机器学习三 —— K均值算法
Posted xiaoap
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习三 —— K均值算法相关的知识,希望对你有一定的参考价值。
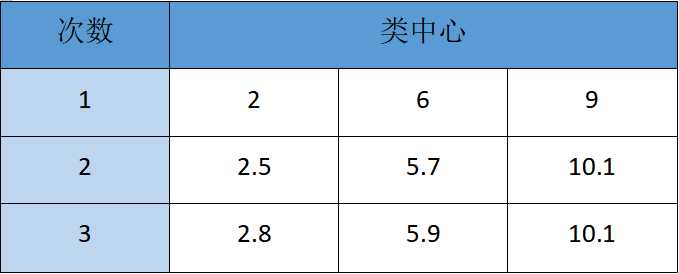
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
这里选了40张牌,随机抽取三张牌并以其各自点数作为类中心,第一次是 2 6 9

每次的分类依据就是点数离那个中心近,近就分类到该分类下。第一次分完类,在计算各分类的中心值(该类所有数字求均值),重新得出三个类中心,第二次分类如下

再重复上面的计算步骤,直到类中心不再变动。具体结果如下表所示:
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
import numpy as np;
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
pl = iris.data[:,2]
n = len(pl) #样本个数
k = 3 #中心个数
dist = np.zeros([n,k+1]) #初始化一个矩阵
center = np.zeros([k])
centerNew = np.zeros([k])
for i in range(k): #避免开头时有一样的中心
for j in range(n):
if pl[j] in center:
continue
else:
center[i] = pl[j]
break
while(True):
for i in range(n):
for j in range(k):
dist[i,j] = np.sqrt((pl[i]-center[j])**2) #计算距离
dist[i,k] = np.argmin(dist[i,:k])
#计算新的中心
for i in range(k):
index = dist[:, k] == i
centerNew[i] = np.mean(pl[index])
#如果前后两次中心相等则跳出,否则继续
if np.all((center == centerNew)):
