Constrained Image Splicing Detection and Localization With Attention-Aware Encoder-Decoder and Atrou
Posted qina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Constrained Image Splicing Detection and Localization With Attention-Aware Encoder-Decoder and Atrou相关的知识,希望对你有一定的参考价值。
出处: IEEE Access Digital Object Identifier,2020
作者:刘亚奇
摘要
解决 CISDL 约束图像拼接检测定位问题,在 DMAC 基础上,加入 self-attention ,称为attentionDM
网络结构
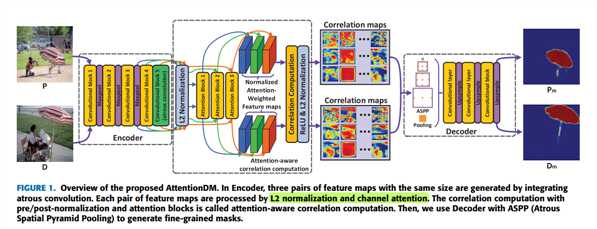
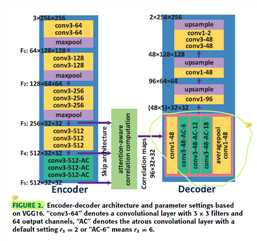
如图1 ,采用 encoder-decoder 结构。
encoder 部分采用了 VGG 结构的变体,去掉了 VGG 最后两个 maxpool 层,把 concolutional block 5 替换成 atrous convolution 。采用 skip architecture 分别输出三组大小相同的 feature map ,记作 (F_{3}) 、(F_{4}) 、(F_{5})
attention-aware correlation computation 部分包括 attention block ,normalization operations 和 correlation computation ,输出 correlation maps
decoder 部分采用了 ASPP 结构,经过卷积和上采样输出最终mask
L2 noralization
L2 范数:向量元素的平方和再开平方
L2 归一化:向量除以它自己的L2范数
目的: 把数据限定在一定的范围内
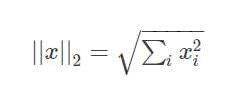
某层输出的 feature map 记作(F^{(1)}) (F^{(2)}) ,对于 (vec f^{(1)}(i_1,j_1)in F^{(1)}), (vec f^{(2)}(i_2,j_2)in F^{(2)}) 进行归一化 ,如公式4
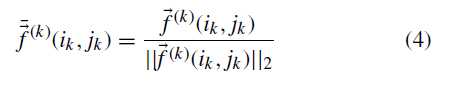
得到归一化后的特征图 (overline{F}^{(1)}) (overline{F}^{(2)}) , (overline{F}^{(1)}) (overline{F}^{(2)}) , (overline{F}^{(1)}) (overline{F}^{(2)})
channal attention block
目的:不同层的特征图分配注意力 ,关注细节信息
?
归一化后的特征图 (overline{F}^{(k)}inmathbb{R}^{h imes w imes c}) ,如: (overline{F}^{(1)})
展开成 (overline{F}^{k}_{flat}inmathbb{R}^{d imes c}) , d=h×w ,如:(overline{F}^{k}_{flat})
输入 embedding network 来提取高阶低维特征
embedding network:目的:降维 论文参考A structured self-attentive sentence embedding
公式 2 如下,经过三层神经网络前向传播
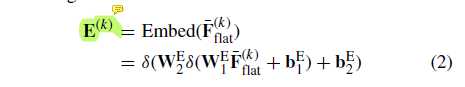
其中
(W^{E}_{1}inmathbb{R}^{frac{d}{r} imes d}) , (W^{E}_{2}inmathbb{R}^{frac{d}{r^{2}} imes frac{d}{r}}) 是参数矩阵,r 是 reduction ratio ,本文 r=4
(b^{E}_{1}inmathbb R^{frac{d}{r}}) , (b^{E}_{1}inmathbb R^{frac{d}{r^{2}}}) 是对应的 bias
(delta) 是 relu 函数
计算得到embeded feture (E^{(k)}inmathbb{R}^{frac{d}{r^{2}} imes c}) ,如: (E^{(k)})
再根据图1b
和公式3 ,两层前向传播加 softmax
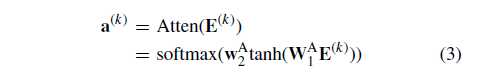
其中
