魔改YOLOv5-6.x(中)加入ACON激活函数CBAM和CA注意力机制加权双向特征金字塔BiFPN
Posted 嗜睡的篠龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了魔改YOLOv5-6.x(中)加入ACON激活函数CBAM和CA注意力机制加权双向特征金字塔BiFPN相关的知识,希望对你有一定的参考价值。
文章目录
前言
【魔改YOLOv5-6.x(上)】:结合轻量化网络Shufflenetv2、Mobilenetv3和Ghostnet
本文使用的YOLOv5版本为v6.1,对YOLOv5-6.x网络结构还不熟悉的同学们,可以移步至:【YOLOv5-6.x】网络模型&源码解析
另外,本文所使用的实验环境为1个GTX 1080 GPU,数据集为VOC2007,超参数为hyp.scratch-low.yaml,训练200个epoch,其他参数均为源码中默认设置的数值。
YOLOv5中修改网络结构的一般步骤:
models/common.py:在common.py文件中,加入要修改的模块代码models/yolo.py:在yolo.py文件内的parse_model函数里添加新模块的名称models/new_model.yaml:在models文件夹下新建模块对应的.yaml文件
一、ACON激活函数
Ma, Ningning, et al. “Activate or not: Learning customized activation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
论文简介
ReLU激活函数在很长一段时间都是最佳的神经网络激活函数,主要是由于其非饱和、稀疏性等优秀的特性,但是它也同样会产生神经元坏死的严重后果。而近年来人们使用NAS搜索技术找到的Swish激活函数效果非常好,但是问题是Swish激活函数是使用NAS技术暴力搜索出来的,我们无法真正解释Swish激活函数效果这么好的真正原因是什么?
在这篇论文中,作者尝试从Swish激活函数和ReLU激活函数的公式出发,挖掘其中的平滑近似原理(Smooth Approximation),并且将这个原理应用到Maxout family激活函数,提出了一种新型的激活函数:ACON family 激活函数。通过大量实验证明,ACON family 激活函数在分类、检测等任务中性能都优于ReLU和Swish激活函数。
ACON family

作者提出一种新颖的Swish函数解释:Swish函数是ReLU函数的平滑近似(Smoth maximum),并基于这个发现,进一步分析ReLU的一般形式Maxout系列激活函数,利用Smoth maximum将Maxout系列扩展得到简单且有效的ACON系列激活函数:ACON-A、ACON-B、ACON-C。
同时提出meta-ACON,动态的学习(自适应)激活函数的线性/非线性,控制网络每一层的非线性程度,显著提高了表现。另外还证明了ACON的参数 P 1 P_1 P1和 P 2 P_2 P2负责控制函数的上下限(这个对最终效果由很大的意义),参数 β \\beta β负责动态的控制激活函数的线性/非线性。
ACON激活函数的性质:
- ACON-A(Swish函数)是ReLU函数的平滑近似(Smoth maximum)
- ACON-C的一阶导数的上下界也是通过 P 1 P_1 P1和 P 2 P_2 P2两个参数来共同决定的,通过学习 P 1 P_1 P1和 P 2 P_2 P2,能获得性能更好的激活函数
- 参数 β \\beta β负责动态的控制激活函数的线性/非线性,这种定制的激活行为有助于提高泛化和传递性能
- meta-ACON激活函数中参数
β
\\beta
β,通过一个小型卷积网络,并通过Sigmoid函数学习得到
YOLOv5中应用
同Ghost模块一样,在最新版本的YOLOv5-6.1源码中,作者已经加入了ACON激活函数,并在utils\\activations.py文件下,给出了ACON激活函数适用于YOLOv5中的源码:
# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------
class AconC(nn.Module):
r""" ACON activation (activate or not).
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1):
super().__init__()
# nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
# 为了减少参数我们在两个中间的channel加了个缩放参数r,默认设置为16
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
# 自适应函数的设计空间包含了layer-wise, channel-wise, pixel-wise这三种空间 分别对应的是层, 通道, 像素
# 这里我们选择了channel-wise 首先分别对H, W维度求均值 然后通过两个卷积层 使得每一个通道所有像素共享一个权重
# 最后由sigmoid激活函数求得beta
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
因此我们直接在models\\common.py中的Conv函数进行替换(替换nn.SiLU())即可:
from utils.activations import MetaAconC
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
# 这里的nn.Identity()不改变input,直接return input
# self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.act = MetaAconC(c1=c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
# 前向加速推理模块
# 用于Model类的fuse函数,融合conv+bn 加速推理 一般用于测试/验证阶段
def forward_fuse(self, x):
return self.act(self.conv(x))
二、注意力机制
CBAM
Woo, Sanghyun, et al. “Cbam: Convolutional block attention module.” Proceedings of the European conference on computer vision (ECCV). 2018.
