Spark之RDD的使用(pyspark版)
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark之RDD的使用(pyspark版)相关的知识,希望对你有一定的参考价值。
💫上次写完rdd的介绍,有同学强烈介意用一些代码来展示一下rdd,好今天我们就如你所愿,我们今天就来以代码的方式给大家讲解一下rdd吧,对以往内容感兴趣的同学可以查看下面👇:
- 链接: Spark之处理布尔、数值和字符串类型的数据.
- 链接: Spark之Dataframe基本操作.
- 链接: Spark之处理布尔、数值和字符串类型的数据.
- 链接: Spark之核心架构.
- 链接: Spark之RDD算子.
💐今天主要讲解一下rdd的大致情况,以及目前的使用场景,然后就是掩饰怎么使用python操作rdd的几种方式。
目录
1. 低级API——RDD
其实对于初学者,我不会很建议你从这部分开始,因为这部分理解起来很困难,还不如从高级的api开始学,之所以说rdd低级,是因为我们在几乎所有的场景都能应该使用结构化的api,只有当我们遇到一些很不常见的功能你才会使用rdd(当然还有其他的场景),低级的api有两种:
- rdd 弹性分布式数据集
- 广播变量和累加器 分发和处理分布式的共享变量。
rdd在spark的1.X版本是主要的api,在2.X版本仍然可以使用,但不常用,我们目前使用的是3.X版本,几乎不用原始的rdd了。但rdd的概念是一直存在的,无论是我们的dataframe和dataset(scala),运行所有的spark代码都将编译成rdd。
rdd虽然有很强大的可塑性,可是在完成一些操作时的优化远远没有结构化的api好,所以说结构化的api更高效。
2. 创建RDD
低级api使用spark.sparkContext来调用即可。但我们这里讲解几种创建方式。
2.1 使用高级api转换
这里的高级api主要是指利用DataFrame和Dataset来创建rdd。
- 使用dataframe创建rdd
#使用dataframe创建rdd
a=spark.range(10).rdd
a.collect()
结果如下:

- 使用rdd创建dataframe
#使用rdd创建dataframe
b=spark.range(10).rdd.toDF()
b.show()
结果如下:

2.2 从本地创建rdd
从集合中创建rdd需要使用sparkContext中的parallelize方法,该方法会将位于单个节点的数据集合转换成一个并行集合。在创建该并行集合时,还可以显示指定并行集合的分片集合。下面我以2个分片作为例子:
#创建单词rdd
c='hello spark , hello hadoop'.split(" ")
words=spark.sparkContext.parallelize(c,2)
words.collect()
结果如下:

