PySpark之RDD操作
Posted shenjianping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PySpark之RDD操作相关的知识,希望对你有一定的参考价值。
一、什么是RDD
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
弹性分布式数据集(RDD),Spark中的基本抽象。表示可以并行操作的元素的不变分区集合。
- 弹性:可以存储在磁盘或内存中(多种存储级别)
- 分布:分布在集群中的只读对象集合(由多个Partition构成)
(一)特性
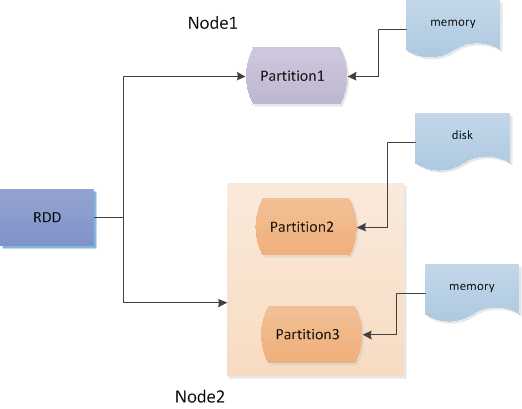
1、分区
上述定义中也说了RDD是一个抽象的概念,数据是存储在RDD下的Partition分区,这些分区可以分布在一个节点上,也可以分布在不同的节点上。
2、依赖
上述定义中RDD是只读和不可变的,那么如果想要改变其中的值,通过不断创建变量这种方式来实现。比如:
#定义一个变量 x = 2 #改变这个值,此时有多了一个变量y,同时有聊新的值 y = 2x + 1
这样,可以不断创建新的变量,形成血缘依赖关系。
3、缓存
默认是缓存到内存的,但是支持多种缓存策略,可以灵活的进行变更。
(二)核心属性
调度和计算都依赖于这五个属性:
- 分区列表
RDD是一个抽象的概念,它对应多个Partition,所以有一个分区列表的属性
- 依赖列表
RDD中的变量是不可变的,它是有一个依赖关系,这与上面的依赖特性进行对应。
- Compute函数,用于计算RDD各分区的值
- 分区策略(可选)
数据是如何对应一个RDD中的多个Partition。
- 优先位置列表(可选,HDFS实现数据本地化,避免数据移动)
二、RDD的生成
RDD的生成有三种方式,分别是:
- 从外部文件创建
- 集合并行化
- 从父RDD生成子RDD
(一)从外部文件创建
- 支持本地磁盘文件
- 支持整个目录、多文件、通配符
- 支持压缩文件
- 支持HDFS
读取文件使用的方法是textFile:
textFile(name, minPartitions=None, use_unicode=True) Read a text file from HDFS, a local file system (available on all nodes), or any Hadoop-supported file system URI, and return it as an RDD of
Strings.
读取各种本地文件、目录、HDFS的形式:


SC.textFi le(“/1.tXt, /02.tXt“) #支持多文件,中间以逗号分隔 SC.textFi le(”/*.txt“) #支持通配符
实例:
(二)集合并行化
集合并行化就是对一些数据结构,比如列表等生成RDD。
>>> sc = spark.sparkContext >>> sc <pyspark.context.SparkContext object at 0x0000000000ADB7B8> >>> x = [1,2,3] >>> rdd = sc.parallelize(x) >>> rdd.collect() [Stage 0:> (0 + 0) / 4] [1, 2, 3] >>>
对于parallelize方法:
parallelize(c, numSlices=None) Distribute a local Python collection to form an RDD. Using xrange is recommended if the input represents a range for performance.