论文代码
论文简介
作者提出了一种轻量的注意力模块,可以在通道和空间维度上进行 Attention,核心算法其实就是:通道注意力模块(Channel Attention Module,CAM) +空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间上的 Attention,通道上的 Attention 机制在 2017 年的 SENet 就被提出,CBAM中的CAM 与 SENet 相比,只是多了一个并行的 Max Pooling 层。
CBAM注意力机制
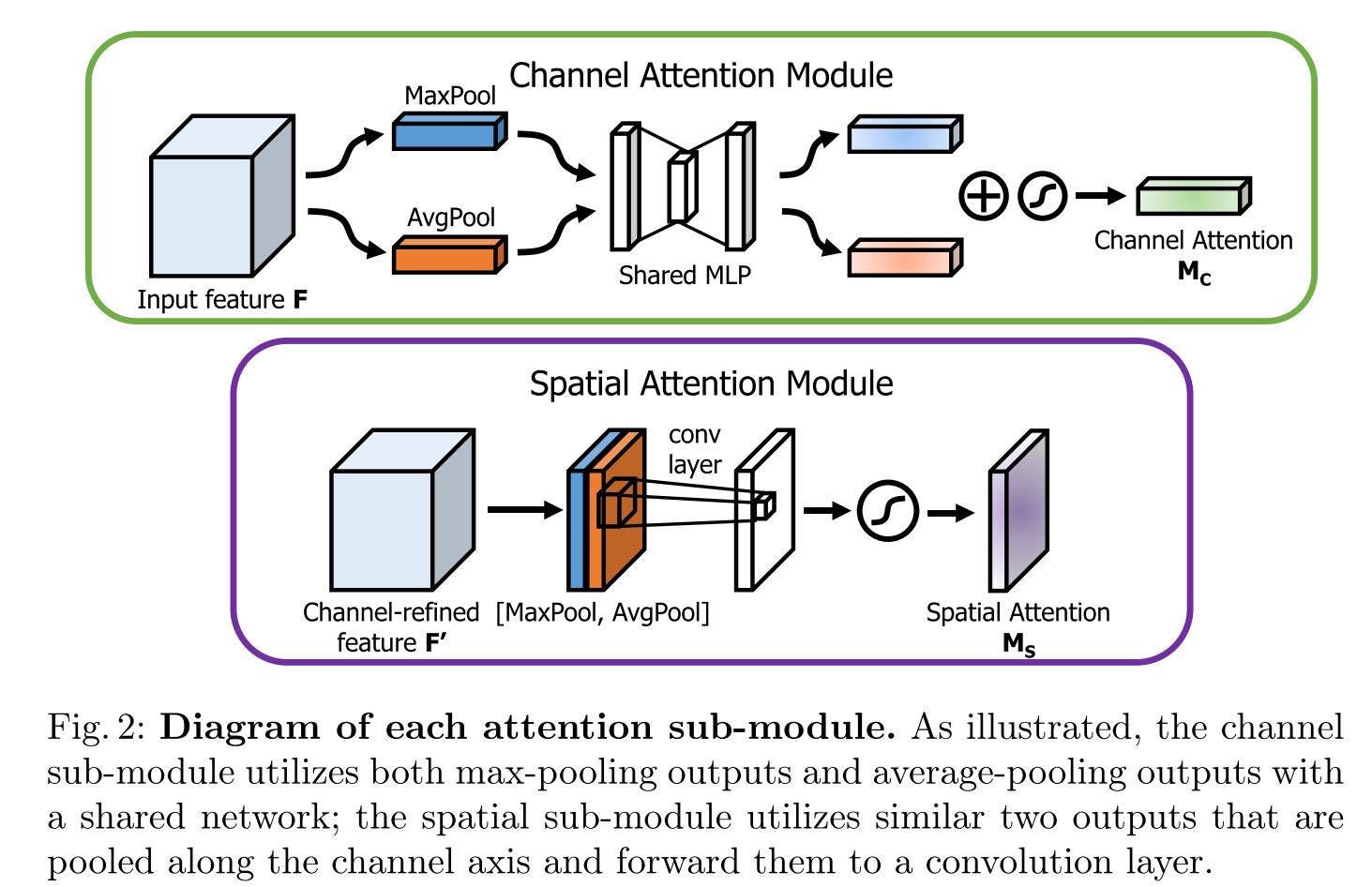
CBAM可以分为channel attention和spatial attention两个模块,至于哪个在前,哪个在后,作者通过实验发现,先channel在spatial效果更好一些:
- Channel Attention:将输入的特征图F(
H
×
W
×
C
H×W×C
H×W×C)分别经过基于width和height(对每一个channel)的Global Max Pooling(GMP 全局最大池化)和Global Average Pooling(GAP 全局平均池化),得到两个
1
×
1
×
C
1×1×C
1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为
C
/
r
C/r
C/r(r为减少率),激活函数为 Relu,第二层神经元个数为
C
C
C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的add操作,再经过sigmoid归一化操作,生成最终的channel attention feature,即
M
c
M_c
Mc
- 在channel attention中,作者对于pooling的使用进行了实验对比,发现avg & max的并行池化的效果要更好,这里也有可能是池化丢失的信息太多,avg&max的并行连接方式比单一的池化丢失的信息更少,所以效果会更好一点
- Spatial Attention:将Channel Attention模块输出的特征图
F
′
F'
F′作为本模块的输入特征图。首先做一个基于channel的GMP和GAP,得到两个
H
×
W
×
1
H×W×1
H×W×1的特征图,然后将这2个特征图基于channel 做concat操作(通道拼接)。然后经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即
H
×
W
×
1
H×W×1
H×W×1。再经过sigmoid生成spatial attention feature,即
M
s
M_s
Ms。最后将
M
s
M_s
Ms和该模块的输入feature做乘法,得到最终生成的特征图
YOLOv5中应用
YOLOv5结合注意力机制有两种策略:
- 注意力机制结合Bottleneck,替换backbone中的所有C3模块
- 在backbone最后单独加入注意力模块
这里展示第一种策略,在介绍CA注意力时,展示第二种策略。另外根据实验结果,第二种策略效果会更好。
- common.py文件修改:直接在最下面加入如下代码
# ---------------------------- CBAM start ---------------------------------
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# in_planes // ratio 这里会出现如下警告:
# UserWarning: __floordiv__ is deprecated(被舍弃了), and its behavior will change in a future version of pytorch.
# It currently rounds toward 0 (like the 'trunc' function NOT 'floor').
# This results in incorrect rounding for negative values.
# To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'),
# or for actual floor division, use torch.div(a, b, rounding_mode='floor').
# kernel = torch.DoubleTensor([*(x[0].shape[2:])]) // torch.DoubleTensor(list((m.output_size,))).squeeze()
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 全局平均池化—>MLP两层卷积
