hive中的文件格式的简介
Posted xuziyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive中的文件格式的简介相关的知识,希望对你有一定的参考价值。
【hive中的file_format】
- SEQUENCEFILE:生产中绝对不会用,k-v格式,比源文本格式占用磁盘更多
- TEXTFILE:生产中用的多,行式存储
- RCFILE:生产中用的少,行列混合存储,OCR是他得升级版
- ORC:生产中最常用,列式存储
- PARQUET:生产中最常用,列式存储
- AVRO:生产中几乎不用,不用考虑
- JSONFILE:生产中几乎不用,不用考虑
- INPUTFORMAT:生产中几乎不用,不用考虑
【注意】hive默认的文件格式是TextFile,可通过set hive.default.fileformat 进行配置

【行式存储与列式存储】
-
行式存储与列式存储数据物理底层存储区别
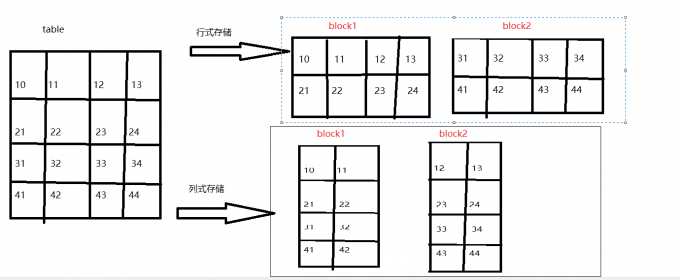
【结论:由上图可知】
- 行式存储一定会把同一行数据存到同一个块中,在select查询的时候,是对所有字段的查询,不可以单独查询某一行
- 列式存储同一列数据一定是存储到同一个块中,换句话说就是不同的列可以放到不同块中,在进行select查询的时候可以单独查询某一列。
【优缺点】
-
列式存储
- 优点:当查询某个或者某几个字段的时候,只需要查看存储这几个字段的这几个block就可以了,大大的减少了数据的查询范围,提高了查询效率
- 缺点:当进行全字段查询的时候,数据需要重组,比单独查一行要慢
-
行式存储
- 优点:全字段查询比较快
- 缺点:当查询一张表里的几个字段的时候,底层依旧是读取所有的字段,这样查询效率降低,并且会造成不必要的资源浪费,而且,生产中很少会出现需要全字段查询的场景
【hive文件格式配置实现以及对比】
- 创建原始表默认TEXTFILE
- CREATE EXTERNAL TABLE g6_access (
- cdn string,
- region string,
- level string,
- time string,
- ip string,
- domain string,
- url string,
- traffic bigint)
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY ‘ ‘
- LOCATION ‘/g6/hadoop/access/clear/test/‘;
- 导入测试数据
- [[email protected] data]$ ll
- -rw-r--r-- 1 hadoop hadoop 68051224 Apr 17 17:37 part-r-00000
- [[email protected] data]$ hadoop fs -put part-r-00000 /g6/hadoop/access/clear/test/
- 通过hue查看数据的大小 64.9MB

- 创建以 SEQUENCEFILE格式储存的表g6_access_seq,并使用g6_access中的数据
- create table g6_access_seq
- stored as SEQUENCEFILE
- as select * from g6_access ;
- 查看数据大小 71.8MB

- 结论:比默认的TEXTFILE格式的文件还要大,生产上基本上是不会用的
- 创建RCFILE数据存储格式表,,并使用g6_access中的数据
- create table g6_access_rc
- stored as RCFILE
- as select * from g6_access;
- 查看数据大小 61.6MB

- 结论:存储减少了3M左右,微不足道,读写性能也没有什么优势,生产也没有用他的理由
- 创建ORCFILE数据存储格式表,,并使用g6_access中的数据,默认是使用zlib压缩,支持zlib和snappy
- create table g6_access_orc
- stored as ORC
- as select * from g6_access;
- 查看数据大小 17.0MB

- 创建ORCFILE数据存储格式表,并使用g6_access中的数据
- create table g6_access_orc_none
- stored as ORC tblproperties ("orc.compress"="NONE")
- as select * from g6_access;
- 查看数据大小 51.5MB

- 创建PARQUET数据存储格式表,不使用压缩,并使用g6_access中的数据
- create table g6_access_par
- stored as PARQUET
- as select * from g6_access;
- 结论:ORC文件不压缩,比源文件少了10多MB,ORC文件采用默认压缩,文件只有源文件的四分之一
- 查看数据大小 58.3MB
- 创建PARQUET数据存储格式表,设置使用gzip压缩格式,并使用g6_access中的数据
- set parquet.compression=gzip;
- create table g6_access_par_zip
- stored as PARQUET
- as select * from g6_access;

- 结论:parquet格式文件大小是源文件的1/4左右。生产上也是好的选择
【读取数据量对比】
- 直接执行 select 查询,观察日志 尾部HDFS Read: 190XXX ,就可知道读取数据量了
以上是关于hive中的文件格式的简介的主要内容,如果未能解决你的问题,请参考以下文章