数据库--关系数据理论
Posted hoo334
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库--关系数据理论相关的知识,希望对你有一定的参考价值。
关系数据理论
本文为复习数据库整理的资料。
参考:
https://blog.csdn.net/prdslf001001/article/details/80336835
https://www.bilibili.com/video/av73467859/
https://www.bilibili.com/video/BV1eE411a79r/
一、数据冗余导致的问题
1)冗余存储:信息被重复存储,导致浪费大量存储空间。
2)更新异常:当重复的信息的一个副本被修改,所有副本都必须进行同样的修改。因此当更新数据时,系统要付出很大的代价来维护数据库的完整性,否则会面临数据不一致的风险。
3)插入异常:只有当一些信息事先已经存放在数据库中时,另外一些信息才能存入数据库中。
4)删除异常:删除某些信息时可能丢失其他信息。
二、函数依赖定义
1、函数依赖
在关系R中,若属性或者属性集 A 中 两个元组的值相等,如果这两个元祖中对应的属性或者属性集B中的值也相同,则记作A—>B。 A函数决定B; 或者 B函数依赖于A。
2、平凡与非平凡函数依赖
对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新的语义。若不特别声明,总是讨论非平凡函数依赖。
3、完全函数依赖和部分函数依赖
完全函数依赖:(学号,课号)——>成绩; 单独一个学号,不能决定成绩,单独一个课程,也不能决定成绩;只有二者同时,才能决定;
部分函数依赖:(学号,课号)——>姓名;学号和课号能决定姓名, 单独一个 学号 也能决定 姓名;
4、传递函数依赖
学号—>系号,系号—>系主任; 系主任 传递依赖于 学号
三、函数依赖理论
1、码、超码、候选码和主码
码是一个或多个属性的集合。
超码是一个或多个属性的集合,超码中的这些属性可以让我们在一个实体集中唯一地标识一个实体。
候选码是极小的超码集,也就是它的任意真子集都不是超码,而他本身是超码。
主码是被选中用来在一个关系中区分不同元组的候选码。
候选码的确定:
设关系模式R中U=ABC.......等N个属性,U中的属性在FD中有四种范围:
(1)左右出现;
(2)只在左部出现;
(3)只在右部出现;
(4)不在左右出现;
算法:按以下步骤求候选键:
1.只在FD右部出现的属性,不属于候选码;
2.只在FD左部出现的属性,一定存在于某候选码当中;
3.外部属性一定存在于任何候选码当中; (左右都不出现)
4.其他属性逐个与2,3的属性组合,求属性闭包,直至X的闭包等于U,若等于U,则X为候选码。
例1:R<U,F>,U=(A,B,C,D,E,G),F={AB-->C,CD-->E,E-->A.A-->G},求候选码以及主属性。
因为:G只在右边出现,所以候选码肯定不包含G,BD只出现在左边,所以,候选码中肯定有BD,而BD的闭包还是BD,则对BD进行组合,除了G以外,BD可以跟A,C,E进行组合。
先看ABD
ABD本身自包ABD,而AB-->C,CD-->E,A-->G,所以ABD的闭包为ABDCEG=U
再看BDC
CD-->E,E-->A,A-->G,BDC本身自包,所以BDC的闭包为BDCEAG=U
最后看BDE
E-->A,A-->G,AB-->C,BDE本身自包,所以BDE的闭包为BDEAGC=U
因为(ABD)、(BCD)、(BDE)的闭包都是ABCDEG所以本问题的候选码有3个分别是ABC、BCD和BDE
候选码:ABC,BCD,BDE;
主属性(主要的属性,能决定其他属性的):ABCDE;
非主属性:G;
2、Armstrong 公理系统
设关系模式R<U,F>,其中U为属性集,F是U上的一组函数依赖,那么有如下推理规则
① A1自反律:若Y⊆X⊆U,则X→Y为F所蕴含; 即:ABC→AB; AB——>A (平凡依赖函数);
