环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
Posted 翟中龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一相关的知识,希望对你有一定的参考价值。
一、前言
Hadoop简介
Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰富,包括ZooKeeper,Pig,Chukwa,Hive,Hbase,Mahout,flume等.接下来我们使用的是Hive
Hive简介
Hive 是一个基于 Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。 它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。我们可以把 Hive 中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在 HDFS 中的。 Hive 经过对语句进行解析和转换,最终生成一系列基于 hadoop 的 map/reduce 任务,通过执行这些任务完成数据处理。
Presto简介
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
二、环境准备
Hadoop2.X
apache-hive-2.1.0
presto-server-0.156.tar.gz
mysql5.7
三、速度测试
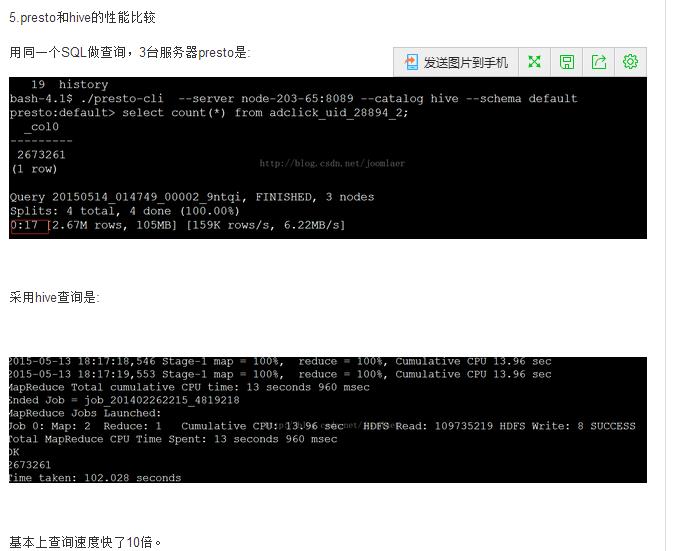
四、本机服务器准备
虚拟机使用linux的centos
Hadoop 192.168.209.142,192.168.209.140
hive 192.168.209.140
presto 192.168.209.140
mysql 10.0.0.7
五、环境搭建
1.Hadoop环境搭建<略>
2.Hive环境搭建
解压Hive文件
[root@HDP134 ~]# tar -zxvf /home/hive/apache-hive-2.1.0-bin.tar.gz
配置hive
[root@HDP134 ~]# vi /etc/profile
因为HIVE用到了Hadoop需要在最下边加上hadoop和Hive的路径
#Hadoop
export HADOOP_INSTALL=/opt/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export HADOOP_HOME=$HADOOP_INSTALL
#Hive
export HIVE_HOME=/home/hive/apache-hive-2.1.0-bin
export PATH=$PATH:$HIVE_HOME/bin
保存退出之后进入配置文件,复制并生命名hive-env.sh,hive-site.xml
[root@HDP134 ~]# cd /home/hive/apache-hive-2.1.0-bin/conf
[root@HDP134 ~]# cp hive-env.sh.template hive-env.sh
[root@HDP134 ~]# cp hive-default.xml.template hive-site.xml
配置hive-site.xml
替换hive-site.xml文件中的 ${system:java.io.tmpdir} 和 ${system:user.name}
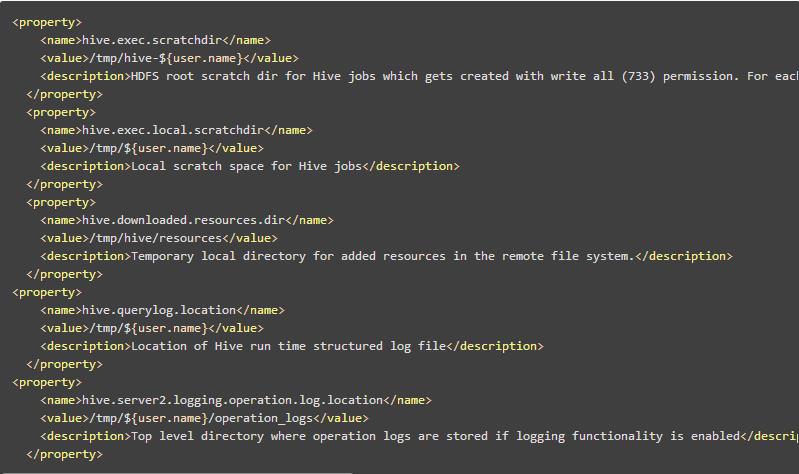
默认情况下, Hive的元数据保存在了内嵌的 derby 数据库里, 但一般情况下生产环境使用 MySQL 来存放 Hive 元数据。
继续修改Hive-site.xml配置Mysql
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property>
保存退出
由于Hive要使用Hadoop,所以以下所有操作均是在hadoop用户下操作先为Hadoop赋值目录权限使用如下命令
chown -R hadoop:hadoop /home/hive
切换用户