2.3 从数据源创建
从数据源或者文本文件中都能创建rdd,但最好还是采用结构化的方式来读取数据。
#从文本中读取数据
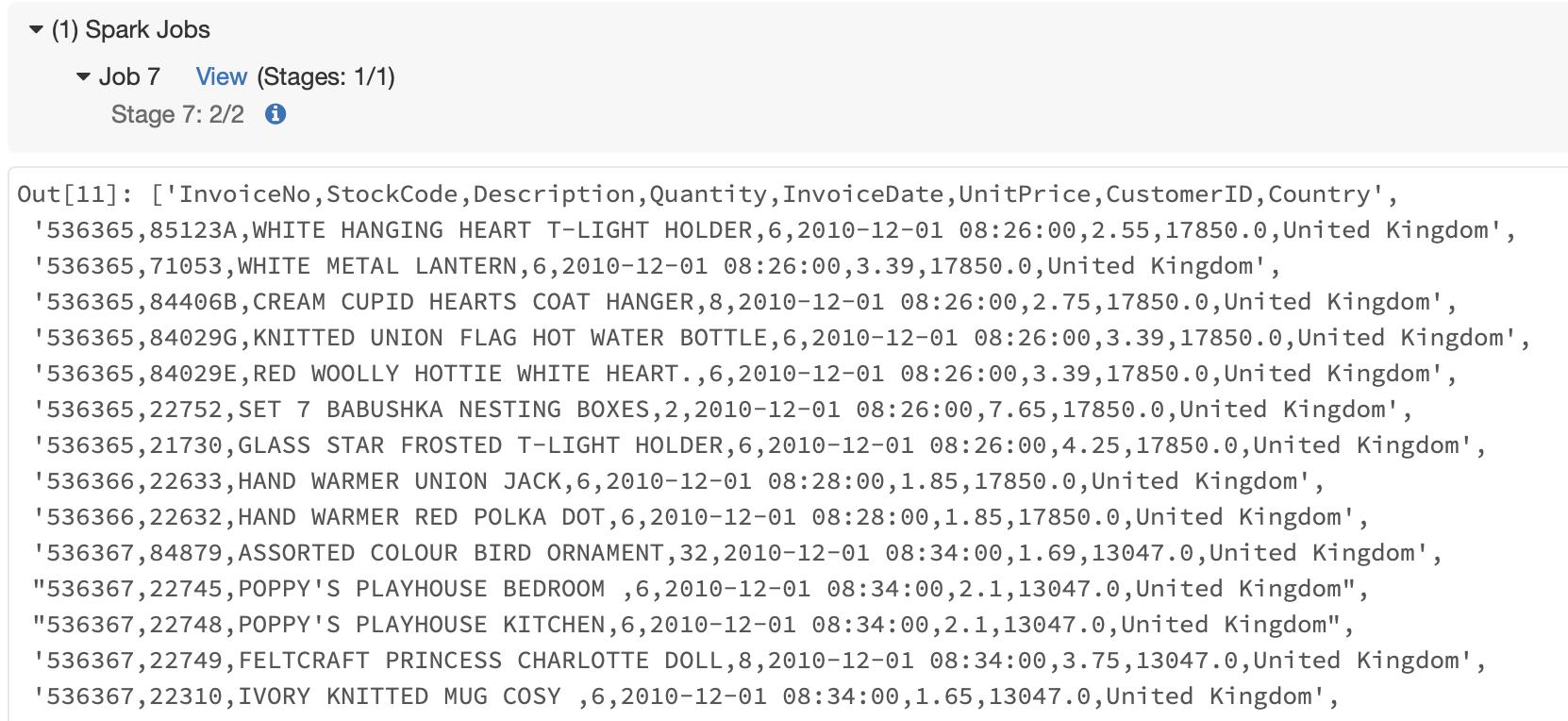
d=spark.sparkContext.textFile("/FileStore/tables/2010_12_01.csv")
d.collect()
结果如下:
3. 操作RDD
转换操作
3.01 dinstinct
在rdd上调用distinct方法用于删除rdd中的重复项
c='hello spark , hello hadoop'.split(" ")
words=spark.sparkContext.parallelize(c,2)
words.distinct().count()
结果如下:

3.02 filter
过滤器filter类似于sql中的where子句。
#构建一个过滤条件h开头
def startwith(ones):
return ones.startswith("h")
#filter过滤
words.filter(lambda x:startwith(x)).collect()
结果如下:

3.03 map
map操作,指定一个函数,将给定的数据一条一条地输入该函数处理以得到你期望的结果,一对一是map最大的特点。
#将单个字符变成一个三元组
words.map(lambda word : (word,word[0],word.startswith('h'))).collect()
结果如下:

3.04 flatmap
flatmap函数是对map函数的拓展,当前行会映射为多行。该函数最大的特点就是一行映射多行。
#将一个一单词拆成一个个字符
words.flatMap(lambda a:list(a)).take(10)
结果如下:

3.05 sortBy
排序操作
#将单词按照字符长度从短到长排列
words.sortBy(lambda a:len(a)).take(4)
结果如下:

动作操作
3.06 reduce
该函数指定一个函数将rdd中的任何类型的值“规约”成一个值
#求1-20数字之和(这里实现的方式,是通过22相加最后求的总和)
spark.sparkContext.parallelize(range(1,21)).reduce(lambda x,y:x+y)
结果如下:

3.07 count
用与统计元素个数
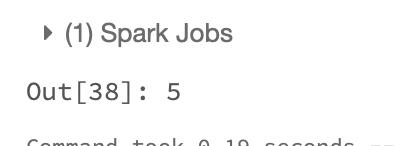
#统计单词个数
words.count()
结果如下:
3.08 countByValue
根据value值进行计数
words.countByValue()
结果如下:

3.09 first
返回数据集中第一个值
#返回数据集中第一个值
words.first()
结果如下:

3.10 max 和 mix
max和min方法分别返回最大值和最小值
#最大值
spark.sparkContext.parallelize(range(1,11)).max()
结果如下:

#最小值
spark.sparkContext.parallelize(range(1,11)).min()
结果如下:

3.11 take
take 和它的派生方法是从rdd中获取一定数据的值
words.take(3)

4.参考文献
《spark权威指南》
《pysaprk教程》
《pyspark实战》
以上是关于Spark之RDD的使用(pyspark版)的主要内容,如果未能解决你的问题,请参考以下文章
如何通过 pyspark 以 gzip 格式保存 spark RDD
使 Spark 结构化流中的 JSON 可以在 python (pyspark) 中作为没有 RDD 的数据帧访问
Spark 定制版:008~Spark Streaming源码解读之RDD生成全生命周期彻底研究和思考