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
# 全局最大池化—>MLP两层卷积
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 基于channel的全局平均池化(channel=1)
avg_out = torch.mean(x, dim=1, keepdim=True)
# 基于channel的全局最大池化(channel=1)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# channel拼接(channel=2)
x = torch.cat([avg_out, max_out], dim=1)
# channel=1
x = self.conv(x)
return self.sigmoid(x)
class CBAMBottleneck(nn.Module):
# ch_in, ch_out, shortcut, groups, expansion, ratio, kernel_size
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, kernel_size=7):
super(CBAMBottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
# 加入CBAM模块
self.channel_attention = ChannelAttention(c2, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 考虑加入CBAM模块的位置:bottleneck模块刚开始时、bottleneck模块中shortcut之前,这里选择在shortcut之前
x2 = self.cv2(self.cv1(x)) # x和x2的channel数相同
# 在bottleneck模块中shortcut之前加入CBAM模块
out = self.channel_attention(x2) * x2
# print('outchannels:'.format(out.shape))
out = self.spatial_attention(out) * out
return x + out if self.add else out
class C3CBAM(C3):
# C3 module with CBAMBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e) # 引入C3(父类)的属性
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut) for _ in range(n)))
# ----------------------------- CBAM end ----------------------------------
-
yolo.py文件修改:在yolo.py的
parse_model函数中,加入CBAMBottleneck, C3CBAM两个模块 -
新建yaml文件:在model文件下新建
yolov5-cbam.yaml文件,复制以下代码即可
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
# 第二种加入方法 全部替换 C3 模块
backbone:
# [from, number, module, args]
[[-1, 1, Conv,以上是关于魔改YOLOv5-6.x(中)加入ACON激活函数CBAM和CA注意力机制加权双向特征金字塔BiFPN的主要内容,如果未能解决你的问题,请参考以下文章