其中c是传入的data,比如list类型数据,numSlices是切片的数量,每一个切片可以启动一个task任务。
(三)从父RDD生成子RDD
1、Transformation
|
Transformation |
Meaning |
|
map(func) |
Return a new distributed dataset formed by passing each element of the source through a function func. |
|
filter(func) |
Return a new dataset formed by selecting those elements of the source on which funcreturns true. |
|
flatMap(func) |
Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
|
mapPartitions(func) |
Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T |
|
intersection(otherDataset) |
Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
|
distinct([numTasks])) |
Return a new dataset that contains the distinct elements of the source dataset. |
|
union(otherDataset) |
Return a new dataset that contains the union of the elements in the source dataset and the argument. |
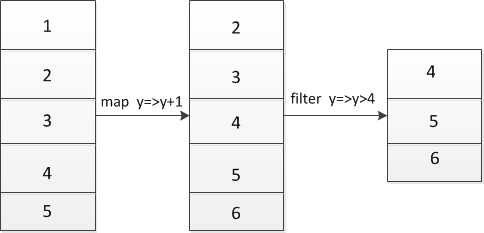
使用Transformation中的函数可以对数据进行处理:
2、Action
|
Action |
Meaning |
|
reduce(func) |
Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
|
collect() |
Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
|
count() |
Return the number of elements in the dataset. |
|
first() |
Return the first element of the dataset (similar to take(1)). |
|
take(n) |
Return an array with the first n elements of the dataset. |
|
takeSample(withReplacement, num, [seed]) |
Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
|
takeOrdered(n, [ordering]) |
Return the first n elements of the RDD using either their natural order or a custom comparator. |
3、Transformation和Action的区别
- Tranformation的输入输出都是RDD;Action的输入是RDD,输出是值
-
Transformation是Lazy计算,Tra nsformation只会记录RDD转化关系
并不会触发计算;Action是立即执行的
所以代码中尽管有Transformation,但是不会立即执行,只会在Action时触发Transformation的代码。执行流程:
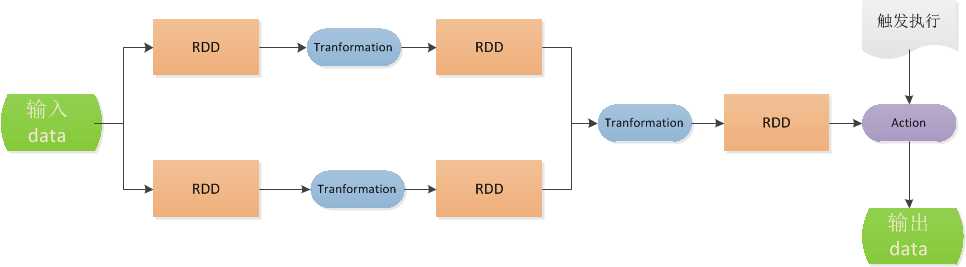
详情查看:http://spark.apache.org/docs/2.0.2/programming-guide.html#transformations
4、Persistence
主要就是进行数据持久化,它与Transformation一样不会立即执行:
- cache方法是缓存到内存中
cache()方法调用的也是persist方法,缓存策略均为MEMORY_ONLY。
- persist方法支持更灵活的缓存策略
persist方法手工设定StorageLevel来满足工程需要的存储级别
下面列出的是存储级别:
|
Storage Level |
Meaning |
|
MEMORY_ONLY |
Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they‘re needed. This is the default level.. |
|
MEMORY_AND_DISK |
Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don‘t fit on disk, and read them from there when they‘re needed. |
|
MEMORY_ONLY_SER |
Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
|
MEMORY_AND_DISK_SER |
Similar to MEMORY_ONLY_SER, but spill partitions that don‘t fit in memory to disk instead of recomputing them on the fly each time they‘re needed. |
|
DISK_ONLY |
Store the RDD partitions only on disk. |
|
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. |
Same as the levels above, but replicate each partition on two cluster nodes. |
|
OFF_HEAP (experimental) |
Similar to MEMORY_ONLY_SER, but store the data in off-heap memory. This requires off-heap memory to be enabled. |
5、实例
我们可以通过wordcount来体会以下具体怎么来使用这种方式:
(1)准备测试文件
Preface “The Forsyte Saga” was the title originally destined for that part of it which is called “The Man of Property”; and to adopt it for the collected chronicles of the Forsyte family has indulged the Forsytean tenacity that is in all of us. The word Saga might be objected to on the ground that it connotes the heroic and that there is little heroism in these pages. But it is used with a suitable irony; and, after all, this long tale, though it may deal with folk in frock coats, furbelows, and a gilt-edged period, is not devoid of the essential heat of conflict. Discounting for the gigantic stature and blood-thirstiness of old days, as they have come down to us in fairy-tale and legend, the folk of the old Sagas were Forsytes, assuredly, in their possessive instincts, and as little proof against the inroads of beauty and passion as Swithin, Soames, or even