快速了解HIVE文件存储格式
Posted 真香IT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速了解HIVE文件存储格式相关的知识,希望对你有一定的参考价值。
快速了解HIVE文件存储格式
Hive支持的存储数的格式主要有:
TEXTFILE行式存储) 、
SEQUENCEFILE(行式存储)、
ORC 列式存储)、
PARQUET 列式存储)。

一 列式存储和行式存储
a 、行式存储:
一行数据接着一行数据做存储,一行数据中的多个字段的值都是物理相邻的。
特点:
-
一行相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录
-
这种存储格式比较方便进行INSERT/UPDATE操作
b 、列式存储:
一列数据单独存储,多行数据的相同列的值,在物理存储上是相邻的
特点:
-
分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
-
同一列中的数据属于同一类型,不需要针对不同数据类型频繁切换压缩算法,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。

二 TEXTFILE格式
hive默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。

三 Sequence File
Sequence File是Hadoop API提供的一种二进制文件支持。这种二进制文件直接将<key, value>键值对序列化到文件中。

a 、Sequence File优缺点
优点
-
二进制格式存储,比文本文件更紧凑。
-
支持不同级别压缩 基于Record或Block压缩)。
-
文件可以拆分和并行处理,适用于MapReduce。
局限性
-
二进制格式文件不方便查看。
-
特定于hadoop,只有Java API可用于与之进行交互。尚未提供多语言支持。
b、Sequence File格式
Hadoop Sequence File 是一个由二进制键/值对组成的。根据压缩类型,有3种不同的Sequence File格式:未压缩格式、record压缩格式、block压缩格式。
Sequence File由一个header和一个或多个record组成。以上三种格式均使用相同的header结构,如下所示:

前3个字节为SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号 例如SEQ4或SEQ6)。Header中其他也包括key、value class名字、 压缩细节、metadata、Sync marker。Sync Marker同步标记,用于可以读取任意位置的数据。
1、未压缩格式

未压缩的Sequence File文件由header、record、sync三个部分组成。其中record包含了4个部分:record length 记录长度)、key length 键长)、key、value。
每隔几个record 100字节左右)就有一个同步标记。
2、基于record压缩格式

基于record压缩的Sequence File文件由header、record、sync三个部分组成。其中record包含了4个部分:record length 记录长度)、key length 键长)、key、compressed value 被压缩的值)。
每隔几个record 100字节左右)就有一个同步标记。
3、基于block压缩格式

基于block压缩的Sequence File文件由header、block、sync三个部分组成。
block指的是record block,可以理解为多个record记录组成的块。注意,这个block和HDFS中分块存储的block 128M)是不同的概念。
Block中包括:record条数、压缩的key长度、压缩的keys、压缩的value长度、压缩的values。每隔一个block就有一个同步标记。
block压缩比record压缩提供更好的压缩率。使用Sequence File时,通常首选块压缩。
四 Avro File

a 、简介
-
Apache Avro是与语言无关的序列化系统,由Hadoop创始人 Doug Cutting开发
-
Avro是基于行的存储格式,它在每个文件中都包含JSON格式的schema定义,从而提高了互操作性并允许schema的变化 删除列、添加列)。 除了支持可切分以外,还支持块压缩。
-
Avro是一种自描述格式,它将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。
-
Avro可以进行快速序列化,生成的序列化数据也比较小。
b、应用场景
-
适合于一次性需要将大量的列 数据比较宽)、写入频繁的场景
-
随着更多存储格式的发展,常用于Kafka和Druid中
c、结构

直接将一行数据序列化在一个block中
d、优点
-
Avro是与语言无关的数据序列化系统。
-
Avro将schema存储在header中,数据是自描述的。
-
序列化和反序列化速度很快。
-
Avro文件是可切分的、可压缩的,非常适合在Hadoop生态系统中进行数据存储。
e、缺点
-
如果我们只需要对数据文件中的少数列进行操作,行式存储效率较低。例如:我们读取15列中的2列数据,基于行式存储就需要读取数百万行的15列。而列式存储就会比行式存储方式高效
-
列式存储因为是将同一列 类)的数据存储在一起,压缩率要比方式存储高
五 ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是IndexData,Row Data,StripeFooter:

-
一个orc文件可以分为若干个Stripe
-
一个stripe可以分为三个部分
-
indexData:某些列的索引数据
-
rowData :真正的数据存储
-
StripFooter:stripe的元数据信息
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个stripe的元数据信息
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
六 PARQUET格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
七 Apache Arrow新一代的存储格式

a、Arrow简介
- Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。Apache Arrow在2016年2月17日作为顶级Apache项目引入。
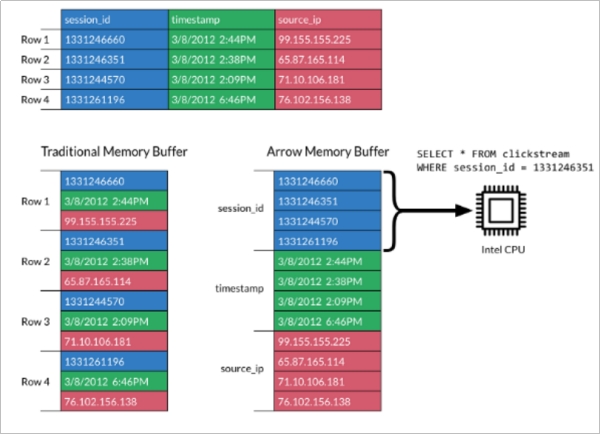
-
Apache Arrow发展非常迅速,并且在未来会有更好的发展空间。 它可以在系统之间进行高效且快速的数据交换,而无需进行序列化,而这些成本已与其他系统 例如Thrift,Avro和Protoco* Buffers)相关联。
-
每一个系统实现,它的方法 method)都有自己的内存存储格式,在开发中,70%-80%的时间浪费在了序列化和反序列化上。
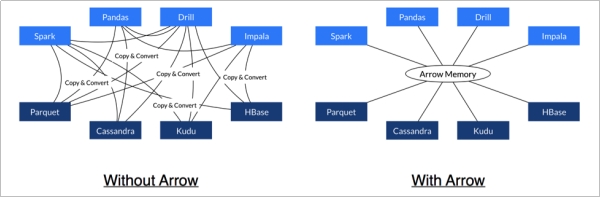
- Arrow促进了许多组件之间的通信。 例如,使用Python pandas)读取复杂的文件并将其转换为Spark DataFrame。

b、Arrow是如何提升数据移动性能的
-
利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数。
-
无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析。
-
Arrow的设计针对嵌套结构化数据 例如在Impala或Spark Data框架中)的分析性能进行了优化。
八 BigData File Viewer工具
a、介绍
- 一个跨平台 Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如Parquet,ORC,AVRO等。支持本地文件系统,HDFS,AWS S3等。

github地址:https://github.com/Eugene-Mark/bigdata-file-viewer
b、功能清单
-
打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等。
-
将二进制格式的数据转换为文本格式的数据,例如CSV
-
支持复杂的数据类型,例如数组,映射,结构等
-
支持Windows,MAC和Linux等多种平台
-
代码可扩展以涉及其他数据格式
以上是关于快速了解HIVE文件存储格式的主要内容,如果未能解决你的问题,请参考以下文章