② A2增广律:若X→Y为F所蕴含,且Z⊆U,则XZ→YZ为F所蕴含;
③ A3传递律:若X→Y,Y→Z为F所蕴含,则X→Z为F所蕴含。
根据上面三条推理规则,又可推出下面三条推理规则:
④ 合并规则:若X→Y,X→Z,则X→YZ为F所蕴含;
⑤ 伪传递规则:若X→Y,WY→Z,则XW→Z为F所蕴含; 即:A→B,AC→BC;BC→D ;得出AC→D;
⑥ 分解规则:若X→Y,Z⊆Y,则X→Z为F所蕴含。 即:A→BC; 能得出: A→B,A→C;
3、属性集闭包
闭包就是由一个属性直接或间接推导出的所有属性的集合。
例如:f={a->b,b->c,a->d,e->f};由a可直接得到b和d,间接得到c,则a的闭包就是{a,b,c,d};
已知关系R(A1,A2,A3,A4,A5,A6),函数依赖集F为{ (A2,A3)——>A4,A3——>A6,(A2,A5)——>A1 }, 问(A2,A3)关于F的属性闭包为:{A2,A3,A4,A6}; 因为:A2,A3能带到A4,A3能得到A6;
已知关系R(A,B,C,D,E,F,G),函数依赖集F为{ A ——>B,B——>D,AD——>EF,AG——>C}, 问:A关于F的属性闭包为:{A,B,D,E,F}; 因为:A能得到B,B能得到D,AD能得到EF;
4、最小函数依赖集(正则覆盖)
1、定义:
如果函数依赖集F满足以下条件,则称F为一个极小函数依赖集。也称为最小依赖集或最小覆盖。
(1)F中任一函数依赖的右部仅含有一个属性。
(2)F中不存在这样的函数依赖X→A,使得F与F-{X→A}等价。
(3)F中不存在这样的函数依赖X→A,X有真子集Z使得F-{X→A}U{Z→A}与F等价。
2、最小依赖集通用算法:
① 用分解的法则,使F中的任何一个函数依赖的右部仅含有一个属性;
② 去掉多余的函数依赖:从第一个函数依赖X→Y开始将其从F中去掉,然后在剩下的函数依赖中求X的闭包X+,看X+是否包含Y,若是,则去掉X→Y;否则不能去掉,依次做下去。直到找不到冗余的函数依赖;
③ 去掉各依赖左部多余的属性。一个一个地检查函数依赖左部非单个属性的依赖。例如XY→A,若要判Y为多余的,则以X→A代替XY→A是否等价?若A属于(X)+,则Y是多余属性,可以去掉。(以上步骤中,求出关系依赖集F,此时,在F的基础上,求出X或者Y的闭包,是否包含A)
3、最小依赖集案例:
例1:关系模式R(U,F)中,U=ABCDEG,F={B->D,DG->C,BD->E,AG->B,ADG->BC};求F的最小函数依赖集
步骤:
(1)用分解的法则,使F中的任何一个函数依赖的右部仅含有一个属性;得到:F={B->D,DG->C,BD->E,AG->B,ADG->B,ADG->C};
(2)去掉多余的函数依赖:从第一个函数依赖X→Y开始将其从F中去掉,然后在剩下的函数依赖中求X的闭包X+,依次做下去。直到找不到冗余的函数依赖;
① 去掉B->D,此时F={DG->C,BD->E,AG->B,ADG->B,ADG->C},此条件下得出B的闭包 B+ = B;B+不包含D,所以B->D保留。
②去掉DG->C,此时F={B->D,BD->E,AG->B,ADG->B,ADG->C},此时DG闭包DG+ = DG,不包含C,所以不能去掉DG->C.
③ 去掉BD->E,此时F={B->D,DG->C,AG->B,ADG->B,ADG->C},此时闭包BD+ = BD,不包含E,所以不能去掉BD->E,继续保留。
④去掉AG->B,此时F={B->D,DG->C,BD->E,ADG->B,ADG->C};此时AG+ = AG,不包含B,所以不能去掉AG->B,继续保留。
⑤去掉ADG->B,此时F={B->D,DG->C,BD->E,AG->B,ADG->C},此时ADG+ = ADGCBE,包含了B,所以删除ADG->B,不保留。
⑥去掉ADG->C,此时F={B->D,DG->C,BD->E,AG->B},此时ADG+ = ADGCBD,包含了C,所以删除ADG->C,不保留。