(W^{(A)}_{1}inmathbb{R}^{frac{d}{r^{3}} imes frac{d}{r^{2}}}) , (W^{(A)}_{2}inmathbb{R}^{frac{d}{r^{3}}})
得到权重向量 (a^{(k)}inmathbb{R}^{c}) ,如:(a^{(k)})
然后公式5
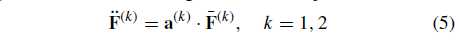
根据权重为 (overline{F}^{(1)}) 分配注意力 ,得到 (ddot{F}^{(1)})
从而得到图1 的 normalized attention-weighted feature maps
correlation computation
使用点积计算 (ddot{F}^{(1)}) (ddot{F}^{(2)}) 相关性,如公式6
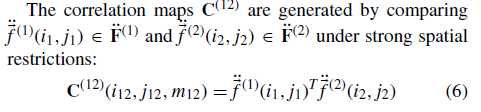
得到 correlation maps ,再进行 avgpool 、maxpool 、srtpool (公式8、9、10),拼接得到
相关性计算总过程记作公式11
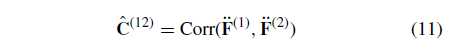
得到 (ddot{F}^{(1)}) (ddot{F}^{(2)})?的相关性 (widehat{C}^{(12)}) (widehat{C}^{(11)}) (widehat{C}^{(21)}) (widehat{C}^{(22)}) (按DMAC说,分别是8维),再把两两拼接,得到本层的相关图 (C^{(1)}) (C^{(2)}) (按DMAC,分别是16维)
再把三层的 (C^{(1)}) (C^{(1)}) (C^{(1)}) 拼接 (按DMAC,分别是48维,然后直接输入了ASPP)
然后进行 relu 函数和 L2 归一化
终于得到 (I^{(1)})对应的特征图(overline{C}^{(1)})
整个 attention-aware correlation computation 计算过程如算法1

这里第 20、21 行,(C^{(1)}) (C^{(2)})就是 DMAC 的 ASPP 的输入,其中(C^{(1)}_{l}) 是16维,所以(C^{(1)}) (C^{(2)}) 分别是48维。
经过卷积后,输出的维数 = 卷积用的 fiters 的数量 ,我推测为96个
ASPP
目的 获取多尺度特征
atrous rate ={6,12,18},然后把结果拼接,再输入卷积和上采样,恢复高分辨率,生成mask
图2是encoder-decoder 示意图
实验
datasets
训练: 自己合成的synthetic testing foreground pairs ,划分为难中易三个子集,每个子集3000对图像
测试: the paired CASIA dataset、The MFC2018 dataset、 The PS-Battles dataset
metrics
IoU
MCC
NMM
实验环境
with Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz, 64GB RAM and a single GPU (TITAN X)
analysis
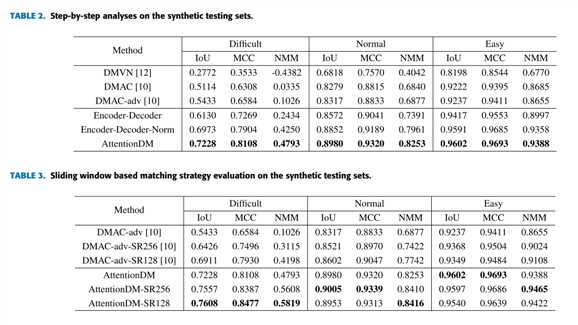
表2是对比试验,第三行分别表示直接使用特征进行相关性计算、加入归一化、加入注意力,可见attentionDM效果好
表3是滑动窗口实验,可见加入滑动窗口对 attentinDM 没有太大作用,因为attention相比于DMAC已经提高了网络对于小窗口的检测能力
?
?
作者又进行了 resnet 作为提取器和 VGG 的对比试验,结果发现使用 resnet 可以把性能提升一点点,但是参数量增长太多了,所以不建议用 resnet 做提取器
以上是关于Constrained Image Splicing Detection and Localization With Attention-Aware Encoder-Decoder and Atrou的主要内容,如果未能解决你的问题,请参考以下文章
python 笔记 size-constrained-clustering (对类别大小做限制的聚类问题)
带约束进化算法问题分析Constrained Evolutionary Algorithms
带约束进化算法问题分析Constrained Evolutionary Algorithms
如何在 CGAL 中将三角测量对象(Constrained_Delaunay_triangulation_2)保存到文件(vtk、vtu、msh 等)
[LeetCode in Python] 1425 (H) constrained subsequence sum 带限制的子序列和