机器学习--K均值聚类算法原理方法及代码实现
Posted lsm-boke
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习--K均值聚类算法原理方法及代码实现相关的知识,希望对你有一定的参考价值。
一、K-means算法原理
k-means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含n个d维数据点的数据集X以及要分得的类别K,选取欧式距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即最小化:
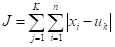
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
二、算法实现一般流程
K-means是一个反复迭代的过程,算法分为四个步骤:
1)选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
2)对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3)更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4)判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
三、算法应用实例--鸢尾花分类问题
1.Iris数据集
Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
代码实现:
import math from collections import defaultdict import numpy as np
dataname = "data.txt"
def loadIRISdata(filename): data = [] with open(filename, mode="r", encoding="utf-8") as rf: for line in rf: if line == ‘ ‘: continue data.append(list(map(float, line.split(" ")))) return data
def generateCenters(data): ‘‘‘求解初始聚类中心‘‘‘ centers = [] ‘‘‘已知维度为4‘‘‘ ‘‘‘分三类,取第0,50,100的三个向量作为分界‘‘‘ centers.append(data[0]) centers.append(data[50]) centers.append(data[100]) return centers
def distance(a ,b): ‘‘‘欧式距离‘‘‘ sum = 0 for i in range(4): sq = (a[i]-b[i])*(a[i]-b[i]) sum += sq return math.sqrt(sum)
def point_avg(points): ‘‘‘对维度求平均值‘‘‘ new_center = [] for i in range(4): sum = 0 for p in points: sum += p[i] new_center.append(float("%.8f" % (sum/float(len(points))))) return new_center def updataCenters(data, assigments): new_means = defaultdict(list) centers = [] for assigment, point in zip(assigments, data): new_means[assigment].append(point) ‘‘‘将同一类的数据进行整合‘‘‘ for i in range(3): points = new_means[i] centers.append(point_avg(points)) return centers
def assignment(data, centers): assignments = [] ‘‘‘对应位置显示对应类群‘‘‘ for point in data: ‘‘‘遍历所有数据‘‘‘ shortest = float(‘inf‘) shortestindex = 0 for i in range(3): ‘‘‘遍历三个中心向量,与哪个类中心欧氏距离最短就将其归为哪类‘‘‘ value = distance(point, centers[i]) if value < shortest: shortest = value shortestindex = i assignments.append(shortestindex) return assignments def kmeans(data): k_data = generateCenters(data) assigments = assignment(data, k_data) old_assigments = None while assigments != old_assigments: new_centers = updataCenters(data, assigments) old_assigments = assigments assigments = assignment(data, new_centers) result = list(zip(assigments, data)) return result
def acc(result): sum = 0 all = 0 for i in range(50): if result[i][0] == 0: sum += 1 all += 1 for i in range(50): if result[i+50][0] == 1: sum += 1 all += 1 for i in range(50): if result[i+100][0] == 2: sum += 1 all += 1 print(‘sum:‘, sum, ‘all:‘, all) return sum, all if __name__ == "__main__": data = loadIRISdata(dataname) result = kmeans(data) for i in range(3): tag = 0 print(‘ ‘) print("第%d类数据有:" % (i+1)) for tuple in range(len(result)): if(result[tuple][0] == i): print(tuple, end=‘ ‘) tag += 1 if tag > 20 : print(‘ ‘) tag = 0 #print(result) print(‘ ‘) sum, all = acc(result) print(‘c-means准确度为:%2f%%‘ % ((sum/all)*100))
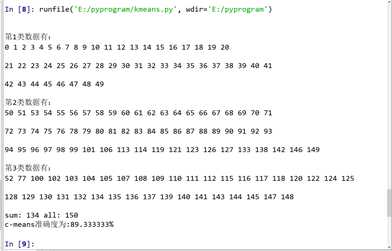
运行结果:
以上是关于机器学习--K均值聚类算法原理方法及代码实现的主要内容,如果未能解决你的问题,请参考以下文章