综上所得,此时得到F={B->D,DG->C,BD->E,AG->B};
(3)去掉各依赖左部多余的属性。一个一个地检查函数依赖左部非单个属性的依赖。
此时函数依赖左边非单个属性有:DG->C,BD->E,AG->B;所以做如下操作:
①先来看DG->C,判断 D 是否多余,求 DG - D = G 的闭包,此时G的闭包G+ = G,不包含C,保留D。判断 G 是否多余,求 DG - G = D 的闭包,此时D+ = D,不包含C,所以G也不能去掉;
②再来看BD->E,判断 B 是否多余,求 BD - B = D 的闭包,此时D的闭包D+ = D,不含E,保留B。判断 D 是否多余,求 BD - D = B 的闭包,此时B+ = BDE,包含了E,所以去掉D。
③最后再来看 AG->B,判断 A 是否多余,求 AG - A = G 的闭包,G+ = G,不包含B,不能去掉A。判断 G 是否多余,求 AG - G = A 的闭包,A的闭包A+ =A,不含B,不能去掉G,还是AG->B ;
所以最后得出:F的最小函数依赖集是:F={B->D,DG->C,B->E,AG->B};
5、无损连接分解
1)判断表法

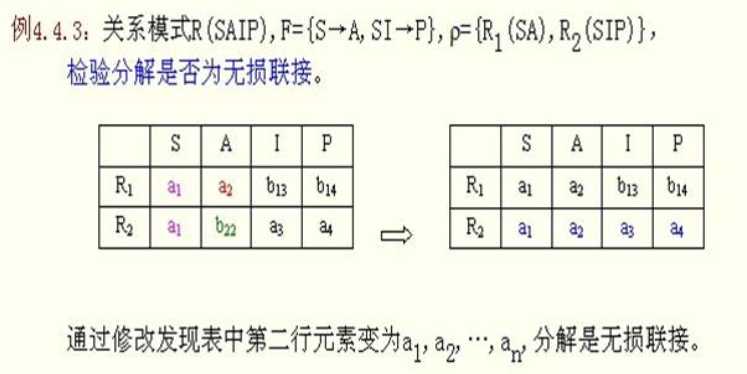
2)无损连接定理

案例(1):关系模式R(SAIP),F={S—>A,SI—>P}; ρ={R1(SA),R2(SIP)}检测分解是否为无损连接?
因为:R1∩R2 = S ;R1—R2 = A; R2—R1 = IP;所以得出:S —>A;或者S —>IP; 而 S —>A 在F={S—>A,SI—>P}中,所以此分解是无损连接。
举例(2):已知R<U,F>,U={A,B,C},F={A→B},如下的两个分解:
① ρ1={AB,BC};
② ρ2={AB,AC};
因为:AB∩BC = B;AB—BC = A;BC—AB = C;得出;B→A,或者 B→A,两个都不包含在F={A→B}中,所以 ρ1 分解是有损的。
因为:AB∩AC = A;AB—AC = B;AC—AB = C;得出:A→B,或者A→C,而A→B包含在F={A→B}中,所以 ρ2 分解是无损的。
6、保持依赖分解

案例(1):关系模式R<U, F>,U={A, B, C, D, E},F={B→A,D→A,A→E,AC→B}则分解ρ={R1(ABCE),R2(CD)}是否满足保持函数依赖。
因为:B→A,A→E,AC→B在R1上成立,D→A在R1和R2上都不成立,因此需做进一步判断。
由于B→A,A→E,AC→B都是被保持的(因为它们的元素都在R1中),因此我们要进一步判断的是D→A是不是也被保持。
①先看R1:因为:result = D;result ∩R1 = ф (空集);所以:t=ф,result=D;
②再看R2:因为:result = D;result ∩R2 = D;D+ = DA; D+ ∩ R2 = D; 所以:t=D,result=D;
一个循环后result未发生变化,因此最后result=D,并未包含A,所以D→A未被保持,该分解不是保持依赖的。
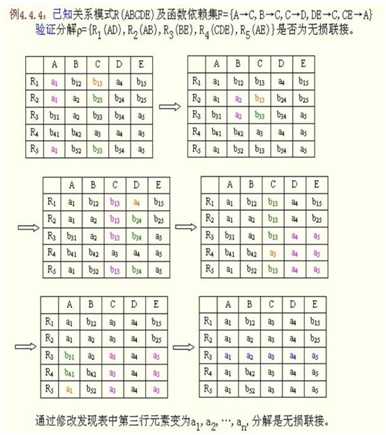
案例(2):关系R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有函数依赖性。
因为:,C→D,DE→C均在R4(CDE)中被保持,而A→C,B→C,CE→A,在R1....R5上都不成立,需要进一步判断。
(1)A→C;
①先看R1:因为:result = A;result ∩R1 = A ; A+ = ACD ; A+ ∩ R1 = AD;所以:t=AD,result=AD; 此时,result改变,则,进入R2;
②再看R2:因为:result = AD;result ∩R2 = ф,最后还是result = AD;
③再看R3:因为:result = AD;result ∩R3 = ф,最后还是result = AD;