在 Hive 中创建表之前需要使用以下 HDFS 命令创建 /tmp 和 /user/hive/warehouse (hive-site.xml 配置文件中属性项 hive.metastore.warehouse.dir 的默认值) 目录并给它们赋写权限。
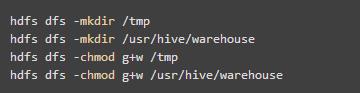
至此基本配置已经完成,可以运行Hive了,运行Hive之前需要先开启Hadoop.

从 Hive 2.1 版本开始, 我们需要先运行 schematool 命令来执行初始化操作。

执行成功之后,可以查看自己的Mysql,我刚配置的mysql库为Hive,我们可以进行MYSQL执行show databases;查看是否已经创建hive数据库
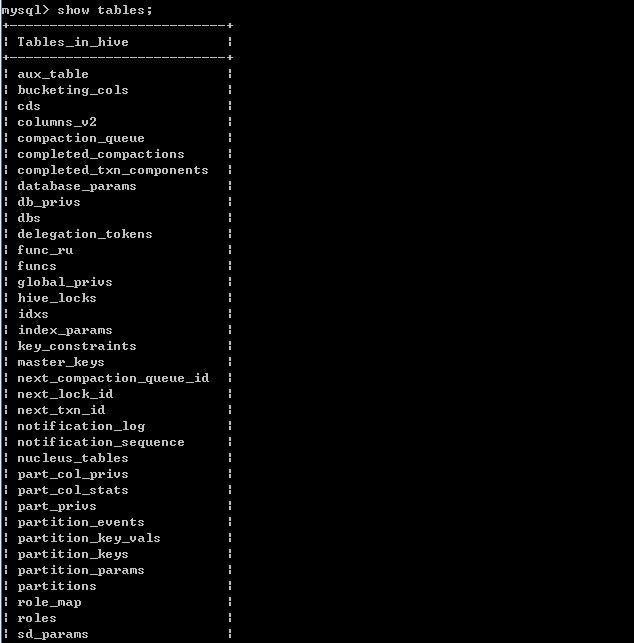
我们可以看到已经自动生成了很多表。说明Hive已成功连接Mysql
我们来运行一下Hive,直接输入hive命令,即可(一定要是在hadoop下操作,不然会报一些无权限的一大堆错误)
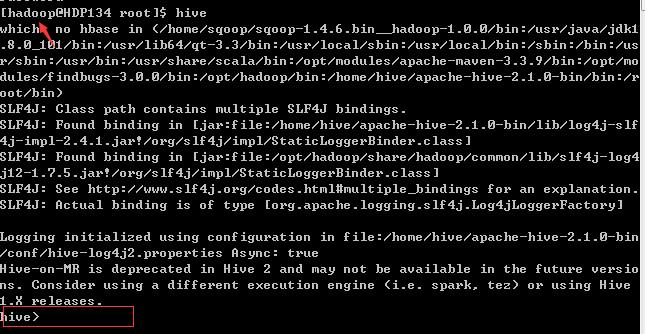
hive已启动,我们可以执行一下show tables;查看一下;
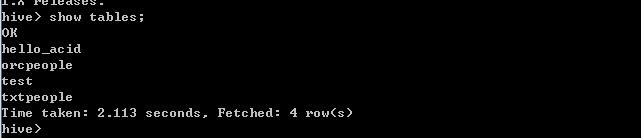
至此hive已安装完成,后边会说到如何创建一个orcfile格式的文件。
3.Presto安装
首先解压下载好的tar.gz包

