PySpark|RDD编程基础
Posted 数据山谷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PySpark|RDD编程基础相关的知识,希望对你有一定的参考价值。
RDD编程

引
言
PySpark操作教程连载(二)
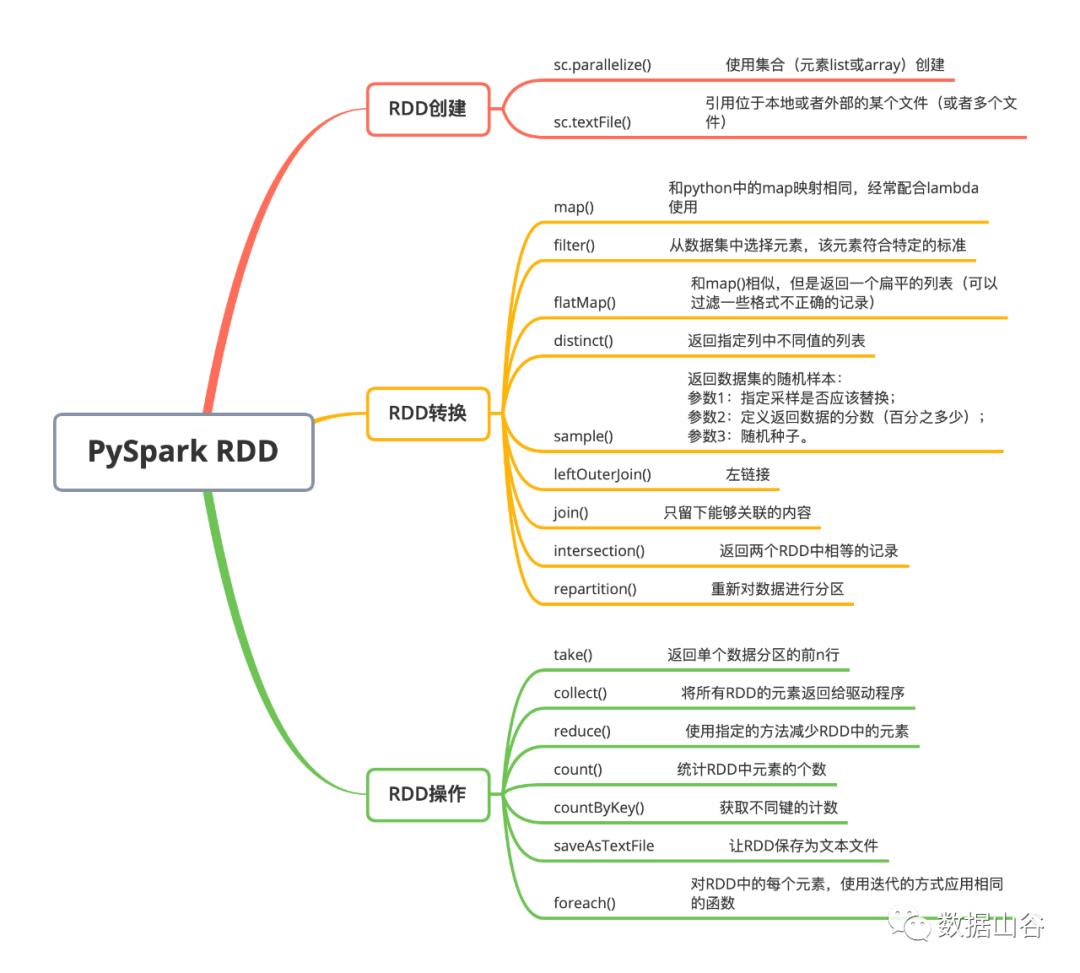
文末附上PysparkRDD操作思维导图
01
RDD(弹性分布式数据集)
RDD是Spark中最基本的数据抽象,其实就是分布式的元素集合。RDD有三个基本的特性:分区、不可变、并行操作。
分区:每一个 RDD 包含的数据被存储在系统的不同节点上。逻辑上我们可以将 RDD 理解成一个大的数组,数组中的每个元素就代表一个分区 (Partition) 。
不可变:不可变性是指每个 RDD 都是只读的,它所包含的分区信息是不可变的。由于已有的 RDD 是不可变的,所以我们只有对现有的 RDD 进行转化 (Transformation) 操作,才能得到新的 RDD ,一步一步的计算出我们想要的结果。
并行操作:因为 RDD 的分区特性,所以其天然支持并行处理的特性。即不同节点上的数据可以分别被处理,然后生成一个新的 RDD。

02
RDD创建
在Pyspark中我们可以通过两种方式来进行RDD的创建,RDD是一种无schema的数据结构,所以我们几乎可以混合使用任何类型的数据结构:tuple、dict、list都可以使用。
parallelize()
直接使用数据容器创建RDD。
data = sc.parallelize([('Amber', 22), ('Alfred', 23), ('Skye', 4),('Albert', 12), ('Amber', 9)])
textFile()
引用位于本地或者外部的某个文件(或者多个文件)。
data_from_file = sc.\textFile('xxxxx',4)
03
RDD转换
我们可以通过转换操作来进行数据集的调整,包括映射、筛选、连接、转换数据集中的值等操作。
map()
和python中的map映射相同,经常配合lambda使用。
data_2020 = data_from_file_conv.map(lambda row: int(row[16]))filter()
从数据集中选择元素,该元素符合特定的标准。
data_filtered = data_from_file_conv.filter(lambda row: row[5] == 'F' and row[21] == '0')flatMap()
和map()相似,但是返回一个扁平的列表(可以过滤一些格式不正确的记录)。
data_2014_flat = data_from_file_conv.flatMap(lambda row: (row[16], int(row[16]) + 1))distinct()
返回指定列中不同值的列表。
distinct_gender = data_from_file_conv.map(lambda row: row[5]).distinct().collect()sample()
返回数据集的随机样本:
参数1:指定采样是否应该替换;
参数2:定义返回数据的分数(百分之多少);
参数3:随机种子。
fraction = 0.1data_sample = data_from_file_conv.sample(False, fraction, 666)
leftOuterJoin()
左链接。
rdd1 = sc.parallelize([('a', 1), ('b', 4), ('c',10)])rdd2 = sc.parallelize([('a', 4), ('a', 1), ('b', '6'), ('d', 15)])rdd3 = rdd1.leftOuterJoin(rdd2)
join()
只留下能够关联的内容。
rdd4 = rdd1.join(rdd2)intersection()
返回两个RDD中相等的记录
rdd5 = rdd1.intersection(rdd2)repartition()
重新对数据进行分区。
rdd1 = rdd1.repartition(4)
04
RDD操作
和上面的转换不同,操作执行数据集上的计划任务。
take()
返回单个数据分区的前n行。
data_first = data_from_file_conv.take(1)data_first
collect()
将所有RDD的元素返回给驱动程序。
rdd5.collect()reduce()
使用指定的方法减少RDD中的元素。
rdd1.map(lambda row: row[1]).reduce(lambda x, y: x + y)count()
统计RDD中元素的个数。
data_reduce.count()countByKey()
获取不同键的计数。
data_key.countByKey().items()saveAsTextFile
让RDD保存为文本文件。
data_key.saveAsTextFile('xxx')foreach()
对RDD中的每个元素,使用迭代的方式应用相同的函数。
def f(x):print(x)data_key.foreach(f)
05
总结
后台回复RDD获取高清大图
整理不易,拉到底动动小手挨个点一下吧

老铁们,长按二维码上车吧!
以上是关于PySpark|RDD编程基础的主要内容,如果未能解决你的问题,请参考以下文章