④再看R4:因为:result = AD;result ∩R4 = D,D+ = D; D+ ∩ R4= D;最后还是result = AD;
⑤再看R5:因为:result = AD;result ∩R5 = A,最后还是result = AD;
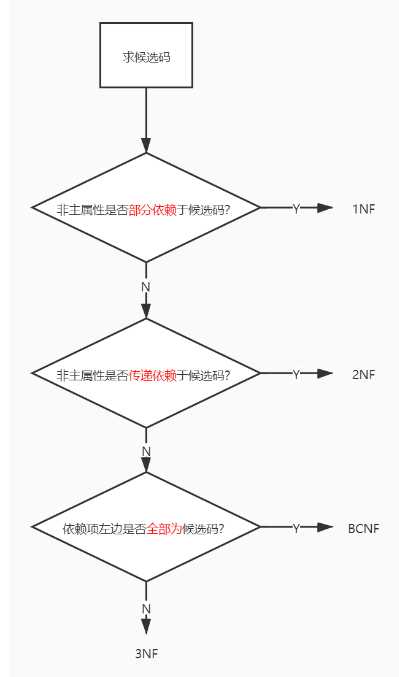
7、范式
(1):1NF:每个分量都是不可再分的数据项(值、原子)。即:属性中,不能存在复合属性 或者 多值属性。
(2):2NF:每一个非主属性 完全函数依赖 于 候选键(码)。注意:这里是码(不是主属性);即:不能存在 非主属性部分函数依赖于码。
(3):3NF:每一个非主属性 都不传递依赖于 码。 即:不能存在非主属性对于码的传递函数依赖。
(4):BCNF:不存在 主属性 对于 码 的 部分函数依赖 与 传递函数依赖。判断方法:箭头左边的必须是候选码(不能只是一个属性,部分码)。
判断范式的方法:
例1:R(A,B,C),F={A->B, B->A, A->C}
L :No,R:C,LR:A,B
计算A+ = ABC ,A 是候选码
计算B+ = ABC,B 是候选码
主属性: A,B ;非主属性: C
1)看非主属性是否部分依赖于主属性,发现没有部分依赖。
2)看非主属性是否传递依赖于主属性,发现 B -> A -> C ,C 传递依赖于 B,但这个传递依赖成立的条件是 A -> B 不成立,否则A -> C 推不出来。故没有部分传递依赖。
3)看所有依赖左边是否全部为候选码,所有依赖左边依次是 A,B,A 全部为 候选码 故为 BCNF 范式。
例2:R(A,B,C,D),F={B->D, D->B, AB->C}
L:A, R:C,LR:B,D
L 一定为主属性,将 L 和 LR 组合为 AB,AD
主属性: A,B,D ;非主属性: C
AB+ = ABCD;AD+ = ABCD;故 AB,AD为候选码。
1)查看部分依赖。 C 完全依赖于 AB,没有部分依赖。
2)查看传递依赖。C直接完全依赖于候选码 AB,没有传递依赖。
3)查看是否全为候选码。所有依赖左边依次是 B,D,AB ,B,D不为 候选码 故为 3NF 范式。
8、模式分解
3NF 分解:
计算最小函数依赖
将最小函数依赖依次分解,得到 3NF 保持函数依赖分解。
将保持依赖分解添加一个候选码到结果中,得到 3NF 无损连接分解。
BCNF 分解:
R(A,B,C,D),F={A->B,C->D}一直找不是候选码的函数依赖项 A->B,将依赖集分解为两部分:
1)AB
2)ACD (B 可由A 推出)
继续分解 ACD。
例: R(A,B,C,D,E,F),F={AE->F,A->B, BC->D, CD->A, CE->F}
L:C,E
R:F
LR:A,B,D
L 一定为主属性,将 L 和 LR 组合为 ACE,BCE,CDE。
主属性: A,B,D ;非主属性: C
ACE+ = ABCDEF;BCE+ = ABCDEF;CDE+ = ABCDEF;故ACE,BCE,CDE为候选码。
将上面的函数依赖依次分解得到:AEF,AB,BCD,CDA,CEF。
得到 3NF 保持函数依赖分解 : AEF,AB,BCD,CDA,CEF
任意添加一个候选码进去(这里选 ACE)。
得到 3NF 无损连接依赖分解 : AEF,AB,BCD,CDA,CEF,ACE
AEF,AB,BCD,CDA,CEF 全部都不是候选码
第一次分解 AE->F:
AEF, 剩下 R=(ABCDE),F={A->B, BC->D, CD->A} (F可以被导出)
第二次分解 A->B:
AB,剩下 R=(ACDE), F={CD->A} (B可以被导出,B 已经不在 R 中了 BC-> D 也就删除了)
第三次分解 CD->A:
CDA,剩下 R=(CDE), F={} (A可以被导出)
CDE为候选码分解停止。
故 BCNF 分解为 AEF,AB,CDA,CDE
以上是关于数据库--关系数据理论的主要内容,如果未能解决你的问题,请参考以下文章