Young Jolyon. And if heroic figures, in days that never were, seem to startle out from their surroundings in fashion unbecoming to a Forsyte of the Victorian era, we may be sure that tribal instinct was even then the prime force, and that “family” and the sense of home and property counted as they do to this day, for all the recent efforts to “talk them out.” So many people have written and claimed that their families were the originals of the Forsytes that one has been almost encouraged to believe in the typicality of an imagined species. Manners change and modes evolve, and “Timothy’s on the Bayswater Road” becomes a nest of the unbelievable in all except essentials; we shall not look upon its like again, nor perhaps on such a one as James or Old Jolyon. And yet the figures of Insurance Societies and the utterances of Judges reassure us daily that our earthly paradise is still a rich preserve, where the wild raiders, Beauty and Passion, come stealing in, filching security from beneath our noses. As surely as a dog will bark at a brass band, so will the essential Soames in human nature ever rise up uneasily against the dissolution which hovers round the folds of ownership. “Let the dead Past bury its dead” would be a better saying if the Past ever died. The persistence of the Past is one of those tragi-comic blessings which each new age denies, coming cocksure on to the stage to mouth its claim to a perfect novelty. But no Age is so new as that! Human Nature, under its changing pretensions and clothes, is and ever will be very much of a Forsyte, and might, after all, be a much worse animal. Looking back on the Victorian era, whose ripeness, decline, and ‘fall-of’ is in some sort pictured in “The Forsyte Saga,” we see now that we have but jumped out of a frying-pan into a fire. It would be difficult to substantiate a claim that the case of England was better in 1913 than it was in 1886, when the Forsytes assembled at Old Jolyon’s to celebrate the engagement of June to Philip Bosinney. And in 1920, when again the clan gathered to bless the marriage of Fleur with Michael Mont, the state of England is as surely too molten and bankrupt as in the eighties it was too congealed and low-percented. If these chronicles had been a really scientific study of transition one would have dwelt probably on such factors as the invention of bicycle, motor-car, and flying-machine; the arrival of a cheap Press; the decline of country life and increase of the towns; the birth of the Cinema. Men are, in fact, quite unable to control their own inventions; they at best develop adaptability to the new conditions those inventions create.
(2)编写代码
>>> sc = spark.sparkContext >>> rdd1 = sc.textFile(‘I:spark_file est.txt‘) #Transformation操作,只是记录了动作,并没有执行 >>> wordsRDD = rdd1.flatMap(lambda x:x.split(‘ ‘)).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y) #Action操作,触发了Transformation操作 >>> wordsRDD.collect()
最后执行的结果:
(‘fenced‘, 1), (‘sharp‘, 7), (‘costs.‘, 1), (‘state;‘, 1), (‘Taking‘, ), (‘staring,‘, 1), (‘doctors‘, 1), (‘employment‘, 3), (‘white-bearded‘, 1), (enniless‘, 1), (‘Forsyteism.‘, 1), (‘random‘, 1), (‘singers!‘, 1), (‘tastes.‘,), (‘good!’‘, 1), (‘egg‘, 1), (‘Bentham,‘, 3), (‘naturally‘, 6), (‘stream!‘, 1), (‘horrid!”‘, 1), (‘other.‘, 11), (‘nightshirt,‘, 1), (‘judgment‘, 11), (‘slihtest‘, 2), (‘chapel,‘, 1), (‘cages!‘, 1), (‘nineteen‘, 1), (‘grass-plot,‘, 1),(‘Testament‘, 1), (‘betrayal‘, 1), (‘nerve,‘, 1), (‘together;‘, 4), (‘scene!‘,), (‘exceedingly‘, 1), (‘compunctious.‘, 1), (‘Haven’t‘, 2), (‘”‘, 34), (‘poery;‘, 1), (‘thinkable.‘, 1), (‘Phil’s‘, 1), (‘floors‘, 1), (‘kinds‘, 1), (‘arrsted‘, 1), (‘Fresh‘, 1), (‘lump‘, 1), (‘purse,‘, 2), (‘inarticulate‘, 1), (‘witstand;‘, 1),...
另外可以通过SaveAsTextFile将其存储在本地文件中。
以上是关于PySpark之RDD操作的主要内容,如果未能解决你的问题,请参考以下文章