数仓架构
Posted guoyu1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数仓架构相关的知识,希望对你有一定的参考价值。
1、什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
2、数据仓库的特点
(1)数据仓库的数据是面向主题的:数据仓库中的数据是面向主题进行组织的,具有更高的数据抽象级别。
(2)数据仓库的数据是集成的:统一了源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致,等等。数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
(3)数据仓库的数据是不可更新的:数据操作主要是数据查询,一般情况下并不进行修改操作。一旦数据仓库存放的数据已经超过数据仓库的数据存储期限,这些数据将从当前的数据仓库中删去。
(4)数据仓库的数据是随时间不断变化的:数据仓库随时间变化不断增加新的数据内容。数据仓库随时间变化不断删去旧的数据内容。数据仓库中包含有大量的综合数据,这些综合数据中很多跟时间有关,如数据经常按照时间段进行综合,或隔一定的时间片进行抽样等等。
3、数据仓库发展历程
- 简单报表阶段:这个阶段,系统的主要目标是解决一些日常的工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据。这个阶段的大部分表现形式为数据库和前端报表工具。
- 数据集市阶段:这个阶段,主要是根据某个业务部门的需要,进行一定的数据的采集,整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供特定的领导决策数据。
- 数据仓库阶段:这个阶段,主要是按照一定的数据模型,对整个企业的数据进行采集,整理,并且能够按照各个业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对对业务具有指导性的数据,同时,为领导决策提供全面的数据支持。
通过数据仓库建设的发展阶段,我们能够看出,数据仓库的建设和数据集市的建设的重要区别就在于数据模型的支持。因此,数据模型的建设,对于我们数据仓库的建设,有着决定性的意义。
4、数据仓库的分层
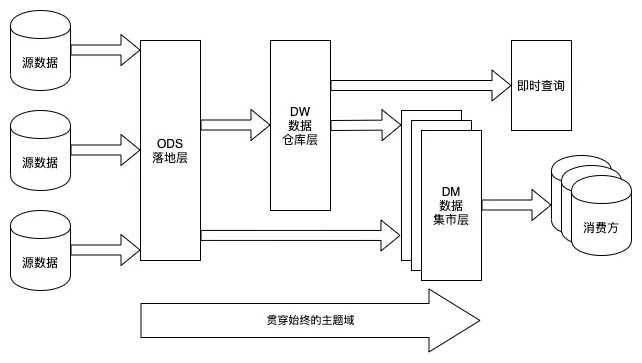
参考:https://mp.weixin.qq.com/s/VaQblRizZTLv-kaKuZuW-Q
(1)ODS 落地层
落地层 (Staging Area) 最初是作为介于业务源数据和数据仓库 ETL 之间的缓冲区而存在的。在 Hive 里它表现为一个独立的库,所有来自业务方的表都会先落到这个库里。
有赞的 ODS 落地层解决了两个问题:1)导表的冲突,2)落后的数据仓库中间层建设和日益增长的业务需求之间的矛盾。
导表的冲突
由于数据源有各种各样的库,源表表名重复是很正常的情况。因此我们需要给每个表加上主题域前缀,从而避免来自不同主题域的同名表之间的冲突。当同一主题域下出现同名表时,我们辅以额外的表后缀来区分。
落地层解决了统一导表的落地问题,也承担着全局 ETL 中的第一轮 Extract。我们的原则是使落地层里的数据和业务数据保持一致,这也是为了方便将来数据问题的排查与核对。
数仓建设和业务需求之间的矛盾
当时我们的人力完全无法满足众多需求方对数据的需求——数据中间层的建设赶不上飞速奔跑的业务需求。于是,一个折中的方法是让业务方直接使用落地层,自行处理一些不跨主题域的需求。
这里有业务方非常熟悉的原始表,他们能非常迅速地获得所需要的数据。这也有利于快速、低成本地进行一些数据方面的探索和尝试。
(2)DW 数仓层
数据仓库层在 Kimball 的数据仓库架构中应该映射的是数据展现层 (Presentation Area),它承载了最复杂的 ETL 逻辑和建模,也是维度建模集中体现的一层。
分层的误区
Kimball 并没有对它做更细的层级划分。我们则依样画葫芦,根据当时业界较为通行的做法将整个数仓层又划分成了 dwd、dwb 和 dws 三层。然而我们却始终说不清楚这三层之间清晰的界限是什么,或者说我们能说清楚它们之间的界限,复杂的业务场景却令我们无法真正落地执行。
由于缺乏维度层,我们的维表显得无处安放;由于缺乏临时层,我们的中间结果和对外发布的表混在了一起。最终,三级分层只完成了我们的数据流向规范——从 dwd 到 dwb 再到 dws,层级之间不可逆向依赖。
宽表的误区
带着大数据环境下维度建模是否依然适用的疑惑,我们和许多人一样,在数仓层开始引入了宽表。所谓宽表,迄今为止并没有一个明确的定义。通常做法是把很多的维度关联到事实表中,形成一张既包含了大量维度又包含了相关事实的表。
宽表的使用,有其一定的便利性。使用方不需要再去考虑跟维度表的关联,也不需要了解维度表和事实表是什么东西。
但是随着业务的增长,我们始终无法预见性地设计和定义宽表究竟该冗余多少维度,也无法清晰地定义出宽表冗余维度的底线在哪里。
一个可能存在的情况是,为了满足使用上的需求,要不断地将维表中已经存在的列增加到宽表中。这直接导致了宽表的表结构频繁发生变动。
(3)DM 数据集市层
数据集市层 (Data Mart) 根据主题域的不同在物理上进行划分——它表现为多个相互独立的库,各个数据集市之间不允许做数据依赖。每个数据集市可以由该主题域的使用方在数据仓库规范下自行开发和建设。
这一层可以根据使用习惯,建立一些宽表。但是如果要配合 Kylin 使用的话,依然建议保持星型模型——它能最大限度的发挥 Kylin 预聚合的优势。
以上是关于数仓架构的主要内容,如果未能解决你的问题,请参考以下文章