法,非end-to-end。文章的前提是利用faster rcnn得到2D图像的image crop;然后才是本文介绍的PointFusion,即将image crop和对应的3D点云数据作为输入,得到3D box。可以说这篇文章实际2D检测基础上做3D检测。
整个模型如图:
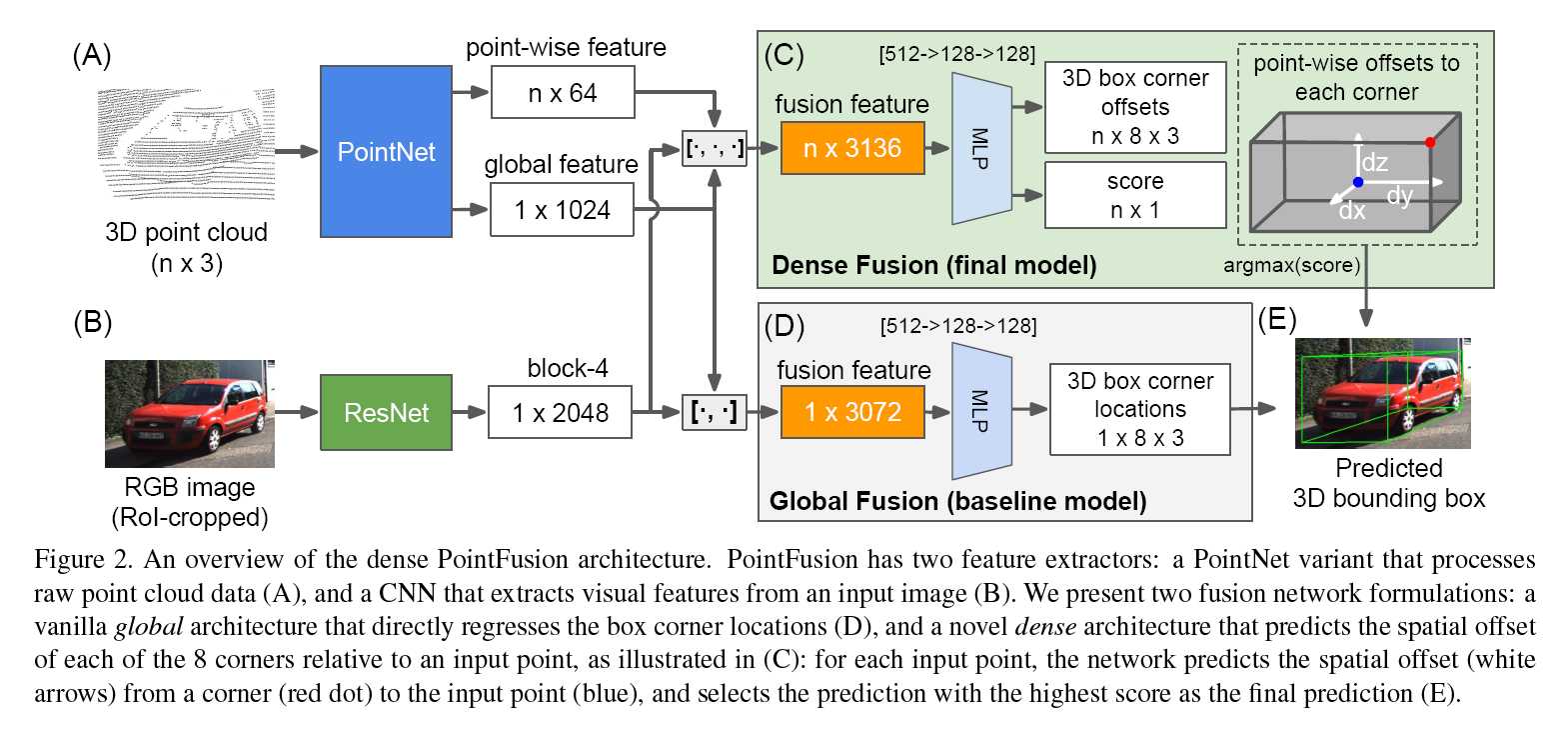
- 输入:2D 图像块(fatser RCNN检测结果);对应的3D点云
- 模型:
- 特征提取:
- 2D图像用预训练的ResNet50提取2048d的特征
- 用多个PointNet网络(去除BN层)提取1024d的全局特征($1024 imes1$)和每个点的64d特征($64 imes n$)
- 特征融合
- Global Fusion (baseline model)初始版本
- 将2D的2048d全局特征和3D的1024d全局特征concatenate到一起得到3072d的特征($3072 imes1$)
- 3072d经过一个MLP
- 输出:3D box 8个角点的x,y,z坐标($1 imes8 imes3$)
- Dense Fusion (final model)最终版本
- 每个点的64d特征+2048d2维特征+1024d三维全局特征concatenate到一起,得到$n imes2126$维特征。
- 经过MLP之后,两个branch:
- 输出$n imes2$,即每个点做2分类,判断该点是否在target bounding box中
- 输出$n imes8 imes3$,即每个点分别在x,y,z方向输出偏置(offset),即该点在三个坐标方向上离8个角点的距离。
- Global Fusion (baseline model)初始版本
- 特征提取:
以上是关于CVPR2018PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation的主要内容,如果未能解决你的问题,请参考以下文章
视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
Paper | Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform