几种实时数仓架构设计思路
Posted 肉眼品世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了几种实时数仓架构设计思路相关的知识,希望对你有一定的参考价值。
01 什么是实时数仓
首先需要明确什么是实时数仓,百度百科与维基百科都没有给出具体说明,哪究竟什么才是实时数仓呢?是不是可以通过实时流实时获取数据就是实时数仓?或者说流批一体就是实时数仓?在或者全面采用实时方式,采集和实时计算才是实时数仓?
这个问题在不同企业可能会有不同答案,有些会认为提供实时看板或实时报表就算是实时数仓;另外一些可能觉得数仓提供出去数据必须都是实时才算实时数仓。其实这个问题没有一个标准答案,不同人、场景、企业对它理解是不一样的。记得之前有位上司讲管理岗与技术岗区别,其中一点是:
对待一件事情或需求,T 岗答案都是明确:要么可以做,要么不可以做;M 岗的回答看似明确,其实会有多种解读角度。【这不就是老油条么,哈哈】
所以从不同角度去解读实时数仓,对什么是实时数仓定义是不一样;一般会有一些几种定义:
具备实时数据处理能力,并能够根据业务需求提供实时数据的数仓能力,如可以为运营侧提供实时业务变化、实时营销效果数据。
数仓中所有数据,从数据采集、加工处理、数据分发都采用实时方式。
从数据建设、数据质量、数据血缘、数据治理等都是采用实时方式。
从中可以看出不同理解,建设实时数仓复杂程度是不一样。但最终建设一套什么样实时数仓还是由业务驱动,需要综合考虑投入产出。
02 实时数仓架构设计思路
是否数据集成流批一体:离线与实时是否使用统一数据采集方式;如统一通过 CDC 或者 OGG 将数据实时捕获推送到 kafka,批与流在从 kafka 中消费数据,载入明细层。
是否存储层流批一体:离线与实时数据是否统一分层、统一存储;如离线与实时数据经过 ETL 处理之后根据统一分层(ODS、DMD、DMS)持久化到同一个数据存储中。
是否 ETL 逻辑流批一体:流与批处理是否使用统一 SQL 语法或者 ETL 组件,再通过底层分别适配流与批计算引擎。
是否 ETL 计算引擎流批一体:流与批使用同一套计算引擎,从根本上避免同一个处理逻辑流批两套代码问题。
数据集成与存储层流批一体主要产生以下问题:
流处理更容易出现数据丢失,丢失的查询操作。
一般使用消息中间件对流数据进行存储,消息中间件的存储特点也决定了,丢失的查询操作,非常苦难,难以对数。
Schema 的同步与转换问题,基于流处理来确保 Schema 保持一致,并且数据不受影响其实并不容易。面对频繁变动的业务系统,往往维护量会变高。
03 几种实时数仓架构分析
Lambda 数仓架构
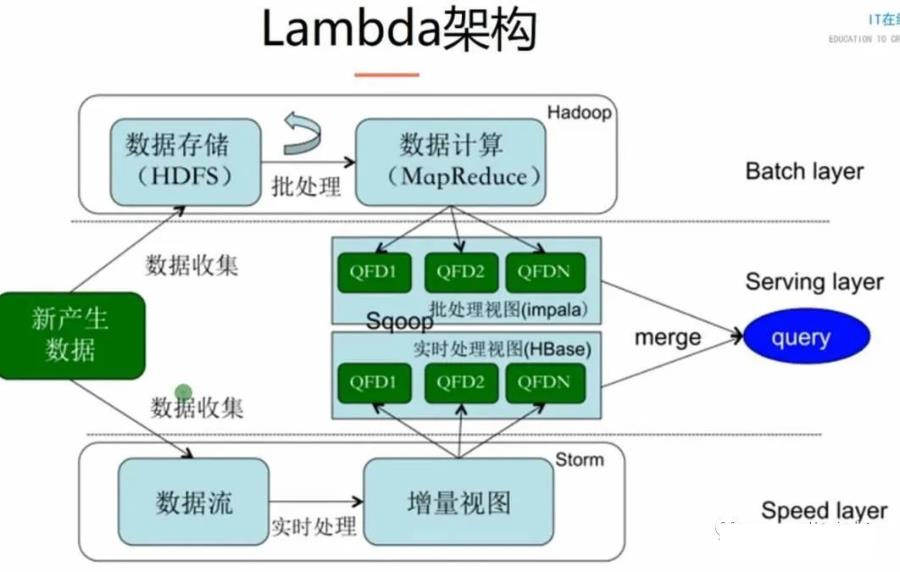
