[论文理解] CBAM: Convolutional Block Attention Module
Posted aoru45
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文理解] CBAM: Convolutional Block Attention Module相关的知识,希望对你有一定的参考价值。
CBAM: Convolutional Block Attention Module
简介
本文利用attention机制,使得针对网络有了更好的特征表示,这种结构通过支路学习到通道间关系的权重和像素间关系的权重,然后乘回到原特征图,使得特征图可以更好的表示。
Convolutional Block Attention Module
这里的结构有点类似与SENet里的支路结构。
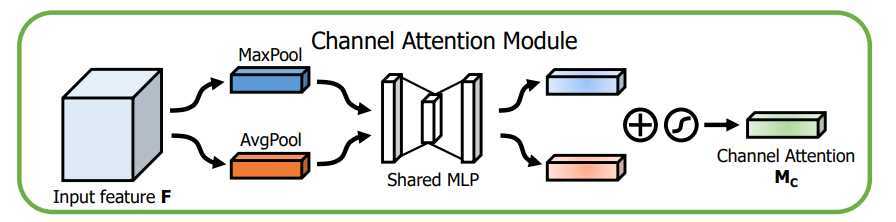
对于Channel attention module,先将原feature map分别做global avg pooling 和global max pooling,然后将两pooling后的向量分别连接一个FC层,之后point-wise相加。激活。
这里用global pooling的作用是捕捉全局特征,因为得到的权重描述的是通道间的关系,所以必须要全局特征才能学习到这种关系。
之所以avg pooling和max pooling一起用,是因为作者发现max pooling能够捕捉特征差异,avg pooling能捕捉一般信息,两者一起用的效果要比单独用的实验结果要好,。
结构如图:
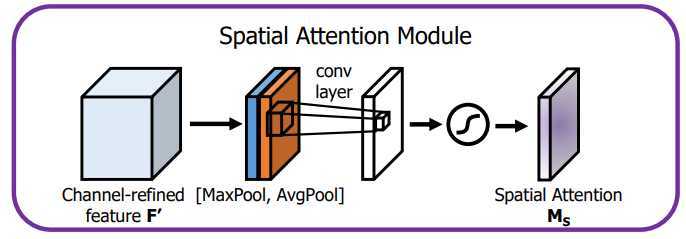
对于Spatial attention module,作者使用了1×1的pooling,与上面一样,使用的是1×1的avg pooling和1×1的max pooling,而没有用1×1卷积,两者concat,紧接着是一层7×7卷积,然后激活。最后输出就是1×h×w。
结构如图:
作者提到了两者的顺序,先做channel attention比先做spatial attention要好很多。
后面作者实验了spatial attention module里1×1conv、1×1pooling的效果,最后发现pooing的效果要比卷积的效果要好,因此上面的结构采用的是pooling而不是卷积结构。
后面就是一些结构了。
几句话简单复现了一下。
'''
@Descripttion: This is Aoru Xue's demo,which is only for reference
@version:
@Author: Aoru Xue
@Date: 2019-09-12 01:24:03
@LastEditors: Aoru Xue
@LastEditTime: 2019-09-12 02:24:25
'''
import torch
import torch.nn as nn
class ChannelAttentionModule(nn.Module):
def __init__(self,size = 128,r = 2):
super(ChannelAttentionModule, self).__init__()
self.max_pooling = nn.MaxPool2d(size)
self.avg_pooling = nn.AvgPool2d(size)
self.fc1 = nn.Linear(64,64//r)
self.fc2 = nn.Linear(64//r,64)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
max_pool = self.max_pooling(x).view(2,64)
max_pool = self.fc1(max_pool)
avg_pool = self.avg_pooling(x).view(2,64)
avg_pool = self.fc1(avg_pool)
t = max_pool + avg_pool
x = self.fc2(t).view(2,64,1,1)
x = self.relu(x)
return x
class SpatialAttentionModule(nn.Module):
def __init__(self,):
super(SpatialAttentionModule, self).__init__()
self.conv7x7 = nn.Conv2d(2,64,kernel_size= 7 , stride=1,padding = 3)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
max_pool = torch.max(x,dim = 1)[0]
avg_pool = torch.mean(x,dim = 1)
x = self.conv7x7(torch.stack([max_pool,avg_pool],dim = 1))
x = self.sigmoid(x)
return x
class ResBlock(nn.Module):
def __init__(self,):
super(ResBlock, self).__init__()
self.channel_module = ChannelAttentionModule(r = 2)
self.spatial_module = SpatialAttentionModule()
def forward(self,x):
c = self.channel_module(x)
x = c*x
s = self.spatial_module(x)
x = s * x
return x
if __name__ == "__main__":
x = torch.randn(2,64,128,128)
net = ResBlock()
print(net(x).size())以上是关于[论文理解] CBAM: Convolutional Block Attention Module的主要内容,如果未能解决你的问题,请参考以下文章
图像中的注意力机制详解(SEBlock | ECABlock | CBAM)
魔改YOLOv5-6.x(中)加入ACON激活函数CBAM和CA注意力机制加权双向特征金字塔BiFPN
CV中的Attention机制易于集成的Convolutional Block Attention Module(CBAM模块)