配置presto
进入etc文件,我们总共需要创建并配置5个文件

除去hadoop那个文件夹,另外的5个下边一一说明
node.properties:每个节点的环境配置
jvm.config:jvm 参数
config.properties:配置 Presto Server 参数
log.properties:配置日志等级
Catalog Properties:Catalog 的配置
1>node.properties配置

节点配置node.id=1
切记:每个节点不能重复我本地把协调和生产节点部署到了一起
2>config.properties

discover.uri是服务地址,http://HDP134:8080是我192.168.209.140的映射
3>catalog hive.properties的配置

connector.name是连接器,我们就用Hive-cdh5
4>jvm.config配置
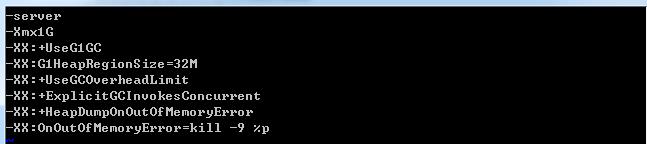
这个可以根据自己的机器配置进行相应调整
5>log.properties配置

配置完成之后,可以运行presto服务了,前提是要先为hadoop赋值目录权限,使用如下命令
chown -R hadoop:hadoop /home/presto
presto服务的启动方式有两种,第一种是strat后台运行看不到日志输出 ,run前台运行,可在前台看到打印日志,建议前期使用run进行前台运行

同样的,要使用hadoop用户启动服务
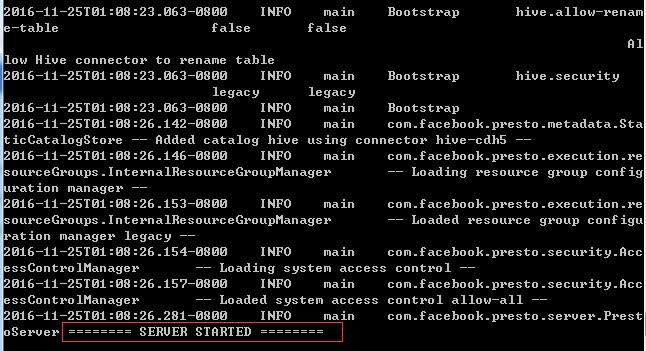
当出现这样的关键词时,恭喜搭建完成
接下来可以测试一下,我们使用一个工具presto-cli-0.90-executable.jar 下载之后,重命名为presto-cli
启动Hive服务
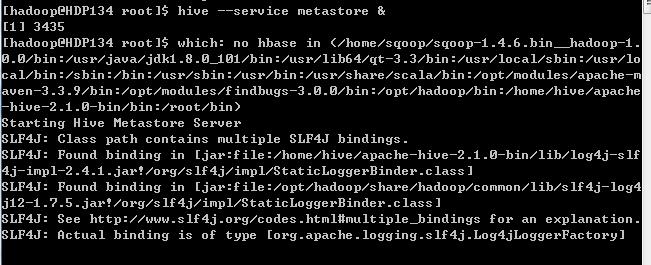
Presto客户端连接

连接Hive库,并进入如上命令行,可以执行一下show tables;进行测试
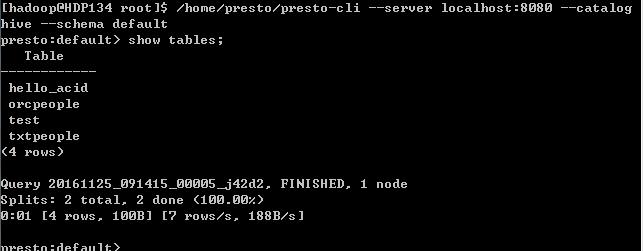
可以显示出hive的所有表,表示presto连接Hive成功
今天就先写到这里,接下来会写创建一个orcfile的几种方法,包括从txtfile转成orcfile,另一种是通过jdbc直接生成orcfile。
以上纯属自己的理解以及本地部署的过程,如果有什么地方有误敬请谅解!
以上是关于环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一的主要内容,如果未能解决你的问题,请参考以下文章
大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
Mac下hadoop,hive, hbase,spark单机环境搭建