Lambda 有 Batch Layer(批处理)和 Speed Layer(流式处理)。然后通过将批、和流的结果拼接在一起。Lambda 架构具备有数据不可变性质避免人为引入错误问题、支持数据重跑、将复杂的流处理分离出来。而 Batch Layer 和 Speed Layer 由于需要满足不同的场景,往往会选择不同的组件。
而且,大家写过 Storm 就会知道,Storm 的代码写起来的是挺痛苦的(Trident 会有所改善)。所以,我们需要准备两套代码。同样的逻辑,针对批处理、和流处理要实现两次。
Lambda 架构问题:
两套架构、各自独立
一种逻辑两套代码
组件太多
数据散布在多个系统中,互相访问困难
Kappa 架构
Kreps 提出了另一个维度的思考,我们是否能够改进,采用流处理系统来建设大数据系统呢?提出完全可以通过建设以流为核心来建设数据系统。并且,通过重放历史数据来实现数据重跑。
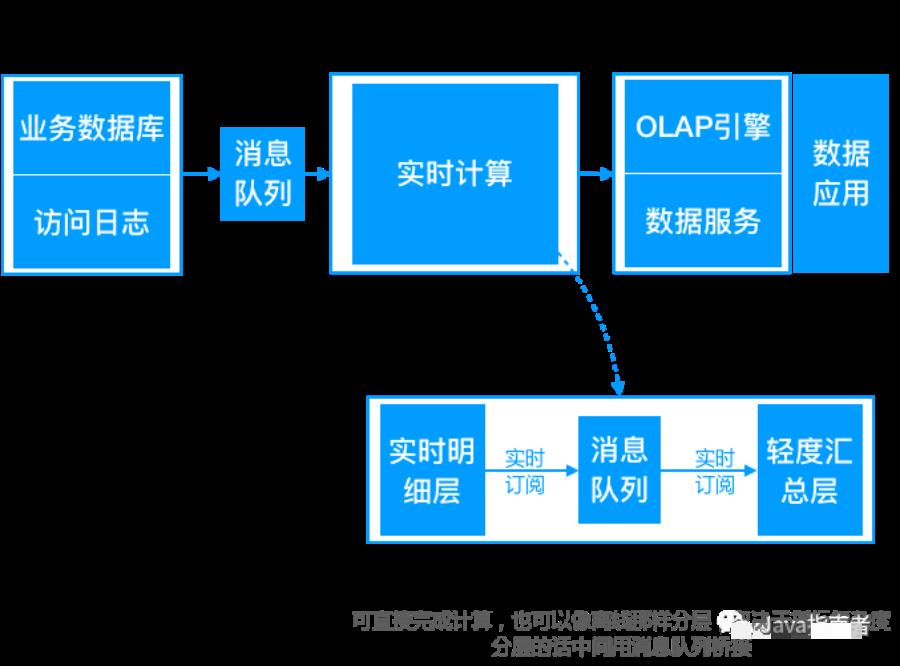
Lambda 架构问题:
大数据量回溯成本高,生产压力大
遗留离线数据数仓的迁移问题,要将成千上万的 ETL 作业迁往流处理系统,其工作量之大、成本之大、风险之大
数据丢失的问题,流处理平台,数据丢失问题相对于批处理,更容易出现。而且,要进行对数非常困难
实时数据生产 + 实时分析引擎
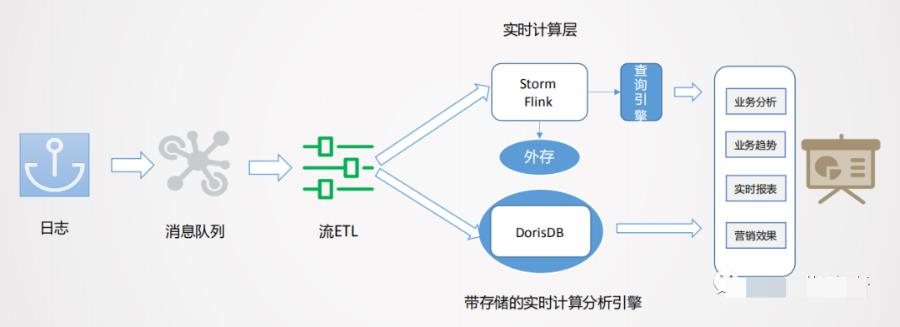
上图是美团实时数仓架构设计,数据从日志统一采集到消息队列,再到数据流的 ETL 过程,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。
对于 Binlog 类业务分析走实时 OLAP 批处理。美团实时数仓架构主要是将一些在实时处理面临的难点,由实时 OLAP 处理。
实时处理面临的几个难点:
业务的多状态性:业务过程从开始到结束是不断变化的,比如从下单->支付->配送,业务库是在原始基础上进行变更的,Binlog 会产生很多变化的日志。而业务分析更加关注最终状态,由此产生数据回撤计算的问题,例如 10 点下单,13 点取消,但希望在 10 点减掉取消单。
业务集成:业务分析数据一般无法通过单一主体表达,往往是很多表进行关联,才能得到想要的信息,在实时流中进行数据的合流对齐,往往需要较大的缓存处理且复杂。
分析是批量的,处理过程是流式的:对单一数据,无法形成分析,因此分析对象一定是批量的,而数据加工是逐条的。
Lambda+Kappa
从上图可以看出,阿里的实时数仓架构是同时 Lambda 与 Kappa 结合;数据集成没有使用流批一体,分别通过实时采集、数据同步方式实现流与批数据采集。ETL 逻辑流批一体,实现用户只写一套代码,平台自动翻译成 Flink Batch 任务和 Flink Stream 任务,同时写到一张 Holo 表,完成计算层表达的统一。存储层流与批是分开存储,但可以实现流批存储透明化,查询逻辑完全一致。
04 总结
推荐阅读:
以上是关于几种实时数仓架构设计思路的主要内容,如果未能解决你的问题,请参考以下文章