break
else:
for i in range(k):
center[i] = centerNew[i]
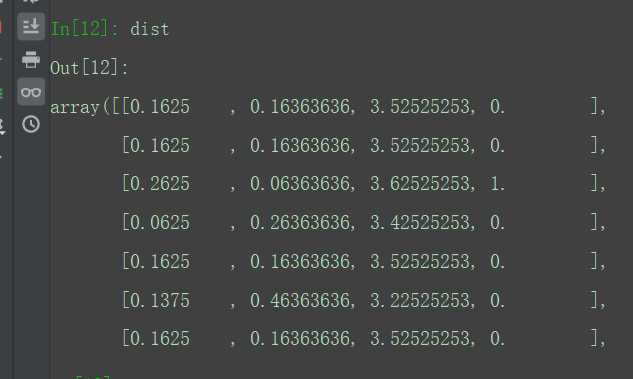
plt.scatter(pl,pl,c=dist[:,k],s=60, cmap=‘rainbow‘)
plt.show()
结果出来后不是很理想,后续再去寻找问题改进,结果如下:
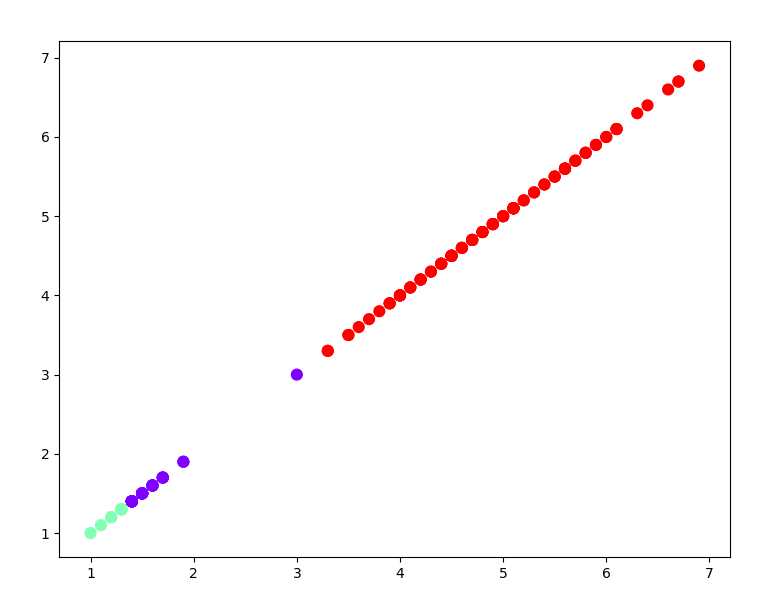
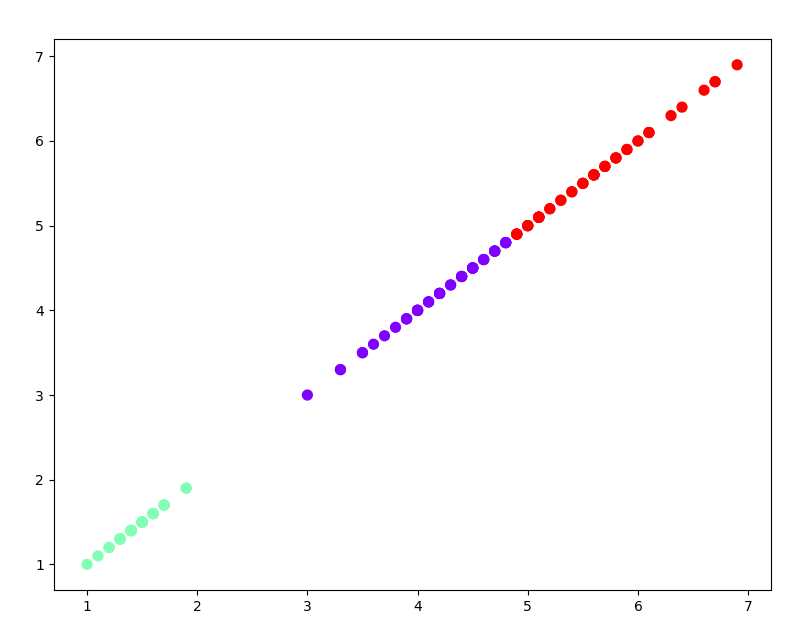
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris = load_iris() pl = iris.data[:,2] x = pl.reshape(-1,1) est = KMeans(n_clusters=3) est.fit(x) y_kmeans = est.predict(x) plt.scatter(x[:,0],x[:,0],c=y_kmeans,s=50, cmap=‘rainbow‘); plt.show()
4). 鸢尾花完整数据做聚类并用散点图显示.
irisData = iris.data KMeans_model = KMeans(n_clusters=3) KMeans_model.fit(irisData) pre = KMeans_model.predict(irisData) plt.scatter(irisData[:,2],irisData[:,3],c=pre, s=50, cmap=‘rainbow‘) plt.show()
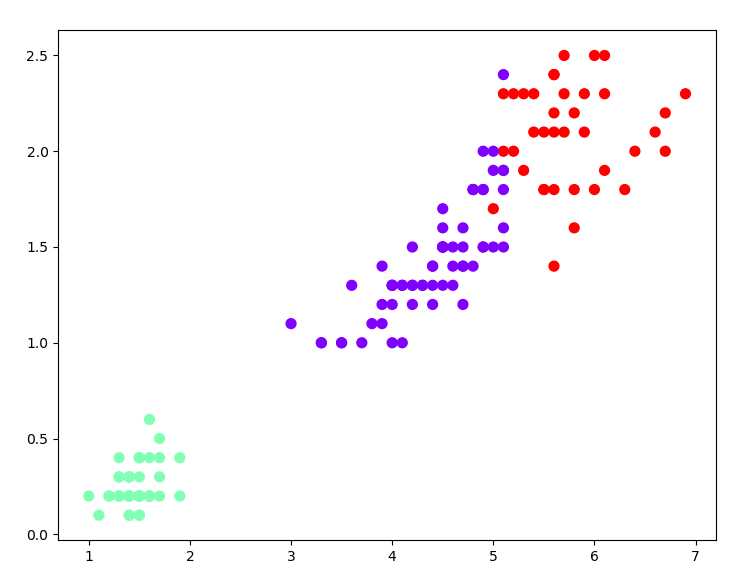
5).想想k均值算法中以用来做什么?
k均值算法是一种无监督的分类算法,主要通过大量的特征数据,来做类别的区分,如上面的题,KMeans算法可以用来区分鸢尾花的种类,在现实生活中,也可以对人的体重身高等数据来划分不同身体状况的人群,高矮胖瘦等,也可以通过文学作品的篇幅来分类短篇、长篇作品。
以上是关于机器学习三 —— K均值算法的主要内容,如果未能解决你的问题,请参考以下文章