实时数仓与离线数仓架构对比Flink消费流程
Posted 养不起心爱的猫该如何是好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时数仓与离线数仓架构对比Flink消费流程相关的知识,希望对你有一定的参考价值。
实时数仓架构图:
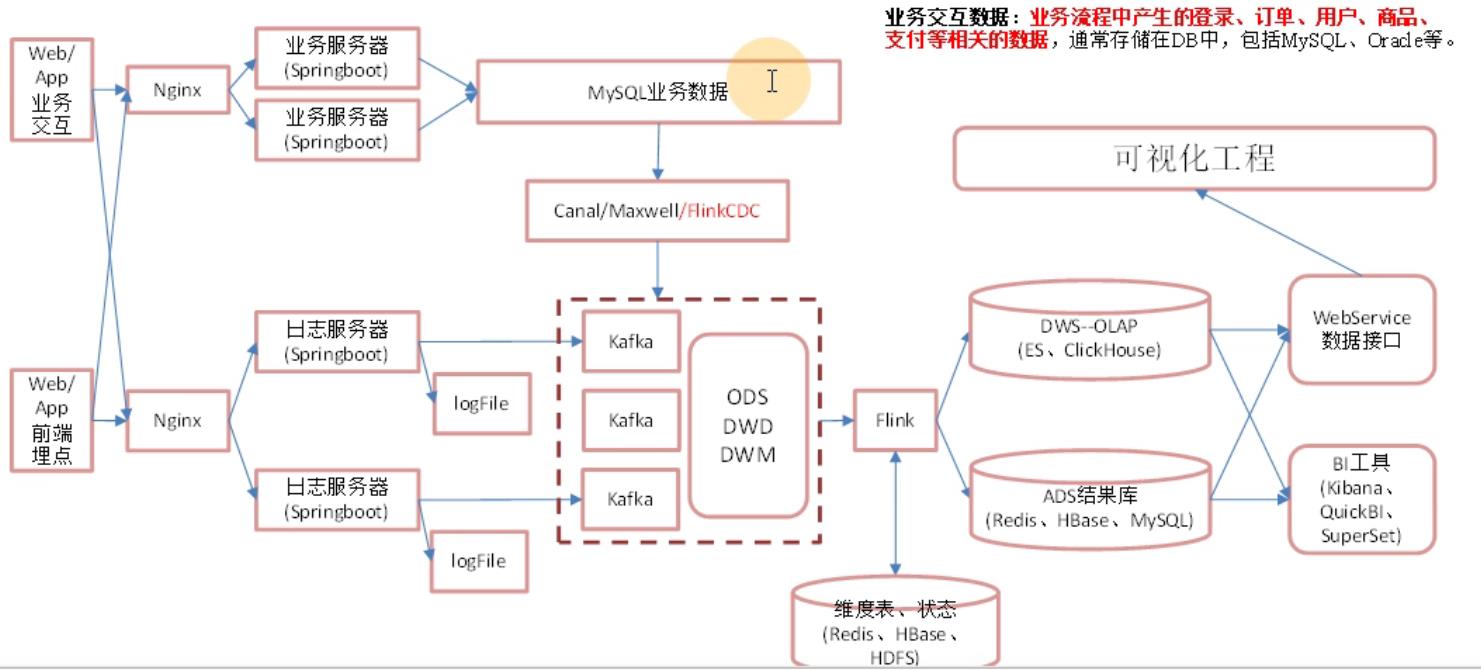
离线数仓:
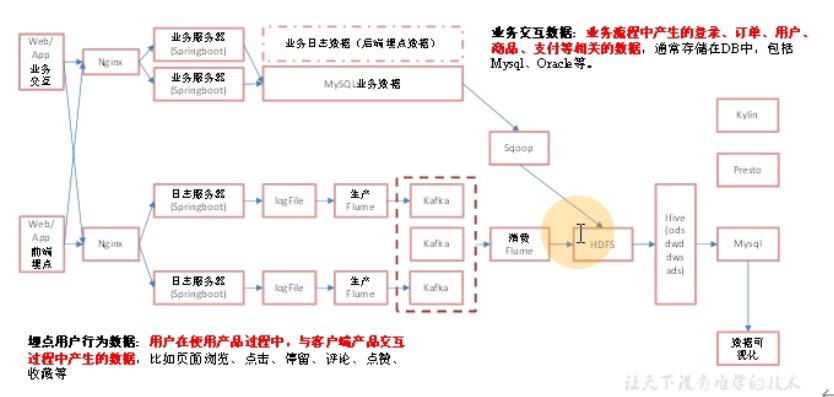
与离线数仓区别:
- mysql业务数据采集改用FlinkCDC;FlinkCDC与Maxwell处理方式和Cannal一样通过监控binlog方式(行级别),而Sqoop是通过MR方式处理数据,这种方式太慢
- 日志数据,离线数仓采用的是Taildir Source监控落盘的多个文件采集数据,并通过Kafka Channel写入Kafka,而实时架构直接将日志数据收集到Kafka,减少了磁盘IO速度也更快了,缺点就是耦合性高,日志服务器和Kafka关联性太大,例如Kafka发生了问题会影响到日志服务器
离线架构
优点:耦合性低,稳定性高
缺点:时效性差一点
说明:
1.更追求系统的稳定性
2.耦合性低,稳定性高
3.公司未来的发展,数据量会变得很大
实时架构
优点:时效性好
缺点:耦合性高,稳定性低
实时架构
优点:时效性好
缺点:耦合性高,稳定性低
说明:
1.时效性好,使用的是Flink
2.Kafka集群高可用,挂一台两台是没有问题
3.数据量小,所有机器存在于同一个机房,传输没有问题
PS:没有最好的架构,只有合适的架构
Flink消费流程
从FlinkCDC和Kafka来的数据放入ODS,接下来需要把它们拆成明细放入DWD,像行为数据中的日志有:启动日志、动作日志、曝光日志、错误日志、页面日志和离线数仓一样,把一张表的数据拆成五张表;从FinkCDC中来的数据也是一张表,所以ODS层只有两个主题:行为数据一个主题,业务数据一个主题;
使用Flink将Kafka中ODS层数据进行消费,通过侧输出流进行分流,分到DWD层不同的主题里面,同时业务数据一部分需要放入Kafka中DWD层事实表里面,一部分需要放入HBase中的DIM层维度表
Flink消费DWD层数据关联维表形成DWM层
Flink消费DWM层数据写入ClickHouse(为什么使用ClickHouse后续会讲)
以上是关于实时数仓与离线数仓架构对比Flink消费流程的主要内容,如果未能解决你的问题,请参考以下文章